






别再被 DeepSeek R1 本地部署割韭菜,我帮你把坑都踩遍了 | 附免费教程
买它!趁着过年有空学起来。
这个春节,DeepSeek 像一条鲶鱼搅动了海内外无数人的心弦。当硅谷还沉浸 DeepSeek 带来的震撼时,一场声势浩大的 AI「淘金热」也在逐渐渗透国内主流电商平台。
号称内置 DeepSeek 的智能键盘日销近百万,博主兜售的课程轻松日入五万,就连仿冒网站也如雨后春笋般冒出了 2650 个,惹得 DeepSeek 官方突发紧急声明。

人群中有焦虑者、有淘金者,还有更多怀揣期待的观望者,当打工人节后终于有时间静下心来体验这个 AI 神器时,得到的却是 DeepSeek R1 冰冷的回应:
服务器繁忙,请稍后再试。
得益于 DeepSeek 的开源策略,在焦躁的等待中,本地部署 DeepSeek R1 的教程也迅速在全网刷屏,甚至成为新一轮收割韭菜的 AI 秘籍。
今天,不用 998 ,也不用 98 ,我们给家人们送上一份本地部署 DeepSeek R1 的教程。
DeepSeek’s AI Model Just Upended the White-Hot US Power Market – Bloomberg
不过,部署了,但没完全部署。
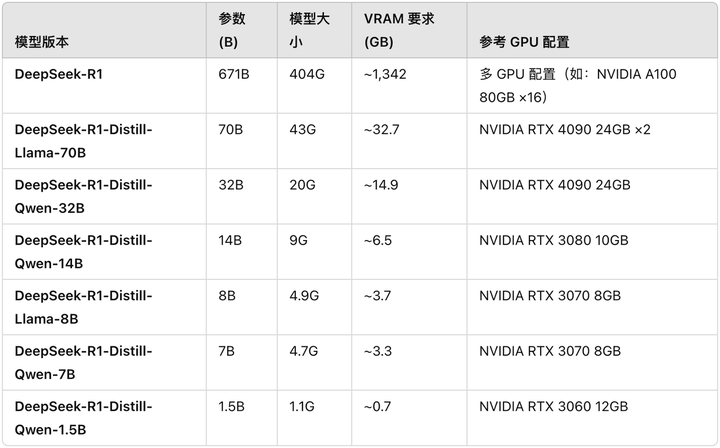
尽管许多卖课博主声称能轻松运行满血版 DeepSeek R1,但满血版 R1 模型参数高达 671B,仅模型文件就需要 404GB 存储空间,运行时更需要约 1300GB 显存。
对于没有卡的普通玩家来说,运行的条件苛刻,且门槛极高。基于此,我们不妨将目光转向 DeepSeek R1 四款分别对应 Qwen 和 Llama 的蒸馏小模型:
- DeepSeek-R1-Distill-Llama-8B
- DeepSeek-R1-Distill-Qwen-14B
- DeepSeek-R1-Distill-Qwen-32B
- DeepSeek-R1-Distill-Llama-70B
海外博主已经整理出相关配置供大家参考,注意,只要 GPU 等于或超过 VRAM 要求,模型仍然可以在规格较低的 GPU 上运行。但是设置不是最佳的,并且可能需要进行一些调整。
🔗 https://dev.to/askyt/deepseek-r1-671b-complete-hardware-requirements-optimal-deployment-setup-2e48
本地部署 R1 小模型,两种方法,一学就会
我们这次手上体验的设备正是 M1 Ultra 128GB 内存的 Mac Studio。关于主流本地部署 DeepSeek 的教程,两种方法,一学就会。
LM Studio
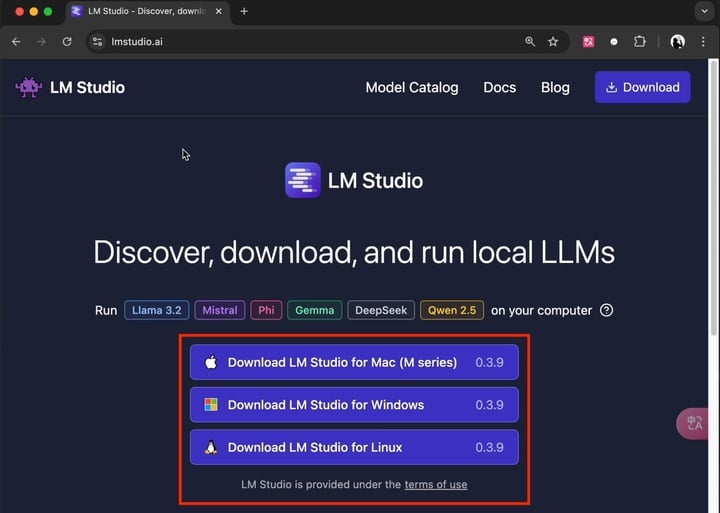
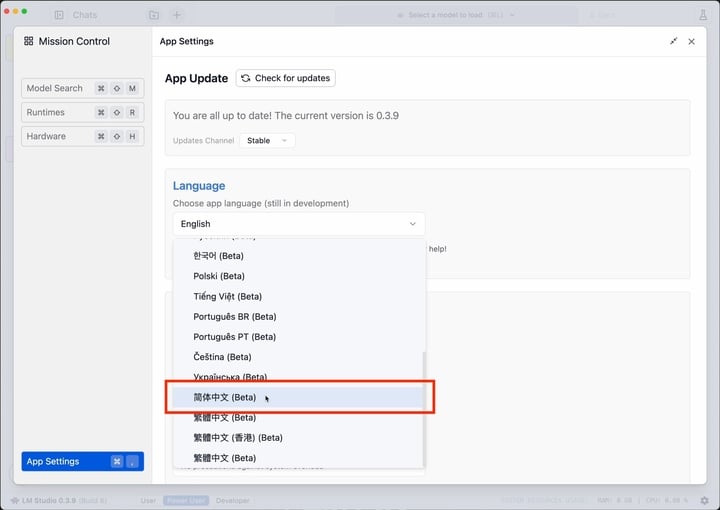
首先登场的是小白极简版本,在官网(lmstudio.ai)根据个人电脑型号下载 LM Studio,接着为了方便使用,建议点击右下角修改语言为简体中文。
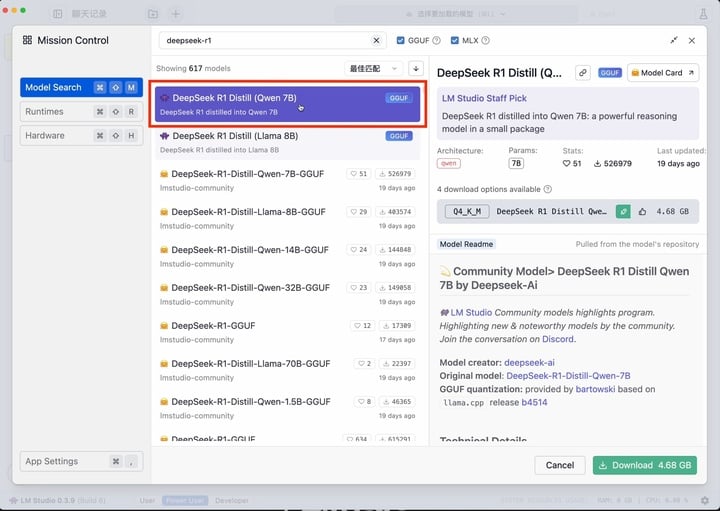
然后搜索 deepseek-r1 选择合适的版本下载,作为示例,我选择使用阿里 Qwen 模型为基座蒸馏出来的 7B 小模型。
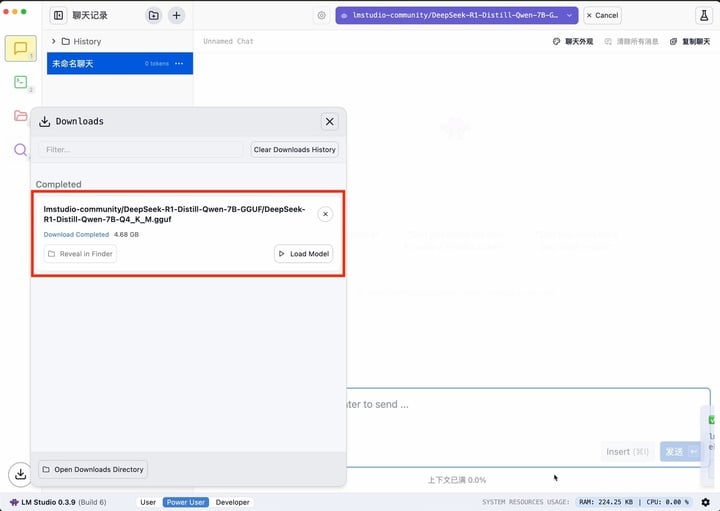
配置完成后,即可一键启动。
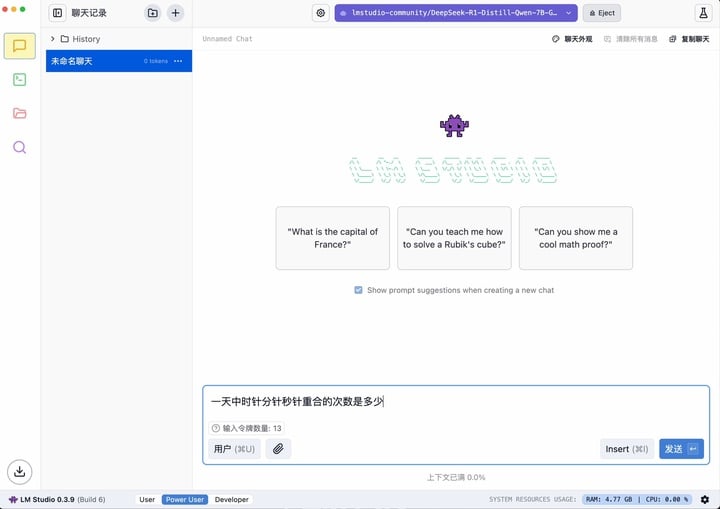
使用 LM Studio 的好处就是不用代码、界面友好,但跑大型模型的时候对性能要求高,因此更适合新手入门使用基础功能。
Ollama
当然,对于追求更深层次体验的用户,我们也准备了进阶方案。
首先从官网(ollama.com)获取并安装 Ollama。
启动后打开命令行工具。Mac 用户键盘 Command+空格 打开「终端」工具,Windows 用户键盘运行 Win+R ,输入 cmd 打开「命令提示符」工具。
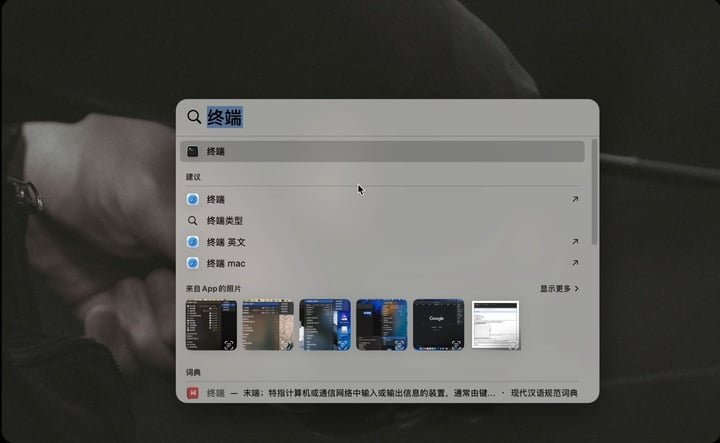
在窗口中输入代码指令(ollama run deepseek-r1:7b)即可开始下载。请注意英文状态输入,检查空格和横杠,冒号后输入所需要的版本名称。

配置完成后就能在命令行窗口开始对话。
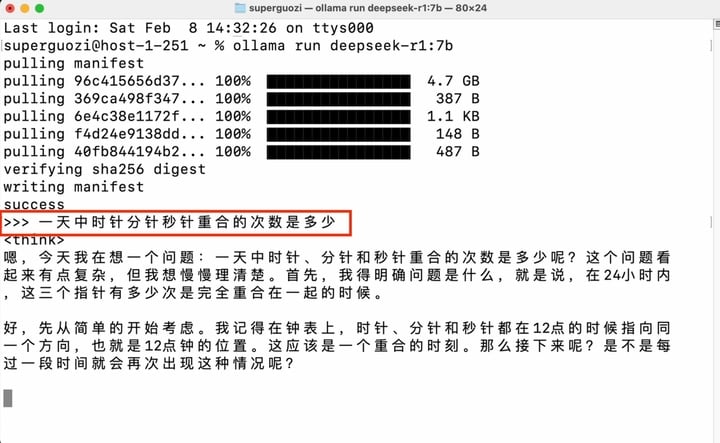
这个方法对性能要求很低,但需要熟悉命令行操作,模型的兼容性也有限,更适合进阶开发者实现高级操作。
如果你想要比较好看的交互界面,不妨在 Chrome 浏览器安装插件,搜索安装 PageAssist。

选择本地已安装的模型,开始使用。
右上角设置里修改好语言,主页选择模型就可以开始对话,而且支持基础的联网搜索,玩法也更多样。

能跑是能跑,但…
我们这次体验则用到了 LM Studio。
凭借其出色的优化能力,LM Studio 使得模型能够在消费级硬件上高效运行。比如 LM Studio 支持 GPU 卸载技术,可以将模型分块加载到 GPU 中,从而在显存有限的情况下实现加速。
如同调教赛车,每个参数都会影响最终的表现,在体验之前,建议在 LM Studio 的设置中,根据需求调整推理参数的能力,以优化模型的生成质量和计算资源分配。
- 温度 (Temperature):控制生成文本的随机性。
- 上下文溢出处理 (Context Overflow Handling):决定如何处理超长输入。
- CPU 线程:影响生成速度和资源占用。
- 采样策略:通过多种采样方法和惩罚机制,确保生成文本的合理性和多样性。
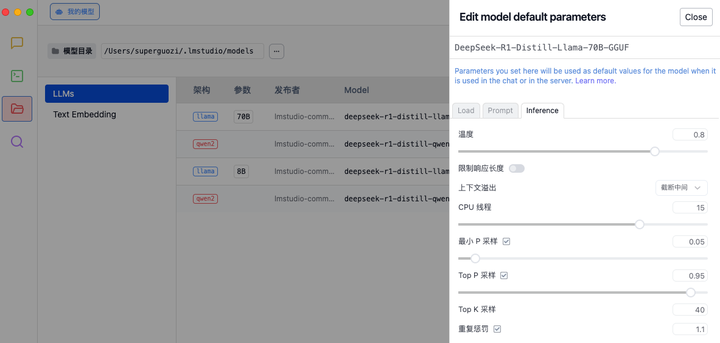
DeepSeek 研究员 Daya Guo 在 X 平台分享了他们内部的调教指南,最大生成长度锁定在 32768 个 token,温度值维持在 0.6,top-p 值定格在 0.95。每个测试都生成 64 个响应样本。
详细的配置建议如下:
1. 将温度设置在 0.5-0.7 之间(建议设置为 0.6),以防止模型输出无尽的重复或不连贯的内容。
2. 避免添加 system prompt,所有指令应包含在用户提示中。
3. 对于数学问题,建议在提示中包含指令,例如:「请逐步推理,并将最终答案放在 \boxed{} 中。」
4. 在评估模型性能时,建议进行多次测试,并取结果的平均值。
5. 此外,我们注意到 DeepSeek-R1 系列模型在响应某些查询时,可能会绕过思维模式(即输出 「\n\n」),这可能会影响模型的性能。为了确保模型进行充分的推理,我们建议在每次输出的开始,强制模型以 「\n」 开始其响应。
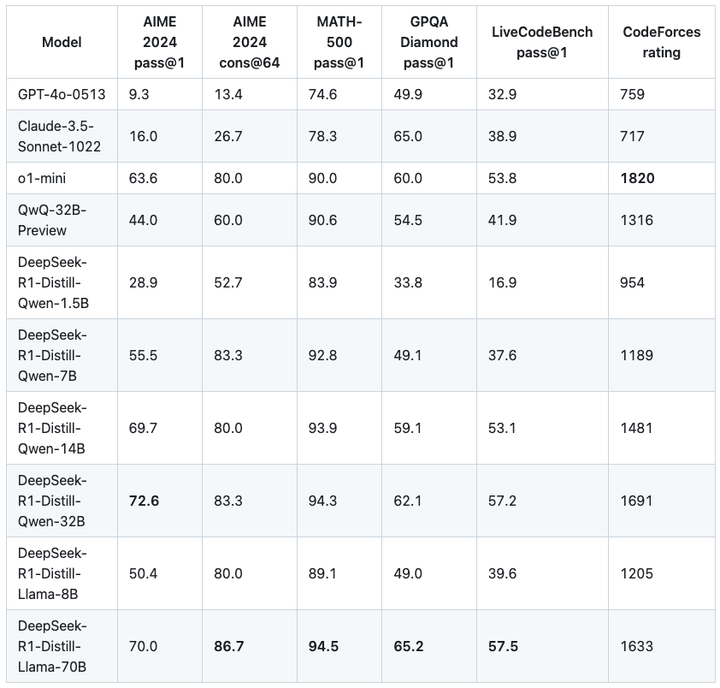
▲DeepSeek 官方给出的蒸馏版模型的评测对比
更大的参数量并不一定能带来更好的效果,在我们体验的这几款小模型中,相临参数量模型的实力差距整体倒也没有那么等级森严。我们也做了一些简单的测试。
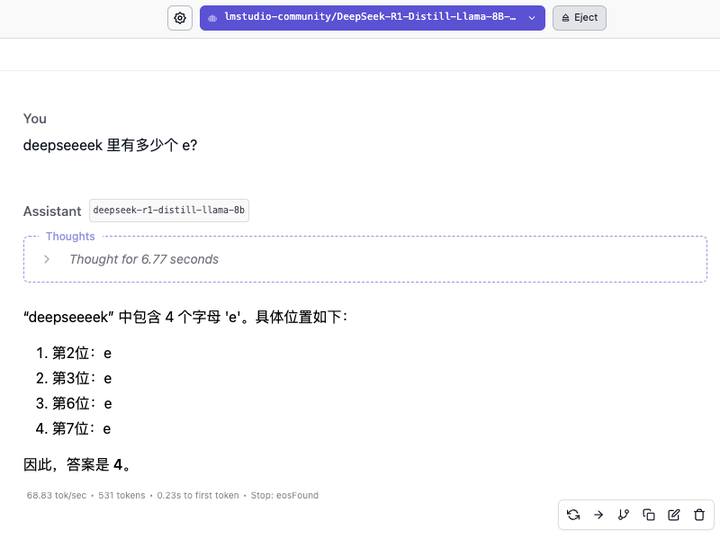

「deekseeeek 里有多少个 e?」
8B 模型的响应速度很快,基本能跑到 60 token/s,但答得快不意味着答得对,差之毫厘,谬以千里。思考过程显示,模型更像是基于知识库里的「DeepSeek」单词作出回答。

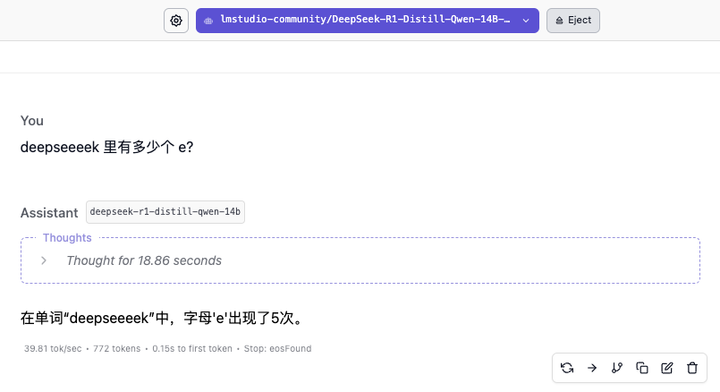
14B 模型也没答对。直到 32B 模型的出场,才终于看到了靠谱的答案。70B 模型展示出更缜密的推理过程,但同样回答错误。
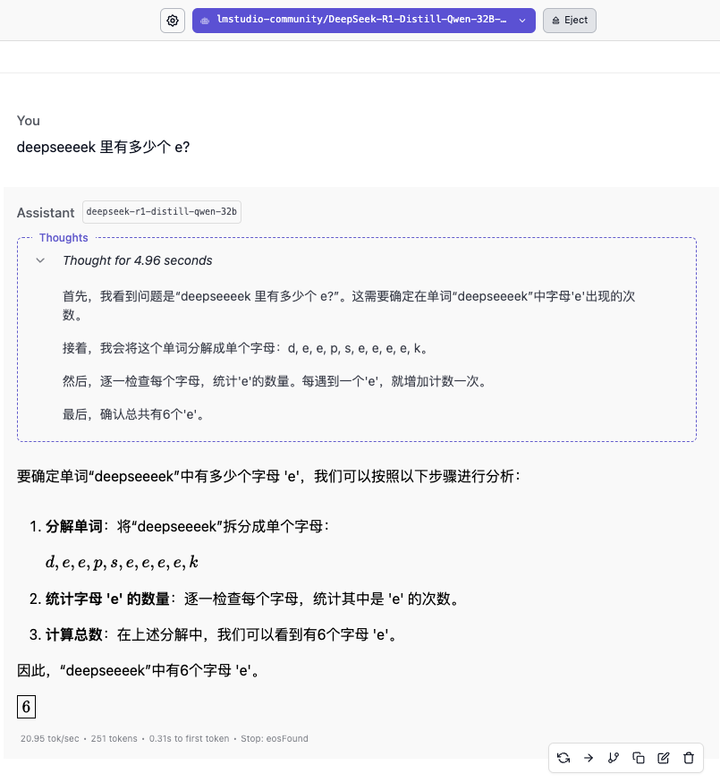
就该问题的回答质量来说,32B 和 70B 各有千秋,32B 在剧本场景的细节把控更完美,而 70B 则交出了一份角色饱满、剧情完整的答卷。
「在一天的 24 小时之中,时钟的时针、分针和秒针完全重合在一起的时候有几次?都分别是什么时间?你怎样算出来的?」

「某人在北半球某地乘飞机依次向正东、正北、正西、正南各飞行 2000 千米。最后,他能回到原地吗?」
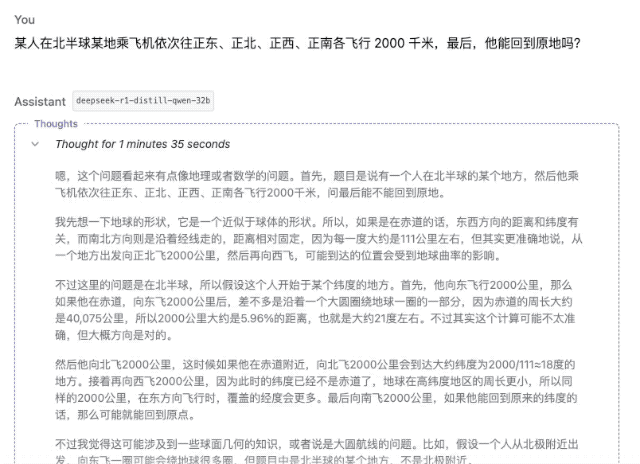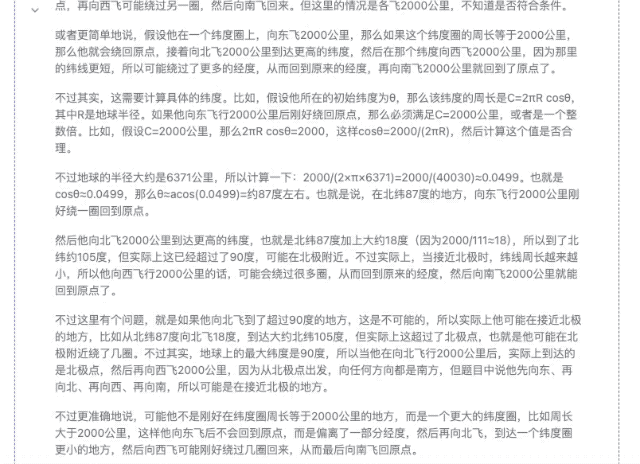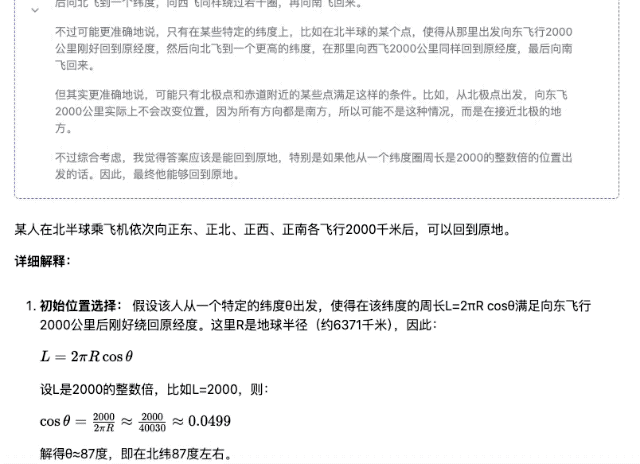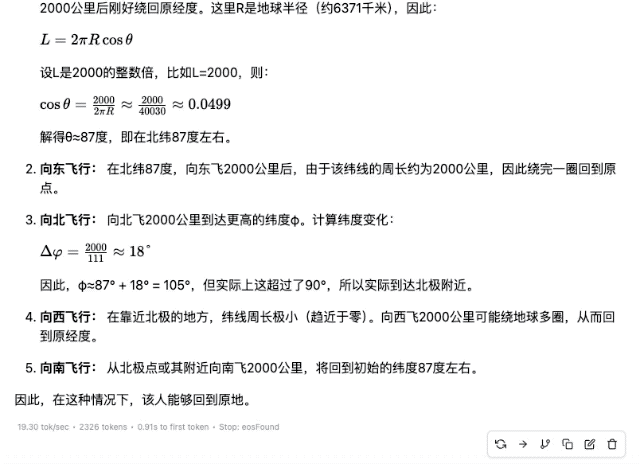
▲ DeepSeek-R1-Distill-Qwen-32B
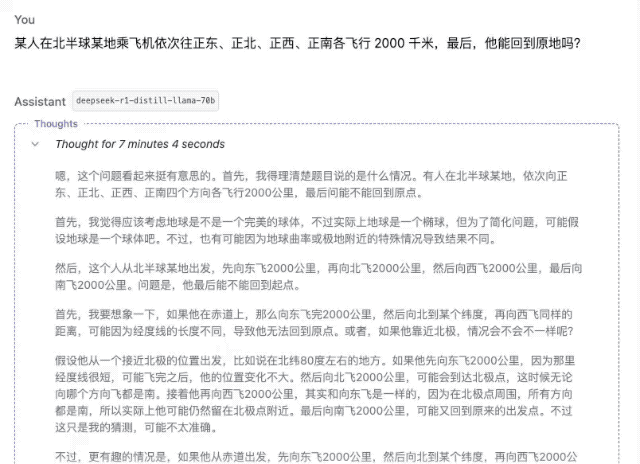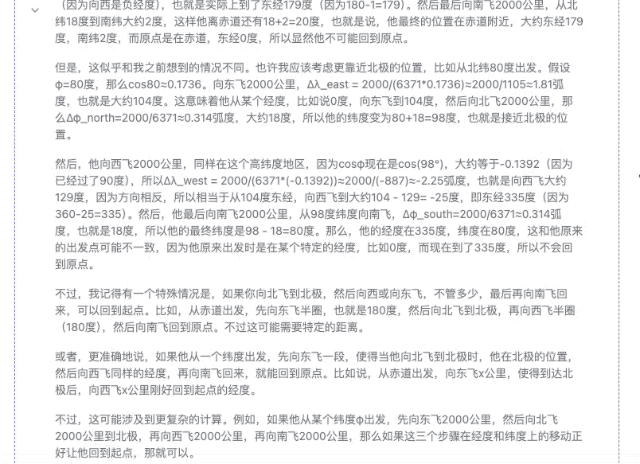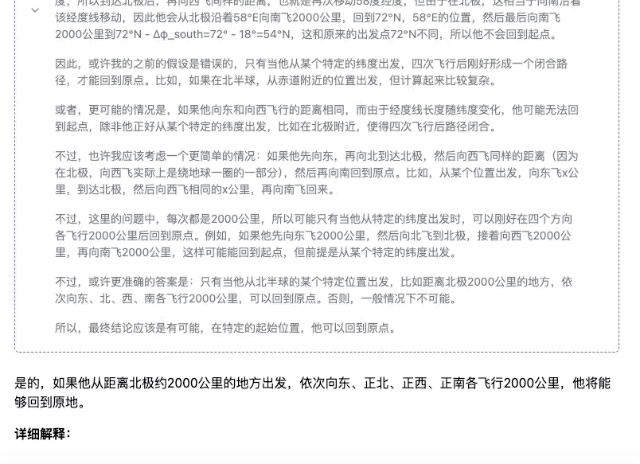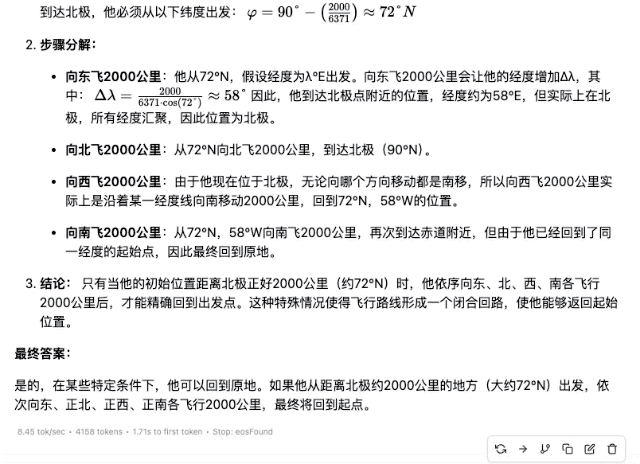
▲DeepSeek-R1-Distill-Llama-70B
当然,这几款模型中,参数越小的模型的回答准确率往往越低,即便思考过程摸着门道了,但后续也因不坚定而出错,遇上数学计算领域,不同量级模型的实力差距则会比较明显。
本地部署有三大优势,敏感数据无需上传云端;断网也能流畅使用;以及免除 API 调用费用,长文本任务更省钱,尤其适合企业、开发者及对隐私敏感的用户。
但不支持联网也有其弊端,如果你不喂给它「资料」,不及时更新知识库,那它的信息认知水平也会停滞不前。比方说知识库截止到 2024 年,那它就没法回答你最新的 AI 新闻。
本地部署最常用的功能当属打造自己的知识库,方法则是在安装 LM Studio 之后,增加与 Anything LLM 联动的部署步骤。
考虑到效果和适用性,我们使用了 32B 模型作为联动模型,结果显示效果也很一般,其中最大的挑战来自上下文窗口的限制。
依次输入只有 4000 字的文章和 1000 字左右的文章,前者回答依旧很迷糊,后者则能胜任,但处理 1000 字左右的文章稍显鸡肋,所以当个玩具还行,生产力还差点意思。

另外需要特别强调的是,一方面,撬开这四款模型的嘴难度极高,另一方面,我们也不建议大家去尝试「越狱」。网上虽然流传着许多所谓容易「越狱」的新版本模型,但出于安全和伦理考虑,我们并不建议随意部署。
不过,既然到这一步了,不妨再本着一窍通百窍通的原则,尝试下载和部署一些经过正规渠道发布的小模型。
那除了本地部署 R1 蒸馏小模型,满血版 R1 有没有穷鬼套餐呢?
Hugging Face 的工程师马修·卡里根前不久在 X 平台展示了运行完整 DeepSeek-R1 模型,Q8 量化,无蒸馏的硬件 + 软件设置,成本大约为 6000 美元。
附上完整配置链接:
https://x.com/carrigmat/status/1884244369907278106
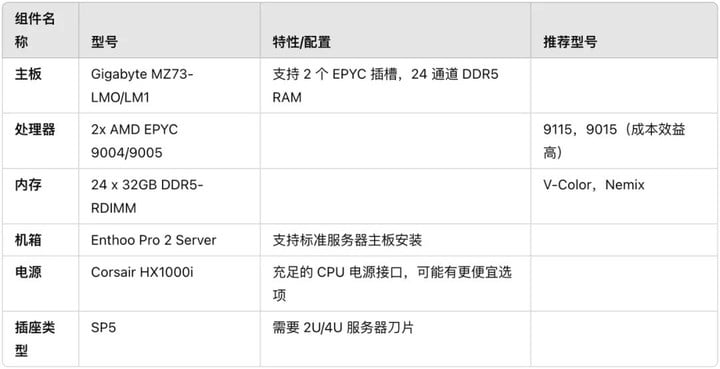
言归正传,所以我们真的需要本地部署一个蒸馏版的 DeepSeek R1 吗?
我的建议是不要将这几款 R1 蒸馏小模型想象成特斯拉,它充其量更像是五菱宏光,能跑是能跑,但要么性能表现相去甚远,要么缺胳膊少腿。
在本地部署最常用的自定义知识库能力的体验中,效果就不尽如人意。面对具体问题时,它无法准确「按图索骥」,或者干脆胡编乱造,准确率堪忧。
对绝大多数用户来说,老老实实用官方版或者使用第三方平台才是目前最优解,它不需要投入昂贵的硬件成本,也不用担心性能受限。
甚至折腾了半天,你会发现与其投入大量时间、精力和金钱去折腾本地部署这些小模型,不如下班后吃顿好的。
而对于企业用户、开发者或对数据隐私有特殊需求的用户,本地部署依然是一个值得考虑的选择,但前提是你清楚自己为什么需要它,以及它存在的各种局限性。
附上小白 QA 问答:
- 问: 我能在普通的电脑上部署 DeepSeek 吗?
答: DeepSeek 的完整版对电脑要求较高,但是,如果你只是想用它进行简单的操作,可以选择一些蒸馏小模型,不过仍需量力而行。 - 问:什么是 DeepSeek R1 的蒸馏版模型?
答: 蒸馏版模型是「简化」版本,硬件要求更低,运行起来速度也更快。 - 问: 我能在没有网络的情况下使用 DeepSeek 吗?
答: 如果你选择本地部署 DeepSeek,那么在没有互联网的情况下也能使用它。如果你通过云端或第三方平台使用,就需要网络连接才能访问。 - 问: 使用 DeepSeek 时,我的个人数据是否安全?
答: 如果你选择本地部署 DeepSeek,那么你的数据不会上传到云端,更加安全。如果使用在线版本,确保选择可信的服务平台,保护个人隐私。
作者:莫崇宇、Lin





