






有了这项新技术,要让新垣结衣跟你表白比修图更简单
自从 DeepFake 技术被用在小电影后,这种 AI 换脸术一次次成为舆论焦点,从之前的「朱茵变杨幂」,到最近 Facebook CEO 扎克伯格被恶搞,这种技术一直在不断进化。

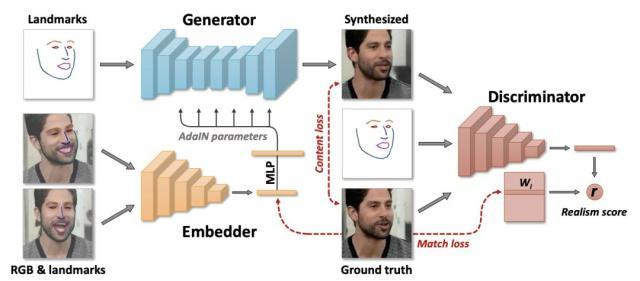
最近伦敦帝国理工学院和英国三星人工智能研究中心展示了一项的新技术,只需要一张照片和音频文件,就能生成一个人唱歌和说话的视频。
研究人员将爱因斯坦的照片,和一段不属于他的音频结合,很快爱因斯坦的一段全新演讲就完成了,从视频中可以看到爱因斯坦的嘴型会随着录音内容而变化。

或者让帝俄时代尼古拉二世时的神秘主义者拉斯普京,唱起碧昂丝的 Halo,毫无违和感。

除了让嘴型对上,这项技术还能让能根据音频的语气音调,来调整人物的表情,高兴、愤怒、忧伤……这让合成的视频更加逼真。

也就是说,只要一张照片和音频,你就能让新垣结衣喊出你的名字,含情脉脉地跟你表白。

但比起过去看到的很多换脸视频,这些合成视频的逼真度还是稍逊一筹。但要考虑到只需要一张照片和录音就能合成,已经很不错了,这也再度降低了这种合成视频的制作门槛。
这可以说是之前三星另一项技术的升级版,三星不久前成功地开发出了一个「人像照变动态表情包」的 AI 系统,只需要一张肖像照片或画像就能能合成动图,比如让蒙娜丽莎做出不同的表情。

据研究人员介绍,AI 在经过大量人物照片和视频的训练后,能高效地找到与系统学习的脸部相对应的部分,针对照片人脸中眼睛、鼻子和嘴巴等关键部位进行调整,让照片动起来。
如果说上述这些 DeepFake 技术还是有不少破绽,那么最近斯坦福等几所高校发布的一项新研究就已经能够以假乱真了。
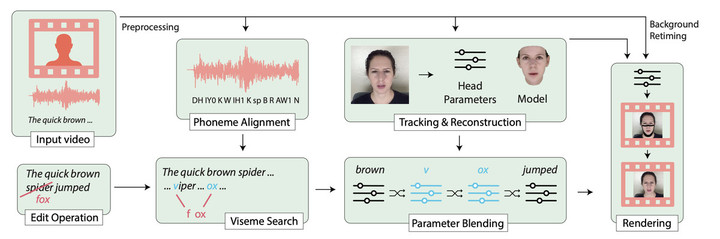
只要输入任意文本,就能让视频中的演讲者说出对应的话,还能修改原视频的语句,比如将电视台主持人报道的「苹果股价收盘于191.45美元」的数字改为「182.25美元」。

尽管这两个词的发音和口型完全不同,但几乎看不出修改痕迹。研究者经过调查发现,59.6%的受试者认为被修改过的视频是真的,这项技术成功骗过了大部分人的眼睛。
当然,相比起之前三星的两项技术,这种视频的制作流程也要复杂得多,涉及到视频和文本要对齐、3D人脸追踪和重构、唇形搜索等多个技术,一段 1 小时的视频需要 42 小时合成。
2017 年多名好莱坞女星的脸被换到成人网站的小电影上,DeepFake 技术从此「一战成名」,也打开了潘多拉魔盒,现在 DeepFake 技术开始引发新的争议。

▲ 盖尔·加朵的脸「移植」到一位色情电影演员身上
最近美国众议院议长南希·佩洛西、Facebook CEO 扎克伯格相继成为了 DeepFake 技术的受害者,「扎克伯格」在 Instagram 控诉自家公司,南希·佩洛西在演讲中语无伦次,让更多人开始担心这种虚假视频对社交平台的影响。

当合成这种视频像修图一样简单时,是否会在社交网络乃至更多互联网空间上引发混乱?
在针对这种新技术的法律法规还没完善之前,或许需要更强大的技术来鉴别这种视频。可据 DeepTrace 平台统计,2018 年,全球涉及 GAN 生成图像和视频的论文多达 902 篇,而研究如何识别合成图像和视频的论文只有 25 篇。
看起来,没什么能阻挡 DeepFake 技术的发展了。本来就是真假难辨的网络世界,正在变得越来越不可信。
题图来自:《逃避可耻但有用》





