






AI 美女占领小红书,没那么糟糕
最近,一则赛博美女抢滩小红书的消息在微信聊天群里炸开了锅。
群聊记录显示,有网友使用账号矩阵管理软件操控 1327 个账号,直接「屠版」小红书。结果,推送系统居然没识别出来,反而还帮着推流。
代入用户的视角,敢情我看了半天的美女,正准备鼓起勇气接触呢,你告诉我这居然是 AI?
这天,算是塌了。
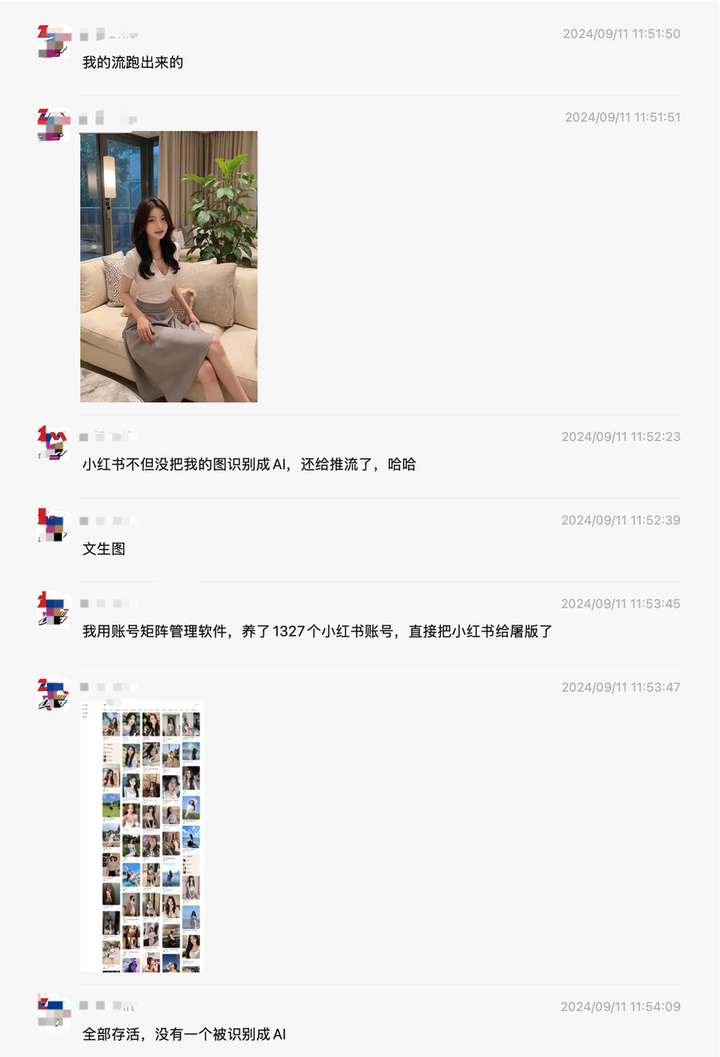
消息传开后,舆论迅速撕裂成两派。
省流派觉得,考虑到要管理上千个手机号,同时还能躲避 AI 检测,故而多半为 AI 软件或矩阵软件的终极韭菜收割机。
另一派则认为,几乎所有社交媒体都被 AI 黑产造访过,小红书的检测系统赶不上趟也在情理之中。
只是估计连小红书颜值博主也没想到,自己的对手有一天会是连肉眼凡胎都没有的 AI。
赛博美女抢滩小红书,伤害了谁
照惯例,先上几张图,看看你能看出多少门道。
说实话,其实如果不是放大了看,在界面匆匆一瞥,我们几乎察觉不出这些照片的 AI 味?即便是细心观察,有些照片连 AI 爱好者也未必敢打包票。
▲图片来自 @imxiaohu
而如果流传的消息属实,那我们大致能捋出几个受害者——
被蒙在鼓里的用户、被内卷的颜值博主们,小红书平台本身、以及需要加班的程序员……
当排山倒海的 AI 图片朝着大众奔涌而来,实际上也形成了一个筛选机制。
拥有火眼金睛的用户终究是少数,而更多普通人只会在不经意间留下自己的「一键三连」,然后在 AI 图片的漩涡中循环往复。
AI 虐你千百遍,你待 AI 如初恋。

在 AI 图片的攻防战中,如果小红书的审核机制未能识别出 AI,似乎也不足为奇。
PS 等修图软件的出现,改变了摄影的本来面目,真人和虚拟的界限也就因此模糊了。相比于某些反牛顿定律的美颜「照骗」,有时 AI 反而显得过于保守了。
如同我们在面对眼花缭乱的美颜照时,难免会怀念起「原图直出」的拍照氛围。类似地,我们现在也站在道德的制高点上抨击 AI 图片。
没有绝对的对错。我们可以接受 AI 图片的存在。但赛博博主们坏就坏在行事不够敞亮,再不济也得为 AI 图片标明身份。
在注意力经济的时代,我们既不喜欢也不乐意被 AI 暗地里割韭菜。
因此,这次事件才会触动用户的敏感神经。至于可能受到影响的小红书程序员嘛,我的建议是,还是多加加班吧。
此外,凭借秒级的图片生成速度和随意转换任意场景的能力,一旦成本极低的 AI 图片涌入平台,小红书颜值博主们将面临严峻的生存挑战,同时也会对平台方造成沉重的打击。
用 AI 美女薅羊毛,靠的是本事
用 AI 美女图片薅羊毛,凭的是本事。
在过去,AI 生成的图像在细节上偶尔会出现不对称、阴影错误或者模糊纹理等问题,而人物的手部、眼睛、背景重复更是「重灾区」。
只是,当你还在对着那些拙劣的六指 AI 图片发笑时,AI 图片生成技术早就已经 Next Level 了。
不信,不妨对比一下 Midjourney v1 和 v6.1 版本的图像生成效果。

如果这还不够直观震撼,那再看看 Midjourney 在短短一年半内从 v1 到 v6 的迭代蜕变。


插个冷知识, v6 版本是去年 12 月发布的。
包括上月初,Google 「TED 演讲者」图片凭借逼真的细节更是骗过了数千万网友,甚至连 AI 识别软件都没有发现破绽。
一鲸落,万物生。在独角兽 Stability AI 仿佛要应验「倒下」的预言时,出走的人才聚是一团火,散是满天星。
后续扒出的内幕显示,爆火的 Google 「TED 演讲者」照片其实是使用 Flux 真实版 LoRA 制作而成。作者也正是来自 Stable Diffusion 团队的前成员 Leo Kadieff。

近两年 AI 图片生成质量的进步有目共睹,其原因也不难理解。
2014 年,Gan 之父 Ian Goodfellow 提出了生成对抗网络(GANs),这被视为图像生成技术的革命性突破。
GANs 由两个神经网络组成:生成器(Generator)和判别器(Discriminator)。生成器负责生成新图像,而判别器则试图判断生成的图像是否是真实的。
通过这种对抗的方式,生成器逐步改进,生成的图像也越来越逼真。
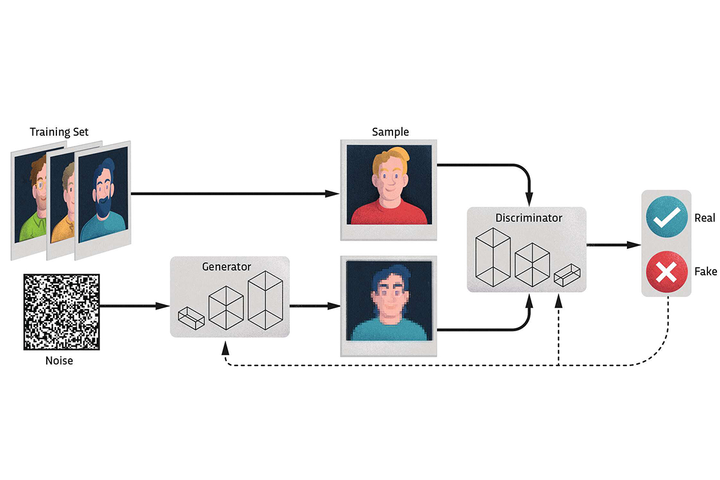
GANs 的架构在推出后不断进化,出现了许多变种和改进:
- 2016 年,通过引入卷积网络,GANs 在生成复杂、高分辨率图像方面表现出色,尤其是在生成人物面部、动物等自然图像时。
- 2017 年,英伟达提出了 StyleGAN,它通过调节图像的不同特征层,使得生成图像可以定制风格。这使得 AI 能够生成具有特定风格的图像,比如不同面部特征、发型、背景等。
- 2018 年, BigGAN 进一步提升了 GANs 生成高分辨率、逼真图像的能力。它通过增加网络规模和训练数据,使得AI生成的图像质量达到全新高度。
再后来,随着扩散模型(Diffusion Models)等算法的提出和优化,极大地推动了图像生成技术的发展。AI 生成图像的能力开始进入了一个高度逼真、几乎无法与真实图片区分的阶段。
这一时期的代表性突破包括 DALL·E(2021),以及 Midjourney、Stable Diffusion(2022)。
作为普通用户,我们现在只需要简单地输入文本描述,模型便能自动生成符合预期的高质量图像。

尽管扩散模型的原理看似复杂,其实也相当直观。
想象一下,你有一张白纸和一些彩色笔,你想要画出一幅美丽的风景画。但是,如果你只是随意地涂涂画画,最后可能得到一幅混乱的画面。相反,如果你有一张已经画好了的画,然后你慢慢地、一点一点地擦掉一些颜色,直到整幅画变成一团模糊,这个过程就像是 「扩散」—— 你把一幅有序的画变成了无序的噪声。
当前引入图片生成领域的扩散模型原理就像是这个过程的反向操作。
它从一个完全随机的起点开始,比如一团模糊的颜色或者是一些随机的数字(我们可以想象成是白纸上的一团乱涂)。然后,AI 就像是一位艺术家,它慢慢地、一步步地在这张随机的「噪声」 上添加细节,每一次添加都让画面变得更加有序,更接近于它想要生成的那幅画。

这个过程可以分成两个主要的步骤:
- 前向扩散(加噪):这就像是你在一张画上不断涂抹,直到它变得无法辨认,变成了一团噪声。
- 逆向扩散(去噪):这是 AI 的工作,它需要学会如何从这团噪声中恢复出原来的画。AI 通过学习大量的画作,了解什么样的噪声对应什么样的细节,然后一步步地「擦掉」 噪声,逐步恢复出清晰的图像。
在逆向过程中,AI 会使用一种叫做神经网络的工具,这就像是一个复杂的「反涂抹」 机器,它能够识别出噪声中的模式,并逐步还原出原始的图像。
每次还原都是在猜测和修正,直到最终完成一幅全新的、AI 生成的画作。

那有没有一眼识别 AI 生成图片的方法呢?
有,但要么不靠谱,要么过于繁琐,普通人也难以应用。
比如我们可以通过分析图片的噪声分布、边缘锐度或纹理模式来识别生成图片。又或者,一些 AI 生成的图片可能在细节上比较粗糙,比如光照、阴影或反射效果可能不符合现实世界的物理规律。
再比如,AI 生成的图片可能缺少某些元数据或包含异常的元数据值。甚至,存在一些专门识别 AI 图片的工具和算法。
而最为明智的选择,莫过于主动拥抱 AI,如此一来,在面对 AI 图片时便不会落入下风。
当真实与虚拟之间的界限越来越模糊,人们追求的不仅是视觉享受,还有那份真实的情感交流。技术的进步应当服务于人性的需求,而不是成为误导他人的工具。
人类的无聊,不该让 AI 背锅
人类的生活已经被 AI 包围。
当 AI 进场时,人们或许还天真地以为与自己无关。殊不知,无论接受与否,它已经悄然渗透到我们的生活。
技术发展的悖论在于,我们总是期待看到技术的终极形态,但在成熟前,总需要有人承受它的稚嫩与不足。
从信息维度所代表的产品来看,文字有 ChatGPT,图片有 Flux,音频有 Fish Speech,视频有 Runway 等等。这些明星产品虽然光彩夺目,却也不免成为被滥用的工具。
最典型的例子莫过于 AI 引发的一系列互联网污染事件。
比如用 AI 文章充斥网络,AI 爬虫训练数据,AI 美女图片欺骗感情,AI 生成音乐骗取版税,以及 AI 评论机器人等案例,这些事你可能已经见怪不怪。

来自 Fastly Threat Insights Report 的报告指出,全球互联网有 36% 的流量是由机器人产生的,而人类用户产生的流量只有 64%。
我们可能正在接近「死亡互联网理论」 所预测的未来,即最终互联网上的人类活动被机器人和 AI 生成的内容所取代。
再过几年,可能会出现这么一种情况,AI 博主创造自己的作品、然后 AI 机器人「一键三连」,并转发给另一个 AI,实现闭环,而人类彻底失去存在感。
甚至无需等待多年,一些 AI 博主就已经敢亮明牌了。
最近,全球首届 AI 美女大赛落下帷幕,来自摩洛哥的 AI 美女蕾莉凭借美貌、精通 7 国语言成功夺下冠军,而她本身在 IG 就有着高达数十万的真人粉丝。

尽管明知道这背后是个真人在操控,但粉丝还是乐此不疲地追捧。
与 AI 谈恋爱也不再稀奇。情感需求是真的,心理投射对象是人类还是 AI 则无关紧要。当然,52 岁大叔与 24 岁 AI 女友的年龄差也不再是问题。
那么,人类准备好迎接 AI 的全面包围了吗?
答案因人而异,有些人选择「躺平」,有些人保持警惕,还有些人奋起反抗…
比如在看完 AI 美女图片后,选择「躺平」的网友留下了最朴实的评论:「不管她是不是 AI,反正是我喜欢的类型」。
再比如,电影《你想活出怎样的人生》片方曾披露了宫崎骏纯手绘的创作过程。在被 AI「入侵」的动画行业,像宫崎骏这样还执拗于手绘的大师已然是稀有物种了。

对于 AI 带来的威胁,这位 83 岁的动画大师愤怒地表示:
我绝对不会让 AI 介入我的工作… 世界末日要来了,人类已经对自己失去信心了。
工具本身并无善恶之分,倒是常常替人类背了黑锅。
当人类无法在流量至上的喧嚣里保持定力时,被 AI 全面包围,甚至上演「自我淘汰」的戏码,压根就不需要 AI 多努力。
想想最开始提到的小红书事件,千篇一律的拍照姿势,流水线般的拍摄背景,人类争先恐后地复制这种平庸,最后反倒亲手掩埋了自己的个性。
而 AI 不过是顺手将这种雷同的爆款模式高效复制了一番。
简言之,不是 AI 把人类挤下了舞台,而是人类主动放弃了自己的位置,甚至连道别都懒得说一句。





