






斯坦福团队抄袭清华系大模型实锤,作者深夜道歉,中国大模型已经无法被忽视
前段时间,斯坦福大学人工智能研究院(Stanford HAI)发布了一份报告,表示美国在大模型领域遥遥领先。报告指出,2023 年 61 个著名的人工智能模型来自美国的机构,远远超过欧盟的 21 个和中国的 15 个。
OpenAI 早期投资人Vinod Khosla 去年还曾在 X 发文称,美国的开源模型都会被中国抄袭。
然而,一直被认为在「追赶美国」的国产大模型现在却成了被抄袭的对象,而这个抄袭的 AI 团队,正是来自发布上述报告的斯坦福大学。
斯坦福 AI 团队主导的 Llama3-V 开源模型,被揪出涉嫌抄袭国内清华&面壁智能的开源模型「小钢炮」MiniCPM-Llama3-V 2.5,瞬间在 AI 圈里炸开了锅。
在实锤之下,斯坦福团队也不得不紧急道歉。
正如面壁智能 CEO 李大海调侃式的回应,这是一种「受到国际团队认可的方式」。无论我们距离最顶尖的大模型还有多少差距,但国产大模型已经到了不能再被忽视的阶段
简单梳理一下时间线:
- 斯坦福 AI 团队发布 Llama3-V,号称 SOTA 多模态大模型
- 网友质疑该模型抄袭国内面壁智能 MiniCPM-Llama3-V2.5
- 质疑证据涌现,Llama3-V 作者上演「删库跑路」
- 面壁智能官方实锤抄袭,深夜给出声明
- Llama3-V 作者正式道歉,网友各持己见
抄袭面壁智能「小钢炮」,斯坦福 AI 团队上演「删库跑路」
近日,一个斯坦福 AI 团队宣布,只需 500 美元就可训练出一个超越 GPT-4V 的 SOTA 多模态大模型。
但很快,一位 X 用户 @yangzhizheng1 指出,该项目使用的模型结构和代码与面壁智能不久前发布的 MiniCPM-Llama3-V2.5 惊人的相似。
为此,X 用户 @yangzhizheng1 也放出了相应的质疑证据。
证据一:
Llama3-V 和 MiniCPM-Llama3-V 2.5 的模型结构、代码,简直是复制粘贴级别的相似,区别大概就是换了个马甲——变量名改了改。
就像是同一件衣服,只是换了不同颜色的纽扣,你说巧不巧?
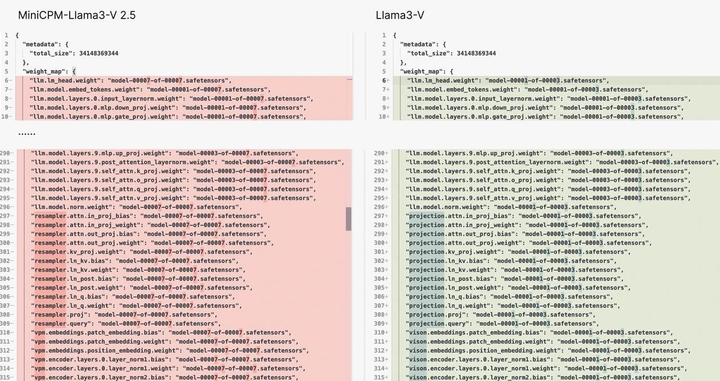
证据二:
Llama3-V 的作者被问到为啥能提前用上还没发布的 MinicPM-Llama3-V2.5 分词器时,他们解释称,用的是面壁智能上一代 MinicPM-V-2 项目。

但有媒体向面壁智能官方求证,在 HuggingFace 中,MiniCPM-V2 与 MiniCPM-Llama3-V 2.5 分词器分别是两个文件,文件大小也完全不同。
更何况,MiniCPM-Llama3-V 2.5 的分词器是用 Llama3 分词器加上 MiniCPM-V 系列模型的特殊 token 组成。
考虑到 MiniCPM-V2 的发布时间早于 Llama3,理论上它不可能包含尚未公开的 Llama3 分词器技术。
证据三:
更离谱的是,llama3-V 项目的作者面对用户的质疑,一看事情不妙,干脆上演了一出「删库跑路」的好戏。
连 GitHub 上的项目页面都撤了,堪称掩耳盗铃 2.0 版本。

Hugging Face 地址如下,目前打开该页面,我们只能看到「404」。
https://huggingface.co/mustafaaljadery/llama3v/commit/3bee89259ecac051d5c3e58ab619e3fafef20ea6
这还没完,更多证据正在不断涌现:
X 用户 @yangzhizheng1 表示如果往 MiniCPM-Llama3-V 2.5 的 checkpoint 添加高斯噪声(由单个标量参数化),出来的模型跟 Llama3-V 就像是一个模子刻出来的。
不仅如此,这模型还能识别「清华简」这种深奥的战国古文字,而且错得都一模一样,用面壁智能官方的话来说:
不仅对得一模一样、连错得都一模一样。

要知道这一古文字数据,是面壁智能和清华大学自然语言处理实验室团队花费数月时间,从清华大学收藏的清华简上逐字扫描并人工标注得来,从未对外公开过。
那斯坦福 AI 团队是如何凭空获得呢?
可以说,面壁智能 6 月 2 日的深夜声明算得上是彻底实锤斯坦福 AI 研究团队的抄袭。
直到今天凌晨,斯坦福 Llama3-V 团队的两位作者 Siddharth Sharma 和 Aksh Garg 在社交平台 X 上就这一学术不端行为向面壁 MiniCPM 团队正式道歉, 表示 Llama3-V 模型将悉数撤下。
名校学霸也抄袭?中国开源大模型正迎头赶上
此事之所以在网络上激起千层浪,一个重要的原因在于抄袭作者的背景实在光鲜。
公开信息显示,Siddharth Sharma 与 Aksh Garg 均是斯坦福大学计算机系的本科生,曾发表过多篇机器学习领域的论文。其中,Siddharth Sharma 曾在亚马逊实习过一段时间,目前主要从事于 AI 和数据相关工作。
而 Aksh Garg 的实习履历,那叫一个丰富,涵盖 SpaceX、斯坦福大学和加州理工学校等知名组织机构。
至于被这上述两位作者称为「代码搬运工」的 Mustafa Aljadery,是南加州大学出身,在舆论发酵之后,目前 X 账号已经被设为隐私状态。

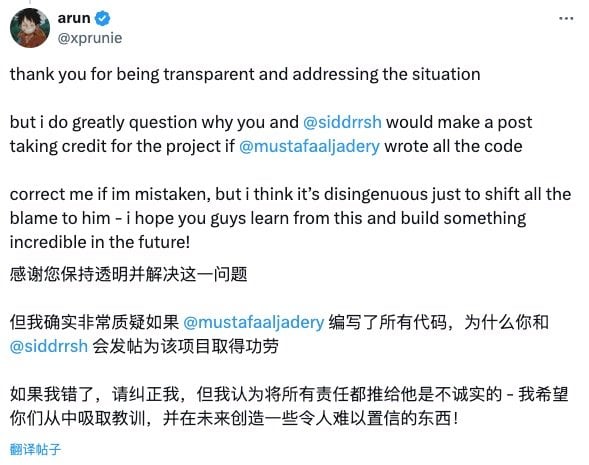
对于这的斯坦福 Llama3-V 团队的道歉声明,眼尖的网友却不吃这套。
例如,X 用户 @xunie 指出,这哥俩将责任归咎给一个人的甩锅行为,莫不是「有福同享,有难你当」?
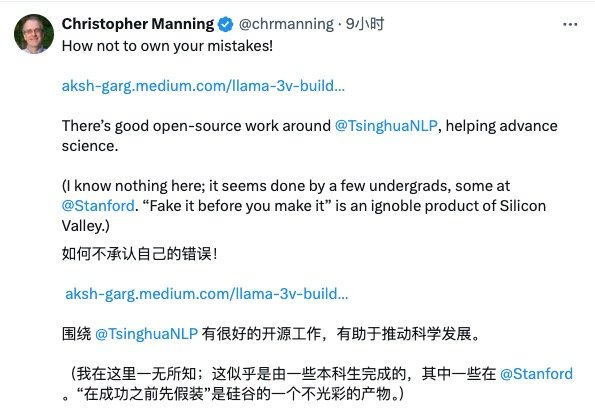
斯坦福 AI 实验室主任 Christopher David Manning 也站出来谴责这一抄袭行为,并且对 MiniCPM 这一优异的中国开源模型表示赞扬。
不过,也有网友抱着「得饶人处且饶人」的态度,悠悠然地鼓励道:
开放和诚实是科技界非常重要的价值观,期待你的新作品。

Google DeepMind 研究员 Lucas Beyer 表示,中国开源大模型拥有像 MiniCPM 这样好的模型,但国际上却没给够应有的关注……

面壁智能团队也于昨天对此事进行回应。
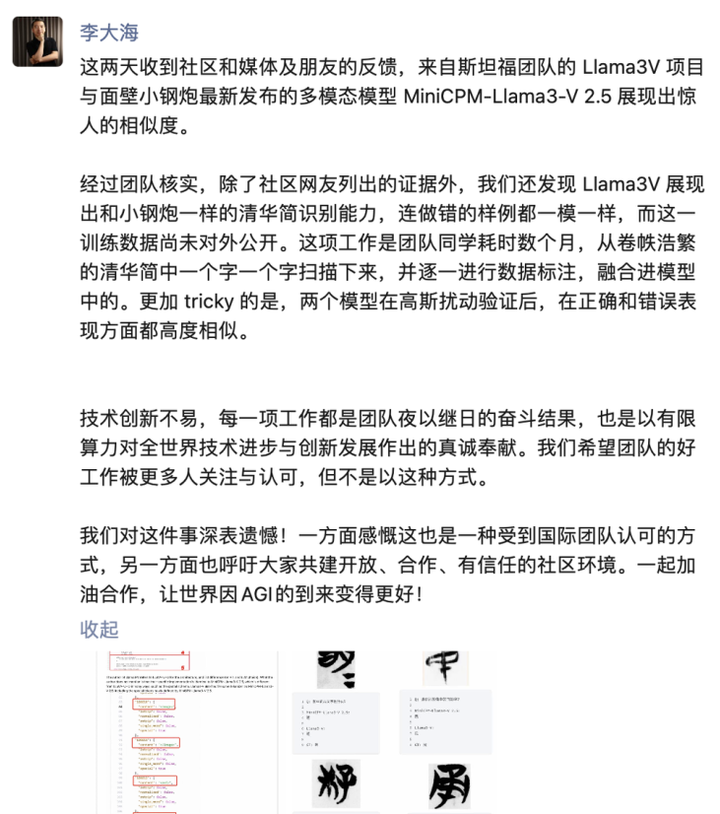
面壁智能 CEO 李大海表示:「技术创新不易,每一项工作都是团队夜以继日的奋斗结果,也是以有限算力对全世界技术进步与创新发展作出的真诚奉献。
我们希望团队的好工作被更多人关注与认可,但不是以这种方式。」
面壁智能首席科学家刘知远也在知乎上发文表示,表示这次事件从另一个角度证明了中国创新成果的国际影响力,强调了开源共享的重要性,以及对原创精神的尊重。
不得不说,这出 AI 圈的抄袭大戏,教科书般地诠释了叫「创新不易,且行且珍惜,学术诚信,人人有责」。
要知道,模仿了代码的形,却抄不来那份原创的风姿卓绝。
事实上,自去年以来,中国大模型如同雨后春笋般陆续开源,从以往的受益者转变为贡献者,不吝于向世界提供更多开源的优异成果。
上至阿里巴巴、腾讯等巨头,下至面壁智能,智谱 AI 、昆仑天工等 AI 初创,也都是开源社区的积极分子,为中国大模型的发展添砖加瓦。
我们也盼着,这股子开放共享的春风,能吹得更猛烈些。
正如面壁智能 CEO 李大海所呼吁的那样,大家一起共建开放、合作、有信任的社区环境。加油合作,才能让世界因 AGI 的到来变得更好!





