






AI爆火两年,技术飞快跑,大模型突破商业化困局了吗?
自从 ChatGPT 横空出世,AI 的热潮已经席卷了两年。这两年,普通人对大语言模型的能力兴奋,随便一条指令就能生成流畅自然的文本,科幻电影里的场景,如今早已经成为现实。
大模型这个赛道也开始进入到一个十字路口,新技术如何转化为新产品,满足真需求,发展成新的商业生态。
如同移动支付、智能手机、 LTE 共同点燃了移动互联网时代的繁盛,AI 行业这一年也在寻找这样的 PMF(Product Market Fit)而焦虑。
新技术的大航海时代已经开启,到底能不能发现新大陆,这将决定大模型是不是又一个烧钱的资本游戏,是 .com 泡沫的加速重演,还是如黄仁勋所言的新工业革命开端,这个答案会比 AGI 更快让我们看到 。
大模型的大问题
今天,基座模型的竞争基本已经形成稳定的格局。由 OpenAI 领衔,旗下的 ChatGPT 也是稳居市场龙头。Anthropic,DeepMind,Llama,Grok,也各有各的长处。
于是,今年最热闹的,不是谁又多扩充了多少参数、响应速度提高了多少秒,而是大模型技术怎么化身为一个能用的产品。
大语言模型的技术怎么落地,从一开始就是个抓肝挠心的问题。哈佛商业评论曾经做过一个调查,发现生成式 AI 的应用——种类之繁杂,多达 100 类。

不过,在大类上就是五种:技术问题解决、内容生产及编辑、客户支持、学习和教育、艺术创作和调查研究。
知名的投资公司 a16z,给出了他们团队心中优秀的生成式 AI 产品,其中有不少眼熟的,比如通用类的 Perplexity,Claude,ChatGPT。也有更为垂直的,比如笔记类产品 Granola, Wispr Flow,Every Inc.,Cubby 等。还有教育赛道今年最大赢家 NotebookLM,或者是聊天机器人 Character.ai,Replika 等。
繁花锦绣是对于普通用户来说的:上面这些产品,绝大多数只是免费就足够用了,订阅版或 pro 版的费用,不是必须花的钱。强如ChatGPT,今年的订阅收入大概在每月 2.83 亿美元,与去年相比增长了两倍。但在巨大的成本面前,这点收入显得杯水车薪。
享受科技发展属于普通用户的开心事,烈火烹油是留给从业者的:再怎么激动人心的技术进化,也不能停留在实验室里,而是要进入商业社会接受检验。订阅模式没有被广泛接受,植入广告的时机还没有到来。留给大模型空烧钱的时间,已经很少了。
相比之下,toB 业务的走势让人有信心的多。
自 2018 年以来,财富 500 强财报电话会议中提及 AI 的次数几乎翻了一番。在所有财报电话会议中,19.7% 的记录提到最多的主题,就是生成式人工智能。
这也是整个行业的共识。根据中国信通院发布的《人工智能发展报告(2024 年)》蓝皮书,2026 年,超过 80%的企业将使用生成式人工智能 API,或者部署生成式的应用。

面向企业侧和消费侧的应用展现出不同的发展态势:面向消费侧,大模型应用讲究低门槛、创意性。而面向企业侧,大模型应用更注重专业定制和效益反馈。
换句话说,提升效益当然是每个企业都在追求、都想实现的,但只有这四个字太模糊了。大模型需要证明自己能实实在在地解决使用场景中的问题,真真切切地提升效益。
精准找到切角,让技术降落
无论是资源的投入,还是对开拓市场的力度,国内的大模型竞争,在整个 2024 年称得上激烈。
根据工信部数据,2023 年中国大语言模型市场规模增长率突破 100%,市场规模达到 147 亿元。各家厂商在商业化进程上积极尝试,首先打响的是价格战:以 tokens 计费、API 调用等方式的成本,正在被不断拉低。许多主流热门通用类大模型的价格,离白用已经没多远。
把价格打下、降低成本是更好实现的。而理解业务、分析切入场景,是一条更崎岖的路线。
不过,也不是每一家都在参与价格战,靠低价硬卷。
「在这种情况下,更重要的是找到我们的特点,发挥我们的优势。腾讯内部本身有很多场景,这些场景给了我们更多洞察,也进一步打磨了我们的能力」腾讯云智能 AI 产品专家、腾讯混元 ToB 产品负责人赵新宇这样认为,「往外看,聚焦一个行业,聚焦在这个行业内一些特定的场景,再慢慢拓展出去。」
在众多基座模型中,混元可能不是热度最高的一个,可在技术实力上却不容忽视。
九月时,混元发布的通用文生文模型混元 Turbo,采用全新的混合专家模型(MoE)结构。从语言理解和生成、逻辑推理、意图识别,到编码、长上下文和聚合任务中,都有相当强大的表现。在 11 月的动态更新版本中,已经升级为全系列效果最好的模型。目前,腾讯混元的能力正在通过腾讯云全面输出,通过提供多尺寸、多类型的模型,结合腾讯云智能其他的AI产品和能力,帮助模型应用落地到场景中。
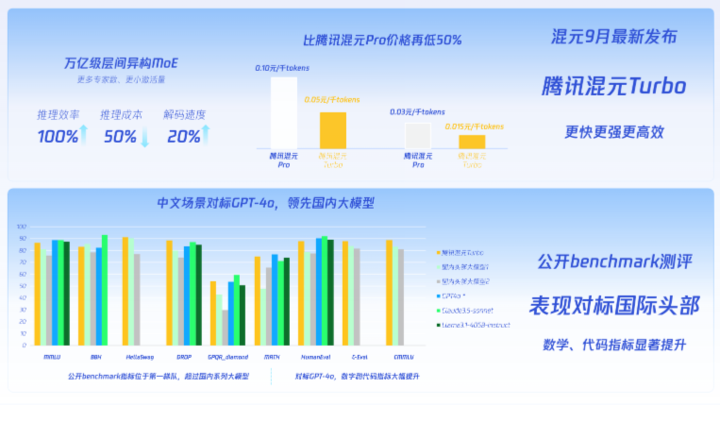
纵观目前模型应用落地形态,大致分为两种:严肃场景和娱乐场景。后者类似于聊天机器人、陪伴类应用等等。
而「严肃场景」,则指向企业核心业务运营中,对准确性和可靠性要求较高的应用场景。在这些场景中,大模型要承担结构化的信息处理,往往需要遵循预设的业务流程和质量标准,其应用效果,会直接关系到企业的运营效率和业务成果。
腾讯云曾经帮助一家外呼服务商构建客服体系,这是一个典型的严肃类场景。同时,外呼涉及到自然语言对话能力、内容理解和分析能力,看上去天然和大语言模型有极高的适配。
实际上,挑战都在细节之处。当时团队面临核心挑战有两个。一是性能问题,由于模型参数量巨大,达到 70B 或 300B 规模,如何在500毫秒内完成响应,并传递给下游 TTS 系统成为一个重要的技术难题。
二则是对话逻辑的准确程度。模型会在在一些对话中出现不合逻辑的回复,影响整体对话效果。为了克服这些挑战,项目团队采取了密集迭代的策略,在 1-2 个月的开发周期内,保持每周一个版本的快速迭代节奏。
企业客户对大语言模型技术展现出兴趣,并愿意进行创新尝试,但在技术与业务的深度融合方面,始终存在认知鸿沟。这并非源于企业对自身业务理解的不足,而是需要一个专业的技术团队,通过深入理解行业痛点和业务场景,找到最恰切的场景,为企业量身打造 AI 落地的方案,实现技术与业务的最优契合。
「传统的做法可能需要运营人员一个场景一个场景地搭建(语料库),」新宇介绍到,「而大模型,你只需要给一个 prompt,就可以实现需求了。」在摸清楚需求后,混元的团队几乎每周一个版本更新,「卷」起了迭代速度,一两个月下来,准确度已经达到了 95%。
对于这家外呼服务商,生成式技术完全是新鲜事物。而混元直接让他们看到了大模型所带来的效益,在人力方面的开支减少了四分之三。
「最好的做法就是把效果拿出来,」新宇说,当客户对生成式技术的了解有一点,但不多的时候,把效果摆出来是最有效的。通过客户的业务经历,找到可以切入的场景,直接去做测试验证,展示出可以提升的效果。
类似的经历,在体现和小米的合作中,这是一次被称为「双向奔赴」的合作。
对方希望在问答互动中引入大模型,把AI搜索的能力应用到端侧。这踩中了混元的两个长处:一是由腾讯丰富的内容生态所提供的支持;二是混元在 AI 搜索方面的能力。对于问答来说,准确率非常关键。
「一开始还是有很多困难的,」新宇回顾道,「从他们的角度来看,业务形态涵盖了多个场景,包括闲聊、知识问答等不同类型,其中知识问答场景,对准确率有比较高要求。」
通过前期的测试,混元团队明确了自己在搜索场景中的优势,双方一起将广泛意义上的问答互动,按照不同的话题层级逐步细化。这样的细分,能够让模型更清晰地了解各个场景的具体需求和效果要求,从而进行更有针对性的优化。
知识问答场景,成了那个降落点。在后续的实现上,混元需要攻克的挑战仍不少:时延问题不必多说,响应时间一定要快;其次是对搜索内容的整合。
「在整个链路当中,我们做了自建搜索引擎,还有一个意图分类模型,来判断是不是一个高时效性的提问。比如是不是跟新闻、时事相关的话题,然后再判断是该给到主模型还是 AI 搜索。」
只调用最需要的部分,这样一来响应速度能够大大提升。而一个重要的发现是, 70% 的问询都会引到 AI 搜索上,这意味着必须要有足够丰富的内容,作为最基础的调用支撑。
而混元背后,站着的是整个腾讯的内容生态。从新闻、音乐、金融,甚至医疗等更具体的领域,都能在腾讯的生态里找到海量的优质内容。这些都是混元模型在搜索时,可以触达和引用的数据,也是独一无二的壁垒。
经过历时两个多月的高强度迭代,最终无论是回答的质量、响应和性能等方面,都完全实现了需求,上线到了小米的实际业务中。
toB 业务的要义便在于此,能够实现营收、能够赢得信任,需要实实在在给客户的业务带来价值。
「卷」泛化,才能走向更多场景
大模型在不同行业和产品的落地中,实际上也在促进技术自身的成长。
对于一部分大模型产品而言,选择 toC 的路径有一个核心考量:用 C 端的反馈来优化模型。大模型对调优的需求没有尽头,而 C 端消费群的数量和活跃度,为模型的迭代提供了养料。这样一来,迭代的飞轮就能跑起来。
实际上,这在 toB 业务中也会实现,甚至要求更高。
「少年得到」的 K12 语文作文批改功能,应用了混元的多模态能力。结合腾讯云智能的 OCR 技术,识别学生的作文内容,并根据设置好的评分标准,由大模型为作文打分。

通常,大模型和真人教师判分,差值在五分内就很好了——可这并不容易实现。一开始混元的评分和真人教师的评分,差值小于五分的情况,只有 80%。
「模型有一定方法和能力,能够解决一些场景里的问题。但是聚焦到一个具体客户的业务上,对这个效果有更高的要求。」新宇说,「可能 90%的准确度可以达成业务目标,但只有 70% 和 80% 的时候,就有一定距离。」
这意味着还要继续「卷」下去。随着服务企业客户群体的不断扩大,对技术本身也提出了新要求:首先是迭代速度的大幅提升——面向 C 端用户时,迭代可能需要一到两个月。而现在,每周都能出现一个版本,这种高频迭代节奏极大促进了模型的成长和进步。
其次,通过持续服务不同企业场景,也显著增强了模型的泛化能力。这表明,深入服务多元化的企业需求不仅加快了模型开发迭代的节奏,也提高了模型的实用性和适应性,可以从严肃场景,拓展到偏娱乐向的场景中。
刚刚获得千万级 A 轮融资的角色扮演内容平台「造梦次元」,应用到了混元大模型的角色扮演专属模型Hunyuan-role,定位于服务年轻用户,结合生成式 AI 技术,提供交互式、剧情化的虚拟角色互动体验。
Hunyuan-role 开创了一种全新的人机交互方式。通过塑造丰富多样的虚拟角色形象,并基于预设的剧情背景和人物设定,与用户展开自然流畅的互动对话。
在技术层面,这样的场景应用到了 Hunyuan-role 在长短文本对话处理、意图识别和响应等方面都展现出领先优势,能够胜任多样化的应用场景,并且展现出了出色的内容拟人化能力——不仅能够进行有温度的对话互动,还可以推进故事情节发展,营造沉浸式的用户体验。
这些特性使得 Hunyuan-role 成为产品获客和用户运营的有力工具,在提升用户留存率和使用粘性方面发挥着重要作用。同样也反映出,在严肃场景得到锻炼和提升的混元,从而形成的泛化能力,可以覆盖到更广阔的场景,乃至在端侧的应用。
从严肃场景,逐步扩展到娱乐、创意,乃至更多的场景,是大模型应用必须走上的征程。
随着技术的成熟和成本的降低,大模型势必要向更广泛的应用场景扩展。原先聚焦于严肃的商业场景,如企业办公、数据分析、科研等行业,因为这些场景具有明确的需求和较高的支付意愿。
进一步拓展到娱乐、创意、内容生产等行当中,需要在思路上有一个锚点:始终以解决具体场景中的需求点为核心目标,锚定融合大模型能力的切入点。
除了与应用软件的合作,也需要有和硬件厂商的合作,让模型在最靠近消费者的端侧有所施展与发挥,提供更贴近用户的日常生活,提供更便捷、即时的服务体验。
这个过程中,市场对生成式 AI 技术的认知和接受度在不断提高,用户基数也在持续扩大。面对这种快速变化的市场环境,模型的迭代能力变得尤为重要。这不仅体现在技术性能上,还包括对用户需求的理解、对不同场景的适应性等多个维度。只有那些能够快速学习、持续优化、不断适应新需求的模型和团队,才能在竞争中保持优势。
在不断覆盖更多场景的时候,也是在走向更多的终端消费者。随着市场整体对生成式技术的接受,潜在用户量会持续增加,一个能够快速迭代和自我提升的模型,才可以敏锐地适应变化,走得更稳、更远。





