






零一万物发布千亿参数模型 Yi-Large,李开复:中国大模型赶上美国,立志比肩 GPT-5
时隔一年,李开复带着「零一万物」再次出圈。

去年 5 月,零一万物成立,6 个月后就发布了旗下首款中英双语大模型 Yi 系列。从一开始,李开复就定下了一个宏伟且艰难的目标:「成为 World’s No.1」。
打一出生就是「当红辣子鸡」的零一万物也依靠大厂背景团队、优异模型表现,达到了 10 亿美元的估值。
今天,它们又带来了第二款产品:Yi-Large 闭源模型。
进击全球 SOTA 大模型
去年 11 月,零一万物所发布的 Yi-34B 以开源社区「甜点级」尺寸就在 Hugging Face 榜单中,超越了 Llama2-70B、Falcon-180B 等大几倍的模型,成为当时世界范围内开源最强基础模型之一。
半年后,零一万物正式发布千亿参数规模的 Yi-Large,在第三方权威评测中,零一万物 Yi 模型在全球头部大模型的中英文双语 PK 上表现出色。
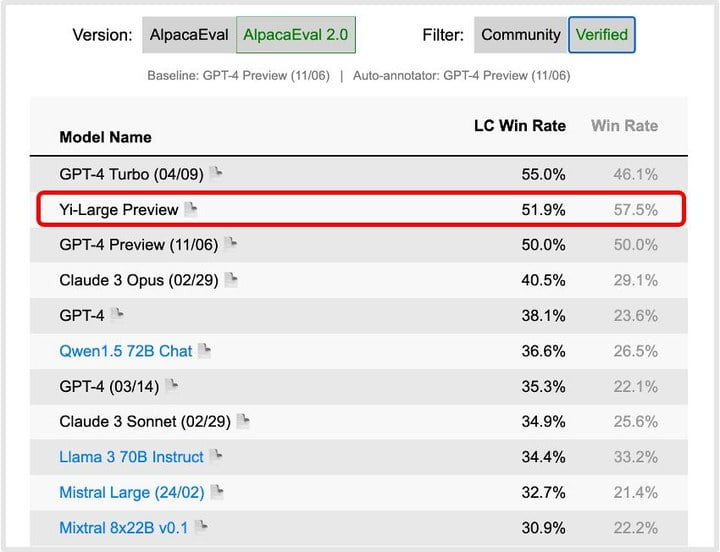
最新出炉的斯坦福评测机构 AlpacaEval 2.0 经官方认证的模型排行榜上,Yi-Large 模型的英语能力主要指标 LC Win Rate(控制回复的长度) 排到了世界第二,仅次于 GPT-4 Turbo,Win Rate 更排到了世界第一。
此前国内模型中仅有 Yi 和 Qwen 曾经登上此榜单的前 20。
大模型用起来聪明的一个重要前提,是它得清楚你在说什么。
国外的模型表现优秀,但都是基于英语语境,而诞生在本土的国产大模型,天生就对中文理解有得天独厚的优势。
在中文能力方面,SuperCLUE 更新的四月基准表现中,Yi-Large 也位列国产大模型之首,Yi-Large 的综合中英双语能力皆展现了卓越的性能。
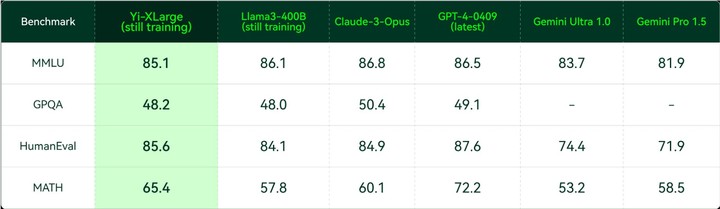
在更全面的大模型综合能力评测中,Yi-Large 多数指标超越 GPT4、Claude3、Google Gemini 1.5 等同级模型,达到首位。在通用能力、代码生成、数学推理、指令遵循方面都取得了优于全球领跑者的成绩,稳稳跻身世界范围内的第一梯队。
随着各家大模型能力进入到力求对标 GPT4 的新阶段,大模型评测的重点也开始由简单的通用能力转向数学、代码等复杂推理能力。
在针对代码生成能力的 HumanEval、针对数学推理能力的 GSM-8K和 MATH、以及针对领域专家能力的 GPQA 等评测集上,Yi-Large 也取得了耀眼的成绩。

此外,从行业落地的角度来看,理解人类指令、对齐人类偏好已经成为大模型不可或缺的能力,指令遵循(Instruction Following)相关评测也越发受到全球大模型企业重视。
斯坦福开源评测项目 AlpacaEval 和伯克利 LM-SYS 推出的 MT-bench 是两组英文指令遵循评测集,AlignBench 则是由清华大学的团队推出的中文对齐评测基准。
在中外权威指令遵循评测集中,Yi-Large 的表现均优于国际前五大模型。
发布会上,李开复还宣布,零一万物已启动下一代 Yi-XLarge MoE 模型训练,将冲击 GPT-5 的性能与创新性。
同时,零一万物也在考虑一些非常复杂的议题,李开复总结了三个重点:
- 一方面,要预备技术的进步,我们能力所及产生什么样的模型;
- 第二,怎么把推理成本做到最低,让我们点燃普惠点;
- 第三,还有传统的 PMF,找到用户需求。
李开复说,这些考量是他们在硅谷公司一般没有看到的:
这是我们独特的方法,也是中国独角兽的机会。
Yi-1.5 全面升级,API 平台全球首发
此次发布会上,零一万物 Yi 系列开源模型也迎来全面升级,Yi-1.5 分为 34B、9B、6B 三个版本,且提供了 Yi-1.5-Chat 微调模型可供开发者选择。
从评测数据来看,Yi-1.5 系列延续了 Yi 系列开源模型的出色表现,数学逻辑、代码能力全面增强的同时,语言能力方面也保持了原先的高水准。
经过微调后的 Yi-1.5-6B/9B/34B-Chat 在数学推理、代码能力、指令遵循等方面更上一层楼。
Yi-1.5-6B/9B-Chat 在 GSM-8K 和 MATH 等数学能力评测集、HumanEval 和 MBPP 等代码能力评测集上的表现远同参数量级模型,也优于近期发布的 Llama-3-8B-Instruct。
在 MT-Bench、AlignBench、AlpacaEval 上的得分在同参数量级模型中也处于领先位置。
去年零一万物选择以开源首发 Yi 系列模型,其优异的性能受到国际开发者的高度认可。
Yi 开源版本 2023 年 11 月上线首月,便占据开源社区近 5 成热门模型排行,发布一个月后 Yi-34B 被 Nvidia 大模型 Playground 收录。

在大模型的开发和产品的落地等问题上,李开复也有着自己的解题思路。
在接受 APPSO 采访时,李开复说:
我们是务实的 AGI 信仰者,我们一定要用最少的芯片,最低的成本训练出我们能训练最好的模型。同时我们会不断的去摸索,找 TC-PMF。国内的初创公司,相对硅谷公司的差异,我们能够仰望星空,但也能脚踏实地。
零一万物不会用纯大力出奇迹的唯一思维,追求能不能用一百亿美金,一千亿美金。OPEN AI 有资格尝试这条道路,但这不是他们要走的道路,当然也不会花时间来预测 AGI 的点燃点,但是他很确定地告诉大家,跟他们相关度更高的是 AI 普惠点。
今天,零一万物同时宣布,面向国内市场一次性发布了包含 Yi-Large、Yi-Large-Turbo、Yi-Medium、Yi-Medium-200K、Yi-Vision、Yi-Spark 等多款模型 API 接口,Yi API Platform 英文站同步对全球开发者开放试用申请。

其中,千亿参数规模的 Yi-Large API 具备超强文本生成及推理性能,适用于复杂推理、预测,深度内容创作等场景;
Yi-Large-Turbo API 则根据性能和推理速度、成本,进行了平衡性高精度调优,适用于全场景、高品质的推理及文本生成等场景。
Yi-Medium API 优势在于指令遵循能力,适用于常规场景下的聊天、对话、翻译等场景;
如果需要超长内容文档相关应用,也可以选用 Yi-Medium-200K API,一次性可解读 20 万字的文本;
Yi-Vision API 具备高性能图片理解、分析能力,可服务基于图片的聊天、分析等场景;
Yi-Spark API 则聚焦轻量化极速响应,适用于轻量化数学分析、代码生成、文本聊天等场景。

更重要的是,现在已经有了落地的应用,针对胰腺肿瘤患者设计的「小胰宝」就是其中之一。
小胰宝 AI 小助手可以 7×24 小时为患者介绍综合治疗知识。
这一助手背后的技术支持正是零一万物的 Yi 大模型。使用 Yi API 调用 AI 大模型后,小胰宝突破了胰腺肿瘤治疗信息壁垒,可将胰腺癌治疗路线图和治疗方案精准且系统性地呈现给胰腺肿瘤病友。
目前,该公益项目已经帮助了 3000 多位胰腺肿瘤病友。
一站式工作平台
今天的发布会,也同时介绍了零一万物近期上线的一站式 AI 工作站「万知」。
根据官方介绍,万知是一个专门为中国用户量身打造的一站式 AI 工作平台,可以做会议纪要、周报、写作助手、解读财报、论文、做 PPT,中英双语且完全免费。
目前,用户可以通过官网和微信小程序「万知 AI」登录体验。
发布会上万知官方举了一个非常实际的例子:
你刚到公司楼下,突然被领导要求做一个会议展示,但是电脑不在身边,现在通过万知,在手机上输入你想演示的主题,然后等你从电梯到工位的两分钟里,PPT 已经在万知网页端做好了,之后你只需要做一些简单的文字、配图和修改,就能直接使用。
除此之外,万知还有许多其他的功能。
首先是文档阅读能力,万知 AI 助手能够快速阅读和理解大量文档内容,包括长文档和复杂的财务数据。它能够在几秒钟内提炼出关键信息,并支持中英双语阅读。
其次在通用问答场景中,万知也展现出了不俗的产品性能,能够快速地给出恰当的答案,和专业快速的反馈。
另外,万知 AI 助手不仅支持文本输出,还能以表格、公式、代码等多种形式展现信息,使工作汇报和生活规划更加清晰明了。
最后,万知 AI 助手能够实时访问互联网信息,确保用户获取的数据和见解是最新和最准确的。
根据万知团队的研究观察,使用万知之后的个人工作效率平均有五成以上的提升,尤其在知识检索、文档构思撰写等方面节约时间显著。
目前,万知 AI 助手对用户完全免费开放。
万知官方说,类似的大模型的应用,在今年肯定会在国内成为一个重要的落地点。
李开复也提到,今年会是 AI 生产力工具的元年,因为有些领域今年就会爆发。
他觉得 AI-Frist 的真实价值,就是谁会打造一个 AI 抖音,AI 微信,AI 淘宝?零一万物希望他们有可能作为这样一个点燃者。

不过,整个 AI 的普惠点一定不是同时来到,而且有些领域的应用要求会很高。
比如现在做的生产力工具,最终这个生产力工具产生的内容,还是用户负责。所以如果里面有一些错误不完美,需要微调,甚至有些少量的幻觉,是由用户最后决定是否可以修改,所以用户的指标就是我能不能比没有这个工具,产生更好的内容在更快的时间。
李开复说 TC-PMF 其实已经达到了,但还可以更好,所以今年在生产力工具肯定会发生。
目前零一万物海外生产力应用总用户接近千万,今年 ToC 单一产品收入达 1 亿元人民币。
李开复透露:
我们 ROI 还是在 1 左右。所以这样的结果至少从国内大模型公司来看是非常有优势的。

国内大模型领域陷入混战的 2023 年初,各式各样的评测榜单铺天盖地,跻身各大榜单 TOP 的模型不在少数。
在 AI 1.0 时代,人工智能还未展现出高泛化性和涌现能力,针对头部客户做私有化部署的模式成为主流,但时间已经证明,偏项目制的重交付模式所带来的营收增长存在上限,其可持续性挑战严峻。
如今我们正处在 AI 2.0 时代,人工智能进入了一个新的发展阶段,和 1.0 相比,AI 2.0 标志着从基于规则的自动化处理向深度学习和自主学习能力的飞跃。
以此看来,AI 领域的「百团大战」,只会愈演愈烈。
从去年开始,越来越多的国产大模型激烈的竞争中脱颖而出,还在全球知名榜单中取得了不俗的成绩。
今年,行业会进入更为现实的商业落地阶段,用户都会按照应用侧所展现的能力,用脚投票。如何基于基座模型能力,尽可能提升应用效果,是追赶 TC-PMF 的重要课题。
李开复表示:
一年前,中国大模型感觉太落后(于美国)了。但今天我们非常自豪的说,我们狂奔了一年,在模型方面至少赶上了美国最顶尖、一年前发布的(大模型)产品,当然以后还要继续努力。但是,我们对未来会需要有一个沉淀和展望,不能只是拼命狂奔。
在长江后浪推前浪的 AI 时代,对于用户来说最大的意义莫过于,在厂家的竞争中知道 AI,了解 AI,使用 AI,甚至把它带到工作、学习和生活中。
而这,也是 AI 技术的初心和归宿。
*付立群对本文亦有贡献





