






面壁智能完成新一轮数亿元融资,发布性能小钢炮 MiniCPM 第二弹
以小博大的励志故事不只发生在创业历史上,也发生在端侧大模型上。
今年 2 月份,面壁智能正式发布了 2B 旗舰端侧大模型面壁 MiniCPM,不仅超越了来自「欧洲版 OpenAI」的性能标杆之作,同时整体领先于 Google Gemma 2B 量级,还越级比肩 7B、13B 量级模型,如 Llama2-13B 等。
近日,面壁智能也完成新一轮数亿元融资,由春华创投、华为哈勃领投,北京市人工智能产业投资基金等跟投,知乎作为战略股东持续跟投支持,致力于加快推动大模型高效训练、快步应用落地。

今天端侧大模型面壁 MiniCPM 小钢炮乘胜追击,迎来了第二弹的四连发,主打的就是「小而强,小而全」。
其中,MiniCPM-V2.0 多模态模型显著增强了 OCR 能力,刷新开源模型最佳 OCR 表现,通用场景文字比肩 Gemini-Pro、超越全系 13B 量级模型。
在评估大模型幻觉的 Object HalBench 榜单中,MiniCPM-V2.0 与 GPT-4V 的表现几乎持平。
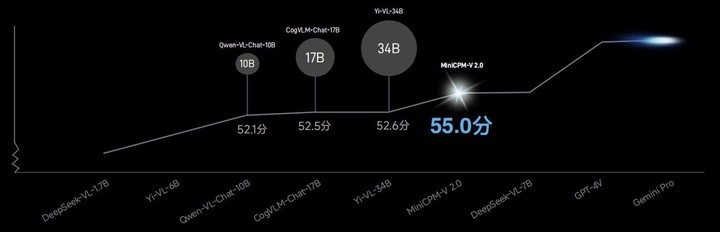
在综合 11 个主流评测基准的 OpenCompass 榜单中,MiniCPM-V2.0 多模态模型通用能力以 55.0 的得分越级超越 Qwen-VL-Chat-10B、CogVLM-Chat-17B、Yi-VL-34B 等量级更大的模型。
在官方给出的演示案例中,当被要求详细描述同一张图片的场景时,GPT-4V 给出的回复出现了 6 处幻觉,而 MiniCPM-V2.0 仅存在 3 处。

此外,MiniCPM-V2.0 还与清华大学展开深度合作,共同探索清华大学博物馆镇馆之宝——清华简。
得益于强悍的多模态识别与推理能力,无论是简单字「可」的识别还是复杂字「我」的识别,MiniCPM-V2.0 都能轻松应对。
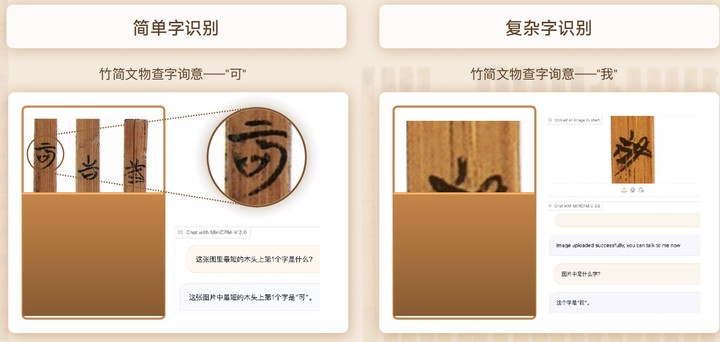
在与同类中文标杆多模态大模型的较量中,MiniCPM-V2.0 的识别准确率更是遥遥领先。
精准细节的识别对图片的清晰度提出更高要求,而传统大模型通常只能处理 448×448 像素小图,信息一旦被压缩,模型便难以读取。
但这可难不倒 MiniCPM-V2.0,在官方的演示案例中,面对寻常的一张城市街道场景图片,MiniCPM-V2.0 一眼就能捕捉关键信息,甚至连肉眼都未能察觉的「Family Mart」也能被轻易捕捉。

长图包含了丰富的文本信息,多模态模型识别长图时往往力不从心 ,但 MiniCPM-V 2.0 却能稳抓长图重点信息。

从 448×448 像素,到 180 万高清大图,甚至 1:9 极限宽高比(448 * 4032),MiniCPM-V 2.0 都能做到无损识别。
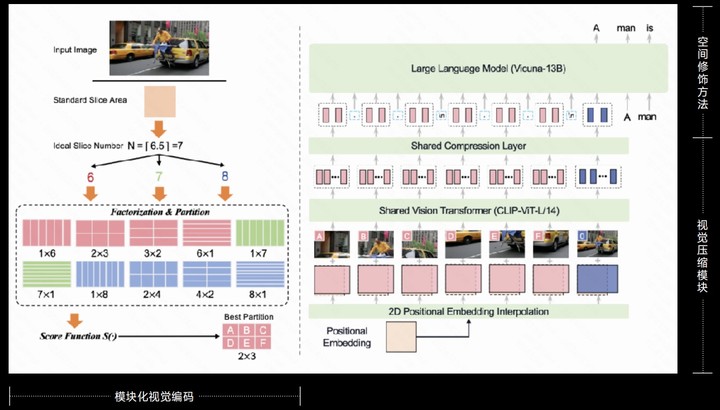
据了解,MiniCPM-V 2.0 高清图像高效编码的背后其实是用到了独家技术 LLaVA-UHD。
- 模块化视觉编码:原始分辨率图像划分为可变大小切片,无需像素填充或图像变形实现对原始分辨率的完全适应性。
- 视觉压缩模块:使用共享感知器重采样层压缩图像切片的视觉 tokens,不管分辨率多少 token 数量都可负担,计算量更低
- 空间修饰方法:使用自然语言符号的简单模式,有效告知图像切片的相对位置。
在中⽂ OCR 能⼒上,MiniCPM-V 2.0 同样显著超越 GPT-4V。对比 GPT-4V 的「爱莫能助」,精准识别图片的它更显难能可贵。
而这一能力的背后得益于跨模态跨语言泛化技术的加持,其能够解决中文领域缺乏高质量、大规模多模态数据的挑战。
长文本处理的能力一直是衡量模型的重要标准。
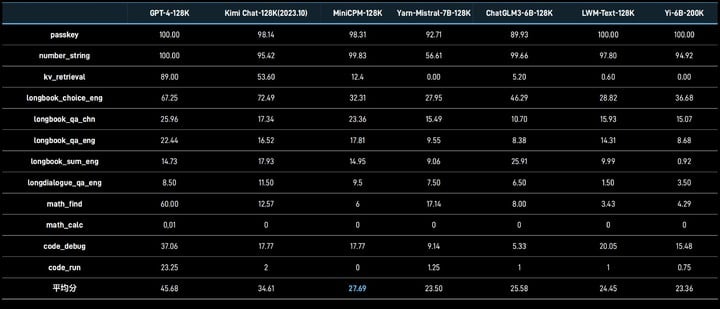
虽然 128K 长文本能力已经不是什么新鲜事,但对于只有 2B 的 MiniCPM-2B-128K,这绝对是一件值得夸奖的事情。
最小的 128K 长文本、MiniCPM-2B-128K 长文本模型,将原有的 4K 上下文窗口扩展到了 128K,在 InfiniteBench 榜单超越 Yarn-Mistral-7B-128K 等一众 7B 量级模型。
通过引入 MoE 架构,新发布的 MiniCPM-MoE-8x2B MoE 性能平均提⾼4.5%,超越了全系 7B 量级模型,及 LlaMA234B 等更大模型,而推理成本仅为 Gemma-7B 的 69.7%。
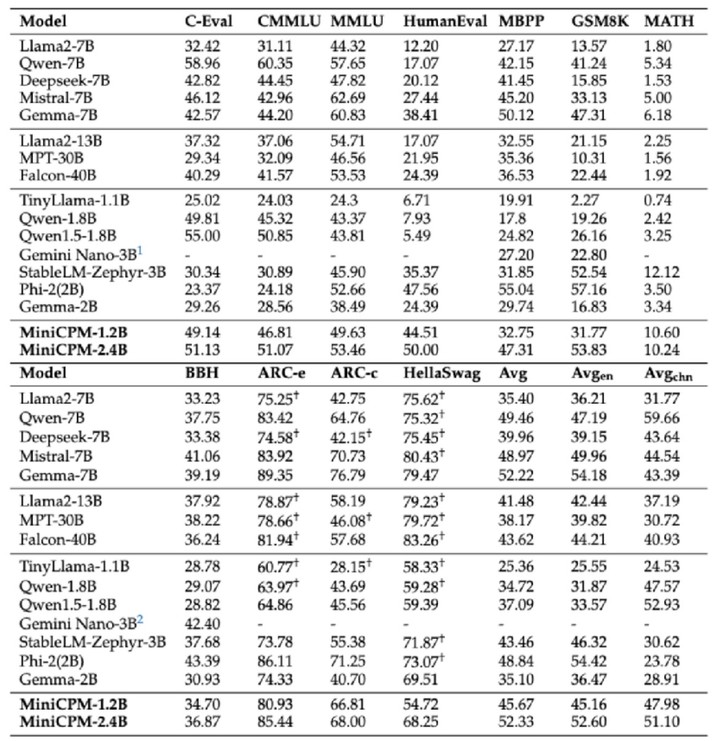
MiniCPM-1.2B 则证明了「小」和「强」并非鱼和熊掌不可兼得。
虽然直接参数减少一半,但 MiniCPM-1.2B 仍保持上一代 2.4B 模型 87% 的综合性能,在多个公开权威测试榜单上,1.2B 模型非常能打,取得了综合性能超过 Qwen 1.8B、Llama 2-7B 甚至 Llama 2-13B 的优异成绩。
在 iPhone 15 手机上对 MiniCPM-1.2B 模型的录屏演示,推理速度提升 38%。达到了每秒 25 token/s,是人说话速度的 15~25 倍,同时内存减少 51.9%,成本下降 60%,实现模型更小,但使用场景却大大增多了。
在一众追求大参数模型的征途中,面壁智能选择了一条与众不同的技术路径——尽可能研发体积更小、性能更强的模型。
而面壁 MiniCPM 小钢炮的出色表现,充分证明了「小」与「强」、「小」与「全」并不是互斥的属性,而是可以和谐共存的。我们也期待,未来能有更多这样的模型出现。





