






叫板 Sora! Adobe 推出 AI 视频神器,一句话 P 视频
最近 AI 视频领域异常热闹,Adobe 也刚刚加入了这场混战。
在今年的 Adobe Max 大会上,Adobe 正式推出了自己的 AI 视频模型——Firefly Video Model,进军生成式人工智能领域。

Adobe 的首席产品营销经理 Meagan Keane 表示,Firefly Video Model 的推出旨在简化加速视频创作,并且增加视频的故事讲述能力。概括来讲,这个模型包含三个有趣且实用的功能:
- Generative Extend(生成拓展)
- Text-to-Video(文生视频)
- Image-to-Video(图生视频)
其中,Generative Extend 已经被集成至 Adobe 所开发的专业视频编辑软件 Premiere Pro 当中;Text-to-Video 和 Image-to-Video 则刚刚在 Firefly Web app 中推出 beta 版本。
顾名思义,如果你拍摄的视频片段太短或缺失某些部分,Generative Extend 可以帮你在视频片段的开头或结尾进行「生成式扩展」。
也就是说,假如所需的镜头不可用,或者某个镜头的剪辑时机过早或过晚,剪辑师只需要拖动该视频片段的开头或结尾,Generative Extend 就可以自动填充生成式内容,以保持视频的连贯、平滑。
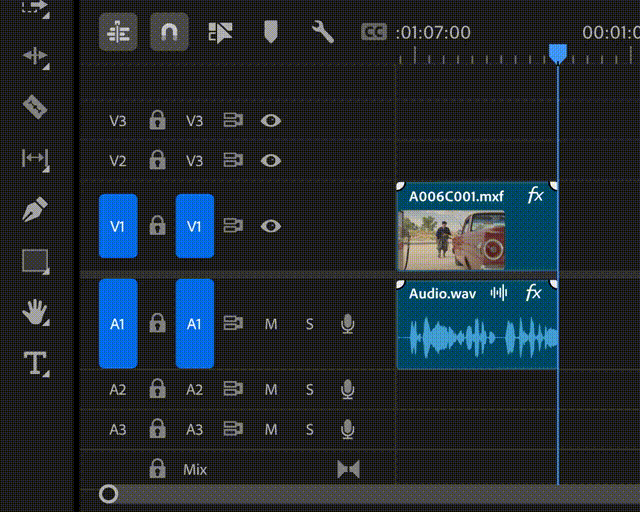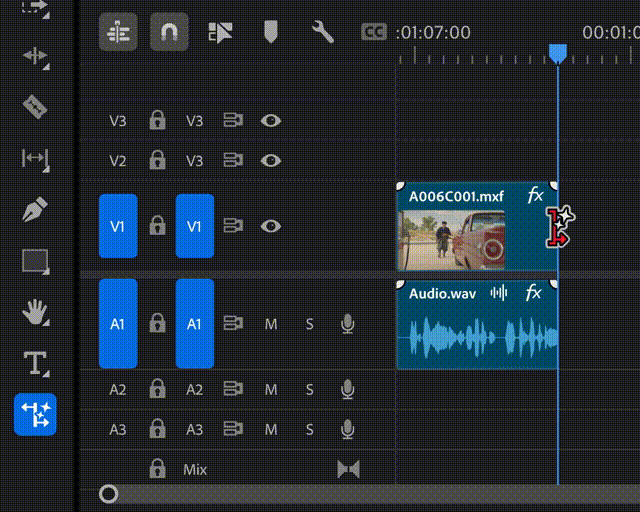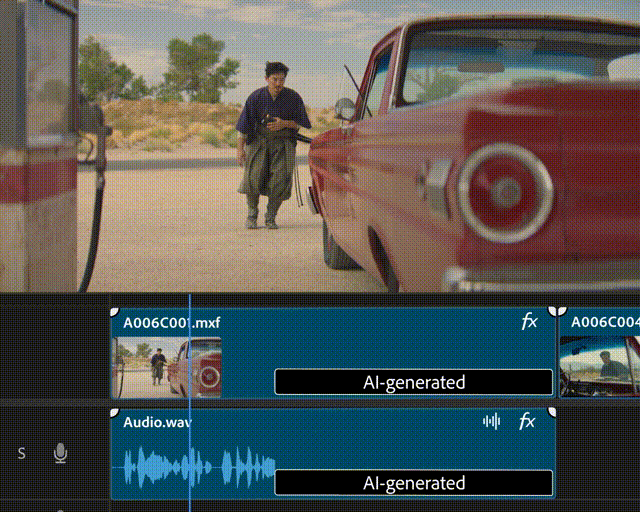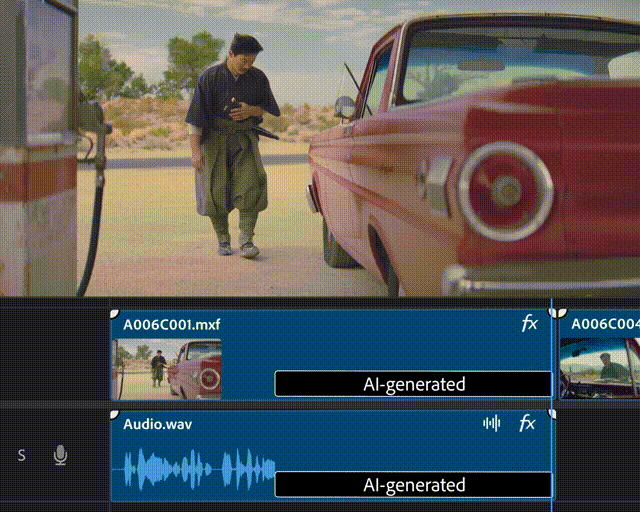
▲Generative Extend 的生成式视频扩展功能演示(图片来源:Adobe)
这意味着如果视频创作者在拍摄过程中得到了一个「废镜头」,他可能不再需要回到原场地重新拍摄,而是利用 Generative Extend 直接对原片段进行扩展和修复。
一定程度上讲,这确实有助于提高视频创作效率——当然,是在 Generative Extend 所延伸的片段质量过硬的情况下。
遗憾的是,该功能目前的最大分辨率限制为1080p,且片段最长只能扩展两秒钟。
因此 Generative Extend 只适合对视频片段进行微小的调整,即它只能帮助用户修复某些细节,却不能代替创作者本身,进行大篇幅的创作。
Generative Extend 还可以帮助用户拍摄过程中进行调整,纠正在拍摄过程中视线偏移或其他意外产生的移动。

除了视频之外,Generative Extend 还可以用于音频的平滑编辑。它可以将视频中的环境背景音效扩展长达十秒钟时间,但无法对对话或音乐进行拓展。
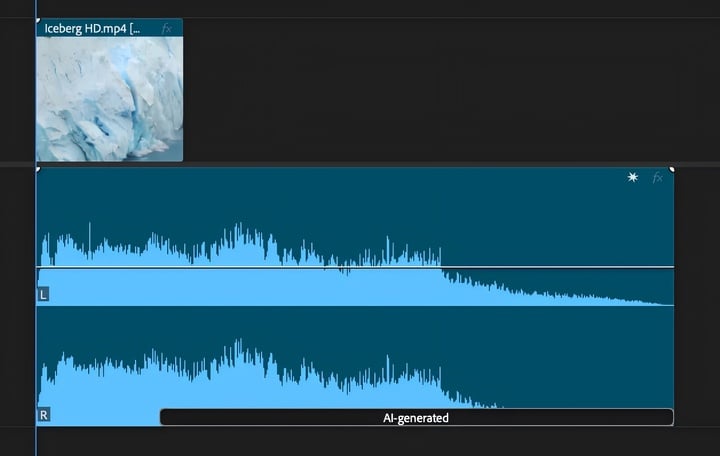
▲Generative Extend 的音频扩展功能示意(图片来源:Adobe)
如果你想在视频创作过程中省点力气,你可以使用 Text-to-Video 功能直接生成。同它的「老前辈」Runway 和 OpenAI 的 Sora 一样,用户只需要输入他们想要生成的视频的文本描述,它就可以模拟「真实电影」、「3D动画」和「定格动画」等各种风格生成相应的视频片段。
以下是一些使用 Text-to-Video 功能生成视频片段,感受一下:

▲提示文本:电影无人机飞越广阔的红色火星景观,它从我们脚下飞驰而过,当太阳升起时,地平线是红色的。在镜头的结尾,太阳从地平线上升起。(图片来源:Adobe)

▲提示文本:电影特写和夜晚街道中央一位老人的肖像细节。灯光气氛沉闷,充满戏剧性。颜色等级为蓝色阴影和橙色高光。这个男人有极其逼真的细节皮肤纹理和明显的毛孔。动作微妙而柔和。相机不动。胶片颗粒。老式变形镜头。(图片来源:Adobe)

▲提示文本:在墨西哥一个美丽、柔和的天井内拍摄的视角。水清澈湛蓝,在傍晚的阳光下闪闪发光。颜色是温暖和神奇的魔幻风格。高品质,电影感。(图片来源:Adobe)
除了逼真的,电影般的视觉影像,Text-to-Video 还支持生成一些「抽象」的画面。例如,它可以被用来生成包括火焰、水、漏光和烟雾等元素的视频,并覆盖叠加到现有的视频上,来增加现有内容的视觉深度和趣味性。
▲提示文本:黑色背景上的电影漏光,有机质感,逼真。(图片来源:Adobe)

▲上述视频与现有视频合成后生成的视频片段(图片来源:Adobe)
值得一提的是,用 Text-to-Video 生成的视频片段还可以使用一系列「相机控制」进行进一步细化处理,这些控制能够模拟真实的相机角度、运动和拍摄距离等。
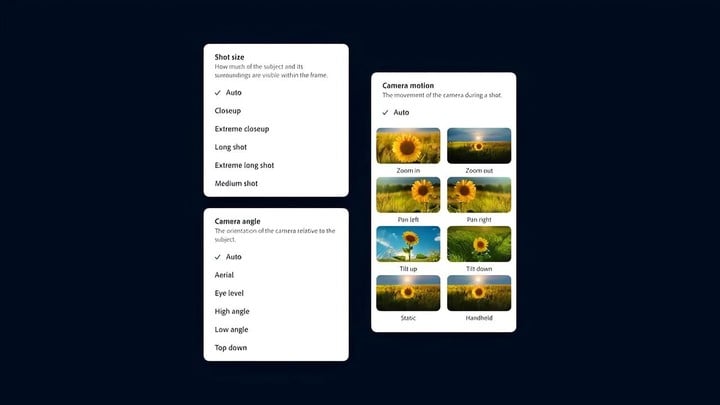
▲ 相机控制选项(图片来源:Adobe)
Image-to-Video 功能则更进一步,允许用户在视频创作过程中添加「参考图像」,以生成更加贴近用户想象的视频。
视频创作者可以从一张图像和照片出发,利用 Image-to-Video 功能直接制作「B-roll」(电影和视频制作术语,指的是除了主要拍摄内容(A-roll)之外的辅助视频素材)。
用户还可以通过上传视频的单帧,并由 Image-to-Video 自动补充缺失帧,以此来创建完整的特写镜头。

▲提示文本:花朵在风中摇曳,一只美丽的蝴蝶落在其中一朵花上。(图片来源:Adobe)
「众所周知,视频不能 P,所以一定是真的。」
然而,Image-to-Video 的「赛博重拍」功能,直接让这句话变成过去式。它宛如一只「上帝之手」,可以让用户对视频内容(视频中的人物动作等)直接进行操作和修改。来看下面的例子:

▲ 原视频片段(图片来源:Adobe)

▲修改后的视频片段,提示文本:一只戴着手套的宇航员的手进入画面,并拔掉了其中一根黄色电缆,具有电影感。(图片来源:Adobe)
目前,Text-to-Video 和 Image-to-Video 功能生成视频片段的最大长度仅为五秒钟,质量最高为 720p 和每秒 24 帧。视频生成时间大约为 90 秒,Adobe 正在开发「涡轮模式」来缩短这一时间。
视频生成质量的不足表明,用户还无法用 Firefly Video Model 生成一部完整的电影,暂时只能作为创作辅助工具来使用。
Adobe 强调,Firefly Video Model 只会在许可内容(如 Adobe Stock)和公共领域内容上对该模型进行训练,而不会在客户提供的内容上进行。
此外,使用 Firefly Video Model 创建或编辑的视频可以内嵌内容凭证,旨在为创作者和内容出处提供归属证明,有助于声明 AI 使用情况和所有权权益,以保证「商业安全」。
感兴趣的读者可以在以下链接加入 Adobe Firefly Video Model 的体验候补名单:
https://www.adobe.com/products/firefly/features/ai-video-generator.html





