






字节发布豆包大模型家族,一块钱生成三本《三国演义》,价格比行业便宜 99%
一块钱买得到什么?
在今天上午召开的 2024 季春季火山引擎 Force 原动力大会上,火山引擎总裁谭待给出了一个意料之外的答案。
一元钱就能买到豆包主力模型的 125 万 tokens,大约是 200 万个汉字,相当于三本《三国演义》。
价格战开卷!字节发布豆包大模型
大模型场景落地的关键挑战在于模型效果、推理成本以及落地难度。
为了帮助企业解决好这些挑战,用更好的模型、更低的成本和更易落地的方案帮助企业做好 AI 转型,火山引擎今天正式推出新一代的全栈 AI 服务。
好的技术一定是在大规模的运用,在大量调用的情况下不断打磨才能形成的。
一年前,原名为「云雀」的豆包大模型成为国内首批通过算法备案的大模型之一。
经过一年的迭代发展,现在豆包大模型目前日均处理 1200 亿 tokens 文本,生成超过 3000 万张图片。

从今天开始,豆包大模型将正式通过火山引擎对外提供服务。
本次发布的模型家族包括豆包通用模型 pro、通用模型 lite、角色扮演模型、语音识别模型、语音合成模型、文生图模型等多款模型。
其中豆包大模型 Pro 是豆包模型的最强代表,在理解生成逻辑和记忆等多个维度上都有非常出色的性能,支持 128K 上下文窗口,能够帮助用户快速理解耳环总结高难度的长文本内容。
在某些场景里,对于延时和成本敏感的客户来说,豆包通用模型 lite 则是更好的选择。
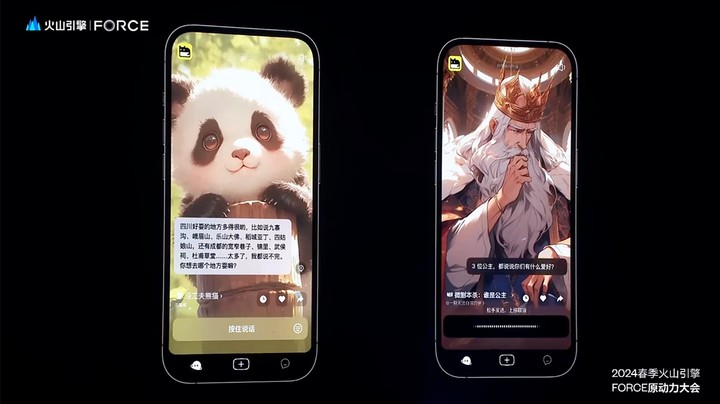
得益于角色扮演模型的加持,无论是扮演四川话的老师,还是推动剧本杀的故事演绎,现场的实际演示都显得游刃有余。
语音是与 AI 交互过程中的重要一环。
语音识别模型和语音合成模型能够准确识别用户的内容、语种和语境,并且通过对音色、语气和语调的学习,可以让大模型表达出真实的感情,让 AI 实现仿若真人般的交流。
大的使用量,才能打磨出好模型,也能大幅降低模型推理的单位成本。火山引擎今天直接化身「价格屠夫」,给大模型市场带来了亿点点震撼。
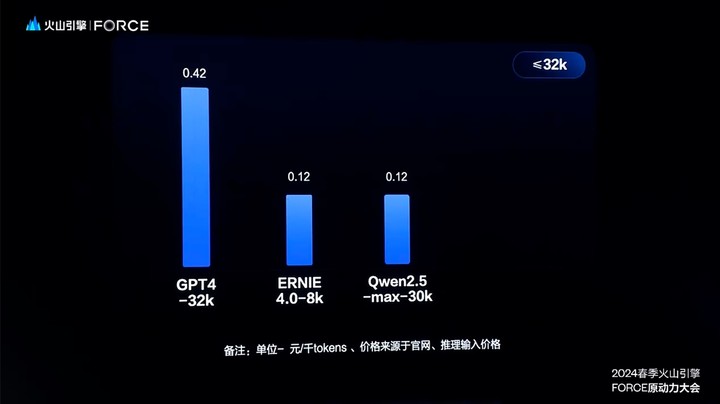
市面上同规格模型的定价一般为 0.12元/千 Tokens,而豆包通用模型 pro-32k 模型推理输入价格仅为 0.0008 元/千Tokens,比行业价格低 99.3%。
又或者,豆包通用模型 pro-128k 模型的输入价格为 0.005 元/千Tokens,比行业价格低 95.8%,真正做到了「从分到厘」的价格内卷。
另外,为了帮助企业更好地落地应用大模型,谭待也宣布推出火山方舟 2.0 平台并发布三个大模型插件:
- 联网插件:从全网的数据中搜索出相关的数据信息
- 内容插件:提供丰富的视频和图文内容
- 知识库插件:支持专有数据的精调,从而尽可能降低 AI 幻觉

应用为本,落地才是王道
通过 AI 原生的开发平台,我们有机会让每一个人都成为 AI 应用的开发者。
在发布会现场,谭待掷地有声地作出了如上判断。作为新一代 AI 应用搭建平台,无论用户是否具有编程基础,都可以在扣子上快速搭建基于模型的各类 bot。
并且,用户还能将 bot 发布到各种社交平台、通讯软件或部署到网站等其他渠道。
发布会的开场演示了一位五年级小朋友的 AI bot,它通过利用在学校学到的语文知识,打造了一个堪称英语外教的 AI bot。
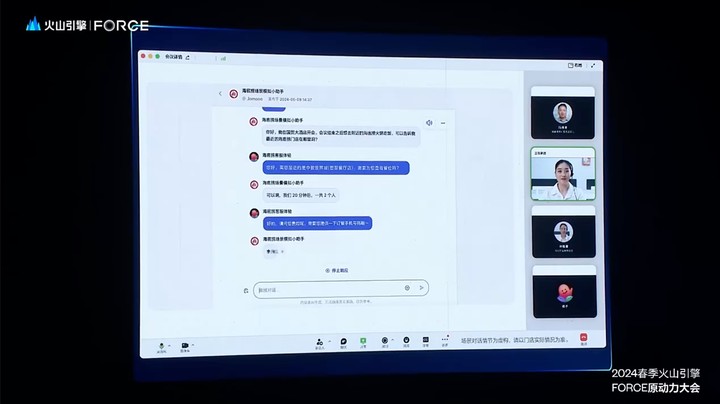
而在对应用场景能力要求更高的企业环境中,海底捞使用扣子模拟顾客对话演练,帮助客服小姐姐提高服务水平。
超级猩猩使用扣子帮助用户懂得更好的健身;招商银行基于扣子搭建了推荐餐饮优惠门店的掌上生活优惠 bot 以及分析市场行情的财富看点……
扣子创建的 bot 支持文字、图片、语音、视频、GUI 卡片等多种模态的混合交互,用户甚至可以像和真人聊天一样跟 bot 进行语音交流,他永远会以最智能也最自然的方式回应用户的每一个请求。
另外,火山引擎还正式发布了扣子专业版——火山引擎根据企业需求,以扣子平台为基础做进一步的封装,支持许多高级的特性。

在过往的十多年里,最懂移动互联网时代的字节跳动似乎总能做一个产品火一个,悄然成为如今的庞然巨兽。
而本次发布会最让人印象深刻的,也莫过于字节跳动如何理解大模型时代下的产品应用与开发。
产品和战略副总裁朱骏表示,比起在服务器端跑的代码,更重要的是要创造出合适的产品形态和自然的交互方式,以满足用户的实际需求,让用户真正愿意使用这些产品。
在发布会现场,朱骏透露了豆包名字的来由。
看似和 AI 扯不上太多关系的「豆包」实则在最初起名时,首先确定下来的通用原则便是简单、好读、好记。
与此同时,为了拉近产品与用户之间的距离,他们内部也为豆包这类产品定义了三个产品设计原则:拟人化、离用户近,嵌入用户的使用环境、个性化。

在过去的一年里,字节跳动在大模型应用的形态上做了很多的探索,而他最大的感受是跟 AI 时代之前相比,做应用既有共性,也有很大的差别。
那共性是什么呢?人的本质的需求其实没有变化。比方说想要快速的、方便的获取信息的需求没有变化,在工作当中要给自己提效……
在他看来,以往做产品相对比较简单,因为至少底下的技术是成熟的,是稳定的,所以你只要发挥你的同理心,去想用户的需求是什么,但大模型时代却又截然不同。
它新的难度就是不仅要考虑大模型此时此刻能干啥,可能更重要的是要去猜测 3 个月、 6 个月、两年以后能够实现什么样的新的用户场景。
所以这是一个新的挑战,也是要在动态的技术演进下,不断的去预测下一个产品的 PMF。
以 AI 搜索引擎为例,朱骏透露在去年上半年评测搜索的任务,往往 10 道题错 6 道,这意味着搜索这个应用场景是完全不成立,但随着模型能力的进化,如今 AI 搜索任务时至今日至少达到可用的程度。

这种从无到有,从可用到优化的转变,不仅仅是技术层面的突破,更是对用户需求深刻洞察的成果。
根据麦肯锡的报告,到 2030 年,大模型推动的全球经济增量将达到 49 万亿元人民币,其中中国部分的经济增量将达到 14 万亿人民币。
庞大的经济增量既包括大模型对现有工作效率的提升,也包括新技术所带的新场景和新业态。字节跳动的探索,是 AI 应用落地的一个缩影,也同样是整个行业需要思考的共同课题。
而这也正是谭待在本场发布会反复强调的一点,好的模型一定要让每一个人,每一家企业都用起来。





