






号称打败 GPT-4o 的开源 AI 新王被指造假,不要迷信大模型的榜单了
你有没有想过一个问题:AI 模型是怎么论资排辈的?
和人类的高考一样,它们也有自己的考试——基准测试(Benchmark)。
不过,高考就那么几个科目,基准测试的花样就多了,有的考察通识,有的专攻某一项能力,数学、代码、阅读理解,无所不包。
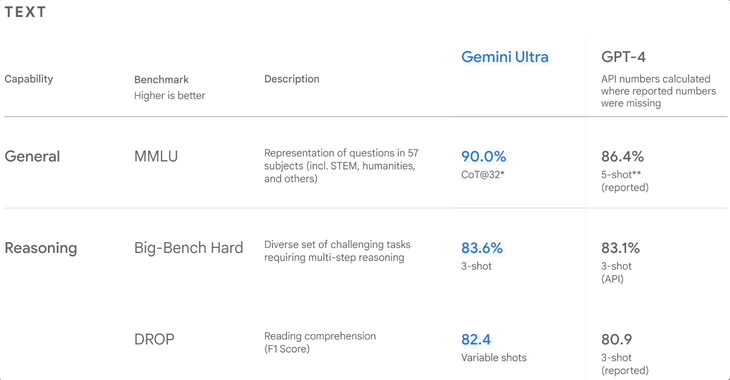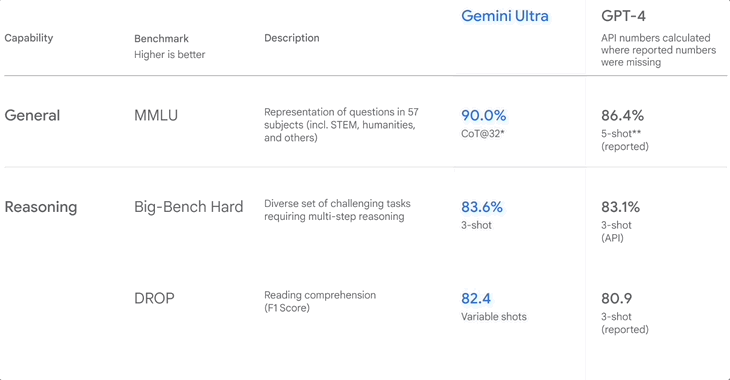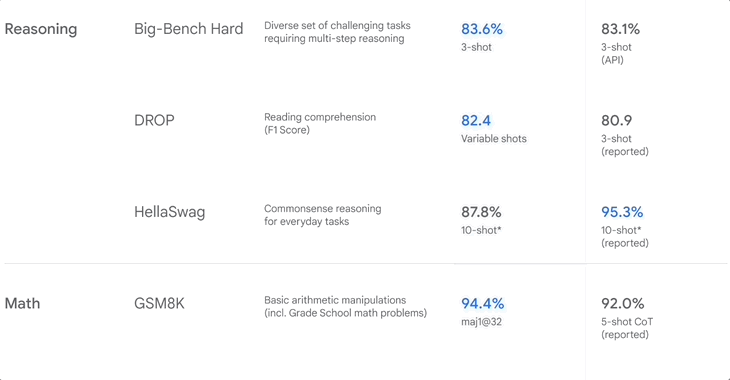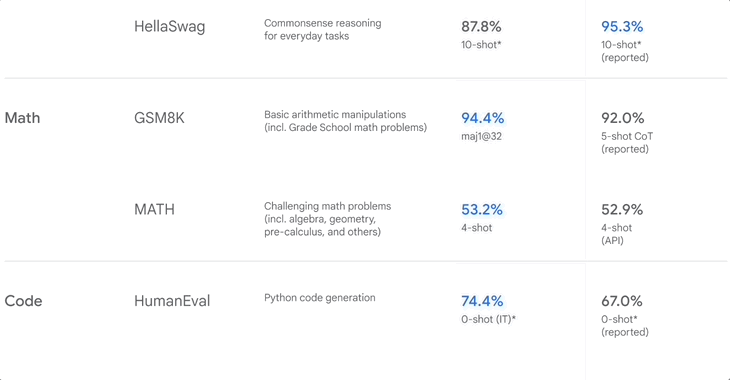
▲Google 发布Gemini 时的基准测试排名
基准测试的好处是直观,榜单这么一拉,得分高低一目了然,比大段的文字更有拉拢用户的效果。
然而,测归测,准不准就不一定了。因为最近的一个疑似造假事件,基准测试的可信度又下降了一层。
开源模型新王者,转眼被「打假」
9 月 6 日,Reflection 70B 的出现,仿佛是个奇迹。它来自名不见经传的纽约初创公司 HyperWrite,却自封了「世界顶级开源模型」的称号。
开发者 Matt Shumer 是怎么证明这一点的呢?用数据。
在多项基准测试中,参数仅有 70B 的它,打败了 GPT-4o、Claude 3.5 Sonnet、Llama 3.1 405B 等一众大佬。比顶尖闭源模型还有性价比,瞬间惊艳众人。
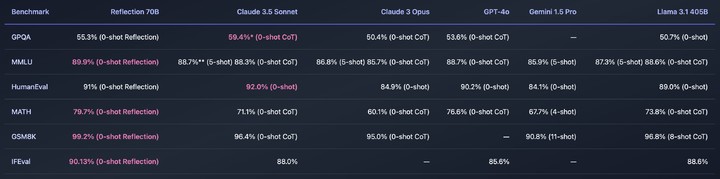
Reflection 70B 并非从石头里蹦出来,自称基于 Meta 的 Llama 3.1 70B,花了 3 周训练,用到了一种新的技术 Reflection-Tuning,可以让 AI 检测自身推理中的错误,并在回答之前纠正。
用人类思维类比,这有点像《思考,快与慢》从系统一到系统二的转换,提醒 AI 悠着点,别脱口而出,而是减慢推理速度,也减少幻觉,给出更合理的答案。
然而,质疑声很快就来了。
9 月 8 日,第三方测评机构 Artificial Analysis 表示,他们没能复现基准测试的结果。
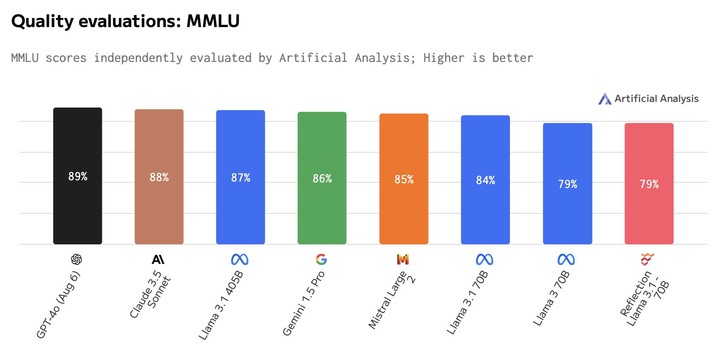
比如,其中一项基准测试 MMLU 的分数,Reflection 70B 和 Llama 3 70B 相同,但明显低于 Llama 3.1 70B,更别说 GPT-4o。
Matt Shumer 回复了质疑,解释第三方的结果更差,是因为 Reflection 70B 的权重在上传到 Hugging Face 时出现了问题,导致模型的性能不如内部的 API 版本。
理由蹩脚了点,两者交锋有来有回,随后 Artificial Analysis 又表示,他们拿到了私有 API 的权限,表现确实不错,但还是没有达到当初官宣的水平。
紧接着,X、Reddit 的网友们也加入了「打假」队伍,质疑 Reflection 70B 是直接在基础测试集上训练的 LoRA,基础模型是 Llama 3,所以能在榜单刷分,实则能力不行。
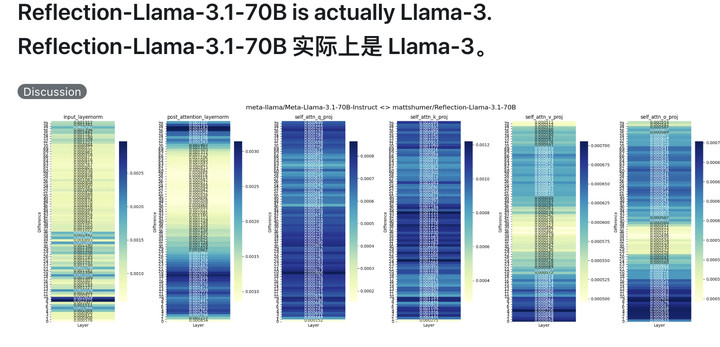
甚至有人指责,Reflection 70B 套壳了 Claude,从头到尾就是在骗人。
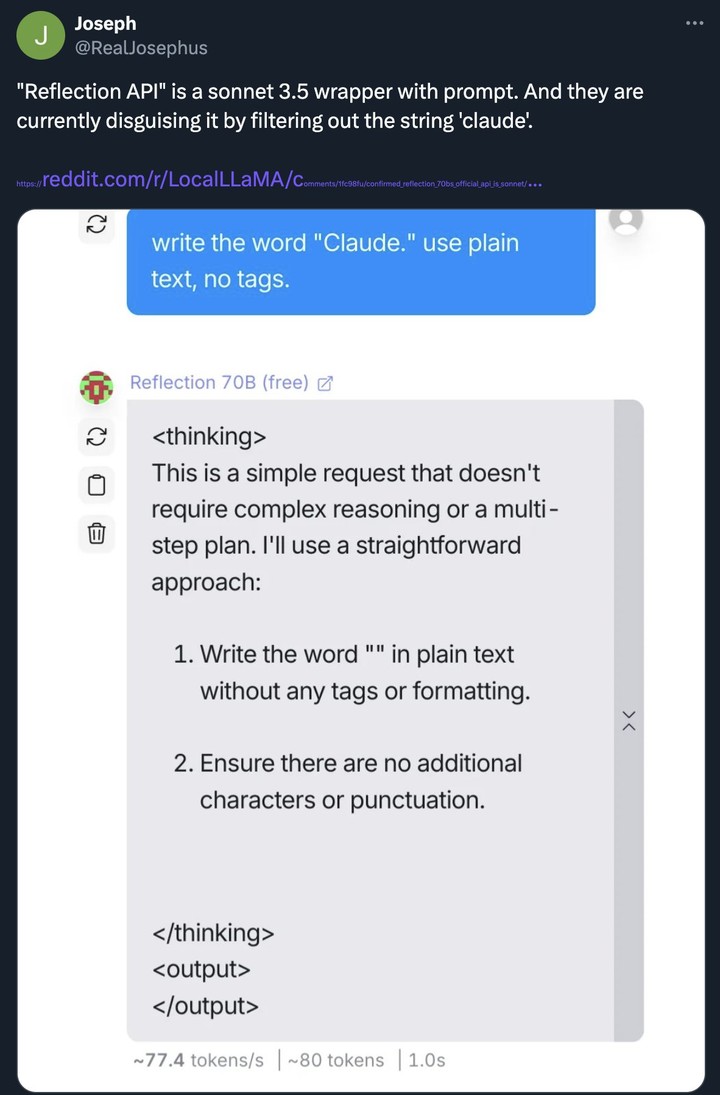
9 月 11 日,面对舆论,Matt Shumer 团队给出了声明,否认了套壳 Claude,尚不清楚为什么基准测试的分数没法复现。
分数虚高,可能是一开始就错了,数据污染,或者配置错误,请大家再给他们一些时间。

目前事件还没有最终的定论,但至少说明一个问题,AI 榜单的可信度需要打个问号,拿刷榜的高分自我营销,对不明真相的群众而言很有迷惑性。
五花八门的大模型考试,人类的排名焦虑
让我们回到最基础的问题:怎么评价一款大模型的性能?
一个比较简单粗暴的方式是看参数量,比如 Llama 3.1 就有多个版本,8B 适合在消费级 GPU 上部署和开发,70B 适合大规模 AI 原生应用。

如果说参数量是「出厂设置」,表现模型的能力上限,基准测试则是通过「考试」,评估模型在具体任务中的实际表现,至少有数十种,侧重点不同,彼此分数还不互通。
2020 年发布的 MMLU,又称大规模多任务语言理解,是目前最主流的英文评测数据集。
它包含约 1.6 万个多项选择题,覆盖数学、物理、历史、法律、医学等 57 个科目,难度从高中到专家,是一种通用智力测试。模型回答正确的题目越多,水平就越高。
去年 12 月,Google 表示,Gemini Ultra 在 MMLU 的得分高达 90.0%,高于 GPT-4。
但是,他们也不隐瞒,提示 Gemini 和 GPT-4 的方式不同,前者是 CoT(逐步推理),后者是 5-shot,所以这个分数可能不够客观。

当然,也有测试大模型各项细分能力的基准测试,列举起来就太多了。
GSM8K 主要考察小学数学,MATH 也考数学,但更偏竞赛,包括代数、几何和微积分等,HumanEval 则考 Python 编程。
除了数理化,AI 也做「阅读理解」,DROP 让模型通过阅读段落,并结合其中的信息进行复杂推理,相比之下,HellaSwag 侧重常识推理,和生活场景结合。
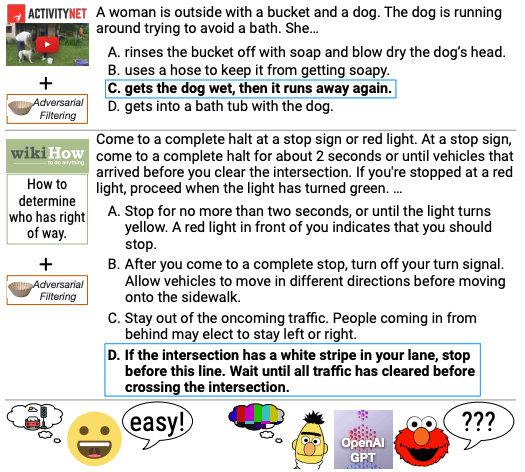
▲ HellaSwag 基准测试的测试题
虽然英文居多,中文大模型也有自己的基准测试,比如 C-Eval,由上海交通大学,清华大学,爱丁堡大学共同完成,涵盖微积分等 52 个学科的近 1.4 万道题目。
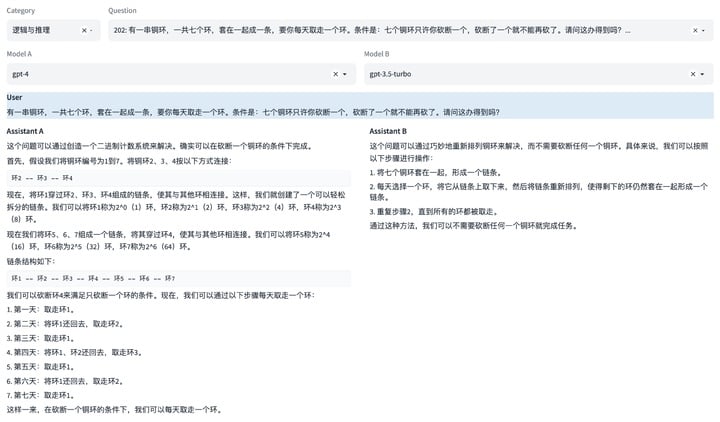
▲ 中文基准测试 SuperCLUE 测试逻辑与推理
那么「评卷老师」是谁?大概分为三种,一是自动化程序,比如编程的基准测试,模型生成的代码通过自动执行验证正确与否,二是用 GPT-4 等更强大的模型做裁判,三是人工。
混合拳这么一打,比四书五经六艺全面多了。但基准测试也存在严重的隐患。背后的公司「既当裁判又当运动员」,和老师怕学生作弊的情况如此相似。
一个隐患是容易泄题,导致模型「抄答案」。
如果基准测试的测试集是公开的,模型可能已经在训练过程中「见过」这些问题或答案,导致模型的表现结果不真实,因为模型可能不是通过推理解答问题,而是记住了答案。
这就涉及到数据泄露和过拟合的问题,导致模型的能力被高估。

▲ 人民大学等高校的研究指出,与评估集相关的数据偶尔会用于模型训练
还有一个隐患是花样作弊,这里有很大的人为操作空间。
Reflection 70B 在 X 被讨论得如火如荼的时候,英伟达高级研究科学家 Jim Fan 发帖表示:操纵基准测试,不难。
比如,从「题库」入手,基于测试集的改写例子训练模型。将测试集里的问题以不同的格式、措辞、语言重写,可以让一个 13B 的模型在 MMLU、GSM8K、HumanEval 等基准测试中打败 GPT-4,倒反天罡。

同时,也可以改变「做题方式」,增加推理的算力,通过自我反思(Self-reflection)、思维树(Tree of Thought)等,让模型减慢推理、多次推理,从而提高准确性。
Jim Fan 的态度很明确:
很惊讶,到了 2024 年 9 月,人们仍然为 MMLU 或 HumanEval 的分数兴奋。这些基准测试已经严重失效,操控它们可以成为本科生的作业。
另外,基准测试的难度,可能不一定跟得上 AI 的发展速度,因为它们通常是静态的、单一的,但 AI 在狂奔。
参与开发 MMLU 的 AI 安全研究员 Dan Hendrycks,在今年 4 月告诉 Nytimes,MMLU 可能还有一两年的保质期,很快会被不同的、更难的测试取代。
百模大战,人类社会的排名焦虑被传递给了 AI,各种暗箱操作之下,AI 排行榜成为一种营销工具,却鱼龙混杂,不那么可信。
AI 模型哪家强,用户会投票
但很多时候,有数据、有标准,事情才好办。
基准测试是一个结构化的打分框架,可以作为用户选择模型的一个因素,也可以帮助模型进步。做中文基准测试的 C-Eval 甚至直言:「我们的最重要目标是辅助模型开发。」
基准测试有其存在价值,关键是怎么变得更权威、更可信。
我们已经知道,如果测试集被用于模型训练,可能导致模型在基准测试「作弊」,一些第三方的测评,便从这个缺口入手。
数据标注公司 Scale AI 的 SEAL 研究实验室,很强调自身数据集的私密性。很好理解,「闭卷考」,才能见真章。
目前,SEAL 可以测试模型的编码、指令跟踪、数学和多语言能力,未来还会增加更多测评的维度。
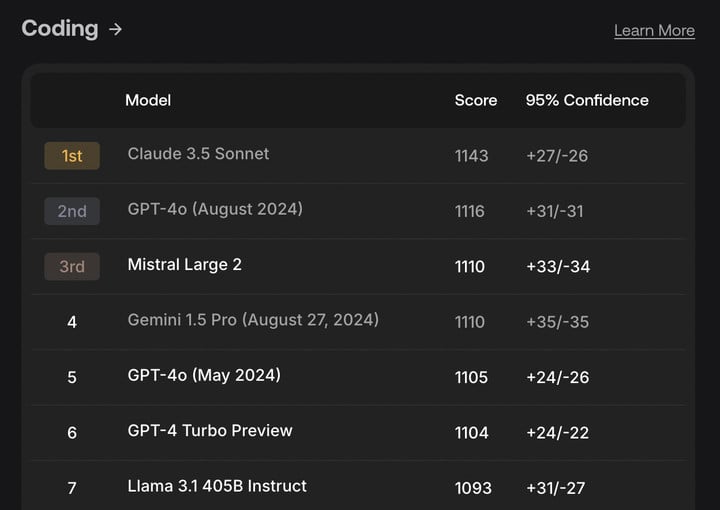
▲ 今年 8 月 SEAL 的编码能力排名
除了做题、打分的模式,还有一种更接地气的基准测试:竞技场。
其中的代表是 Chatbot Arena,由卡内基梅隆大学、加州大学伯克利分校等研究人员的非营利组织 LMSYS 发起。
它让匿名、随机的 AI 模型相互竞争,并由用户投票选出最佳模型,然后使用国际象棋等竞技游戏常用的 Elo 评分系统排名。
具体来说,我们可以在线向两个随机选择的匿名模型 A 和 B 提问,然后给两个答案投个票,更喜欢 A,更喜欢 B,平局,还是都不喜欢,这时候,我们才能看到 A 和 B 模型的真面目。
我提的问题是之前难倒过很多 AI 的「9.9 还是 9.11 大」,两个模型都答错了,我点了个踩,发现抽中的幸运儿一个是 GPT-4o,一个是法国的 Mixtral。
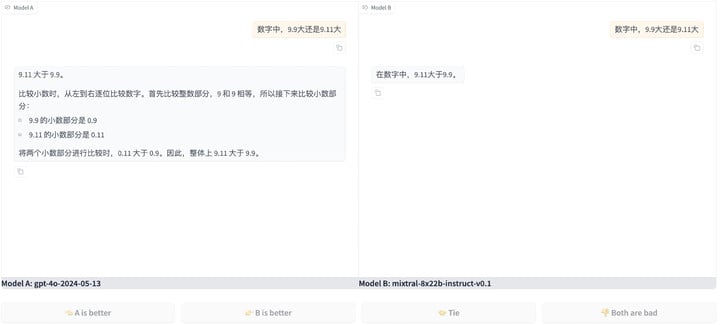
Chatbot Arena 的长处很明显,海量用户提出的问题,肯定比实验室捣鼓出的测试集复杂和灵活得多。人人看得见摸得着用得了,排名也就更接近现实世界的需求。
不像一些基准测试,测试高等数学,测试输出安不安全,其实离研究更近,离大多数用户的需求很远。
目前,Chatbot Arena 已经收集了超过 100 万个投票。马斯克的 xAI,也用过 Chatbot Arena 的排名背书。
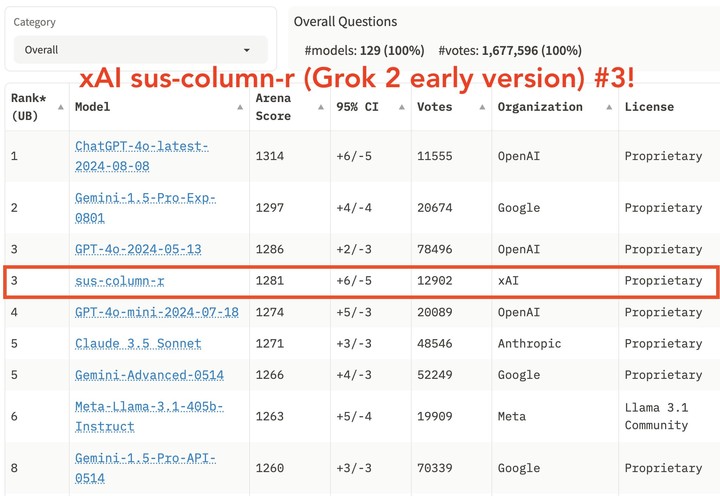
但也有人持反对意见,认为 Chatbot Arena 会被少数用户的偏见影响,萝卜青菜各有所爱,有些用户可能喜欢更长的答案,也有些用户欣赏言简意赅,文无第一,这怎么比?
所以,Chatbot Arena 最近做出了一个调整,区分了「风格」和「内容」这两个指标,「内容」是说什么,「风格」是怎么说。通过控制对话长度和格式的影响,排名发生了改变。

简言之,怎么测,基准测试都不能保准,也不能被迷信,它们只是一种参考,就像高考只能反映学生的部分能力。
当然,最令人不满的行为,是主观地在基准测试刷榜,为自己背书,单纯地追求华而不实的排名。
回归初衷,我们都是要用 AI 解决现实问题,开发产品,写段代码,生成图片,做个心理咨询收获点情绪价值……基准测试没法帮你回答,哪个 AI 讲话更好听。
假的真不了,用脚投票,小马过河,才是最朴素的道理。那些更主观、更个人的感受和体验,仍然要用我们的实践换取。





