






火遍小红书的 AI 视频神器,这次整出的新活又让我停不下来
AI 视频的多主体一致性,向来是个难题。让 AI 凭空生成模特和衣服不难,但如果甲方要求,必须要让马斯克代言,穿上毛绒大衣,AI 可能就办不到了。
Pika 最近更新的 2.0 模型,提出了一种很有趣的解决方式——我们上传多张图片,Pika 会精准参考图片中的元素,生成视频。

集齐人物、商品、场景的照片,一个非常基础的广告片就出炉了,而且这些素材在视频里长得都和照片里一样。

这是否意味着,AI 视频的一致性难题解决了,广告行业的朋友们又要焦虑了?其实并没有,经过实测,Pika 的可玩性很高,但论实用,道行还不够。
马斯克和奥特曼看电影,名画吃薯条,同框从未如此简单
Pika 上传多张参考图片的功能,叫作「Scene Ingredients」(场景成分)。
使用起来很简单:1.点击「+」上传图片,上限 6 张;2.在文本框里,写上简单的提示词。
接下来就进入实操——让闹得水深火热的马斯克和奥特曼,化干戈为玉帛,在一起看电影。
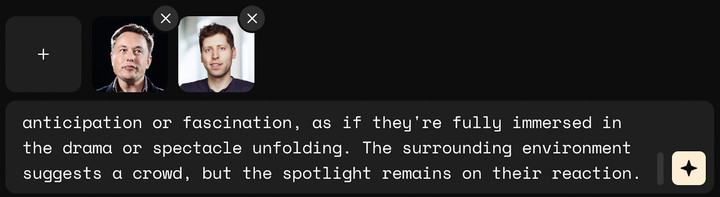
▲提示词:两个人坐在漆黑的观众席中。他们手捧一桶爆米花,一把放到嘴里嚼着,全神贯注地看着眼前的场景。他们睁大眼睛的表情传达出热切的期待或着迷,仿佛他们完全沉浸在正在展开的戏剧或场景中。周围的环境表明人群拥挤,但焦点仍然集中在他们的反应上
上传两位的照片就够了,观众席可以用提示词写出来。

对于马斯克,AI 的发挥很稳定。但奥特曼看起来是地主家的傻儿子,吃相恐怖就不说了,眼睛大得要掉出来。
Pika 很有趣的一点是,素材可以「复用」。
所以,我们可以让马斯克和奥特曼过把模特瘾。只上传一张服装图片,然后通过提示词,让他们穿着一样的绿色大衣,拍个时尚大片。

▲提示词:两名男子在壮丽的冬日风景中站在一起自拍。两人都穿着相同的绿色长外套。全身照,从头到脚展现他们。他们摆出专业模特般的姿势,脸上挂着自信的微笑。电影灯光突出了他们的脸庞和外套的奢华质感。高端时尚摄影风格,专业相机品质,时尚杂志美学
两人的照片都找了现成的,绿色的大衣和冰天雪地的背景是另外用 AI 生成的,衣服上的「AIGC」,算是考验 Pika 的附加题。
结果,场景和大衣的一致性保持得不错,「AIGC」的字样依稀可以辨认,两位模特的动作也遵循了提示词。
但最大的问题是,这两人是谁?视频的人脸和照片,不能说一模一样,可以说是毫不相干。

不信邪,继续让 Pika 玩换装。
这次,我们请出扎克伯格,照例先用 AI 图片工具生成衣服,上面写着「I was human」(我曾是人类),呼应经典的机器人梗。
然后,再找一张扎克伯格的图片,和一把尤克里里的图片,让小扎玩个音乐。

▲提示词:一位身穿黑色 T 恤的男子站在温馨的房间里,弹奏着尤克里里琴。镜头从中远景开始,展现他的整个身体,逐渐拉近,最后聚焦在 T 恤上的字迹上
Pika 对提示词的遵循和镜头的运动都挺好,衣服也丝滑地穿上了,但右手,尤其大拇指,还是不完美。

相较 Google Veo、OpenAI Sora 等,Pika 的模型能力不算顶尖,一个问题解决了,还有更多的 bug 被发现。
尝试了写实的,再来试试二次元画风,为了让坂田银时和漩涡鸣人同框,我特意挑选了两张背景都是蓝天白云的图片。
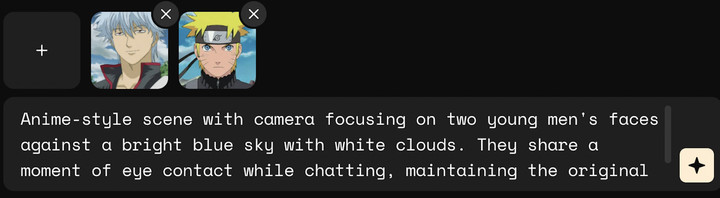
▲提示词:动漫风格的场景,镜头聚焦在两个年轻男子的脸上,背景是蔚蓝的天空和白云。他们一边聊天一边眼神交流,保留了原有的动漫艺术风格
背景融合得很自然,两位正面的表情发挥不错,吹动头发和衣服的风也恰到好处。然而,转身实在太可怕了。银时是死鱼眼,不是真的翻白眼啊喂。

次元壁都打破了,当然也可以让名画跨年代互动——蒙娜丽莎和戴珍珠耳环的少女在麦当劳餐厅吃薯条。
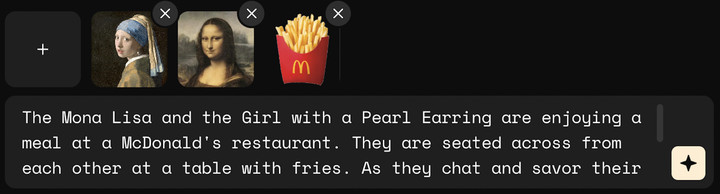
▲ 提示词:蒙娜丽莎和戴珍珠耳环的少女正在麦当劳餐厅用餐。她们相对而坐,桌上摆着薯条。她们边聊天边品尝薯条,摄像机从侧面捕捉她们,两位角色偶尔看向镜头,营造出一种随意而友好的氛围
效果一言难尽,看到蒙娜丽莎,不知道达芬奇想不想掀棺材板。两位好像贴图一样,被放在了视频里,头部也运动得非常诡异。

有时候,回归简单,道法自然,结果反而超出预期。

▲提示词:特写镜头,池塘表面出现气泡,然后咖啡杯从水中浮出
上传一张星巴克的图片,一幅莫奈的睡莲,就可以得到一个「清水出芙蓉」的咖啡杯。

PK 国产模型,控制 AI 视频的门槛更低了
一定程度上,Pika 提高了视频的可控性。话不说满,因为从实践看来,Pika 在场景、服装、物品上的一致性保持地较好,人物的脸容易崩,不管是什么次元。
同时,模型的基础能力,Pika 也有待进步,吃东西、弹琴等物体运动,仍然会出现问题。这些问题,能不能通过抽卡缓解呢?
三个字:抽不起。
Pika 2.0 目前仅对 Pro 和 Fancy 用户开放,如果按月订阅,每月至少花 35 美元,连免费试用的额度都没有。
而且,Pro 用户每月只有 2000 积分,但使用 Scene Ingredients 功能,一个视频就要花掉 100 积分。
▲vidu 界面
其实,国产 AI 视频模型 Vidu,比 Pika 更早地实现了「多图参考」的功能。更拿捏用户的是,它有免费体验的积分。
Pika 的几个案例,我也在 Vidu 跑了一下。蒙娜丽莎和戴珍珠耳环的少女吃薯条,两位像刚出土,但蒙娜丽莎的还原度比 Pika 高。

马斯克和奥特曼一起看电影,马斯克的脸像了七八成,奥特曼的脸依旧灾难。

坂田银时和漩涡鸣人同框,Vidu 居然能基于正脸生成侧脸,但画风和原图不太一样。

另外,在功能上,Vidu 有一点不如 Pika——最多只能上传三张图片。所以,让 Vidu 给马斯克和奥特曼拍时尚大片,我就没有上传背景,只上传了两位的照片和绿色的大衣。
两位给人的感觉很陌生。可以看出,人脸的稳定性,仍然是个难题。

和 Pika 相比,Vidu 效果如何,可以见仁见智。Pika 用的是 Pro 版,Vidu 用的是免费版,客观上也会导致两者的差异。
但 Pika 和 Vidu 的思路是相似的——仅靠几个图片素材、一段简单的提示词,就生成相对稳定的物体。
在 AI 视频生成中,保持主体一致性,目前相对可靠的是 LoRA 方案,用一定数量的、特定主体的素材,对模型进行微调。通过适量的素材和训练,模型能逐渐掌握这个角色的样貌特征。
但为了让 AI 视频被更多人用起来,有更广阔的商业价值,门槛就要降低。至少,从 Vidu 和 Pika 身上,我们看到了可能性。
靠 AI 短视频出圈,在整活的道路上一去不复返
Pika 的 2.0 模型发了没几天,海外网友已经玩疯了。
拿自己的照片,反复生成不同场景的视频,就可以实现「瞬息全宇宙」。
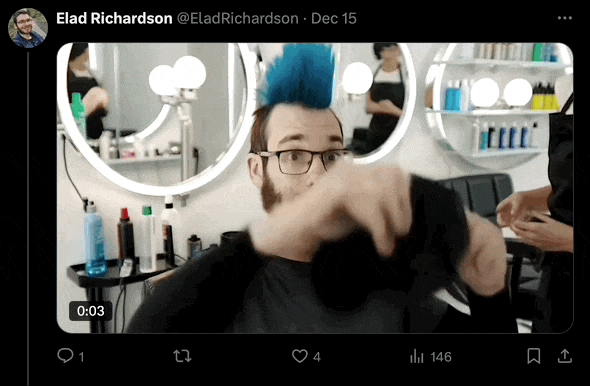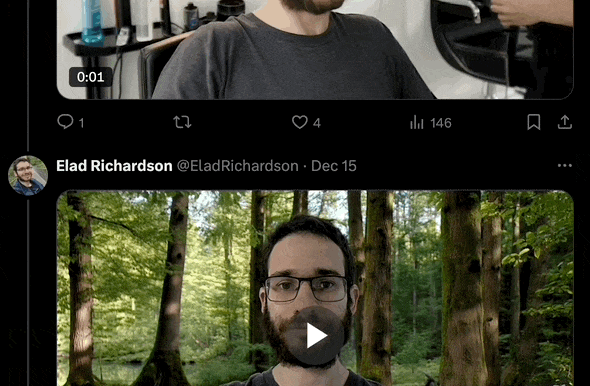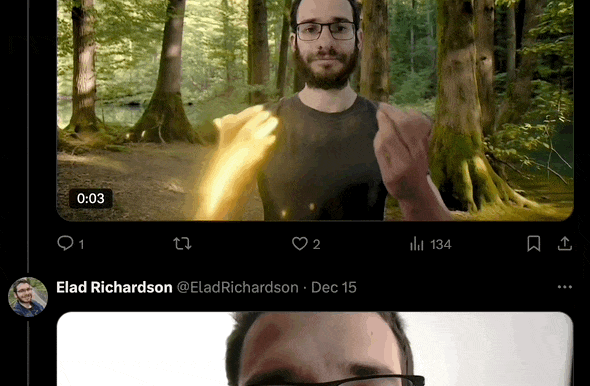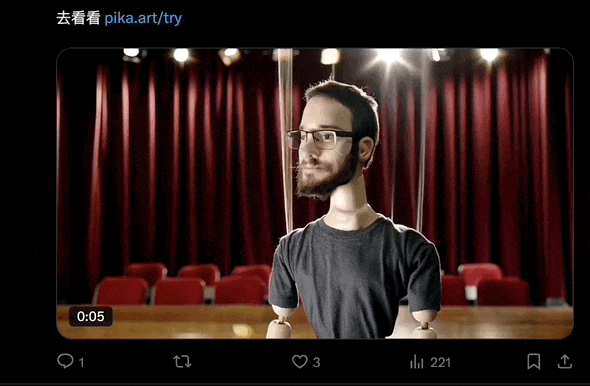
▲ 图片来自:X@EladRichardson
通过 AI 一键试衣,模特和衣服如流水,场景都不带换的,实拍的钱省下来了。

▲ 图片来自:X@martgent
玩着玩着,Pika 给了我一种玩「QQ 秀」和模拟人生的感觉,怎么打扮视频里的角色,我们来决定。
如果让马斯克「圆梦」,很容易,先用其他 AI 工具,生成了一件「占领火星」的 T 恤、一个写着「MAGA」的红色帽子。
然后,把这些图片、火星的场景、马斯克的照片,以及他的擎天柱人形机器人、他特别喜欢的网红表情包 Doge 原型,全部上传到 Pika。

▲提示词:一名男子站在火星表面,身穿黑色T恤,头戴红色帽子。他的左边坐着一只狗,右边站着一个机器人。镜头以广角镜头开始,捕捉男子、狗、机器人的全身。随着镜头平稳拉近,男子朝镜头欢快地挥手,表情洋溢着喜悦和冒险精神
最终,一个阳光开朗大男孩出现,左牵黄,右擎苍,憨厚有余,但就是不像马斯克。

像不像是一回事,只要思路开阔,玩法无穷无尽。
基于我们自己和名人的照片,可以无痛追星。上传帽子、衣服、乐器,能把自己从头打扮到脚。集齐场景、产品、模特,一个 5 毛特效的广告片子就有了……
照片+AI 图片+Pika 2.0+提示词,可以生成很多好玩的画面。同时,这样的生成方式也规避了一些视频模型的短板,比如写字,在图片模型就可以解决。
不和 Google 硬刚模型能力,不和 Runway 这种逐梦好莱坞的对手比较,Pika 有自己的弯道超车玩法。
其实一直以来,Pika 在整活和创意方面就是一把好手,之前的一系列 AI 特效功能 Pikaffect 全网爆火,刷屏小红书和 TikTok,推动 Pika 用户突破 1100 万。

▲ AI 捏捏. 图片来自:Pika

▲AI 切蛋糕. 图片来自:Pika
Pika 切中了一群对整活短视频有高需求的用户,哪怕这些视频是模板化的,稍纵即逝的,但只要有趣,人们就会蜂拥而至。
谁说赢者通吃才是胜利?AI 的市场是广阔的,模拟物理世界固然是个远大的梦想,先完成让 AI 短视频有趣起来的小目标,未尝不是一种成功的方式。





