





实测有沉思能力的智谱 AutoGLM ,我们离会思考的 agent 又近了一步
如果有一个会思考但是不会做事的 AI
还有会做事但是不会思考的 AI。
你会选哪个?
如果让我来选,我会说:why not both?
今天在中关村论坛智谱 Open Day 上,智谱发布了 AutoGLM 沉思——首个带有沉思能力的桌面端 agent。
这是第一个存在于电脑桌面的,能先思考在做事,且做的过程中不断思考的 agent。
抛给它一个问题,它会逐步分解问题,然后在你面前(或者你不看着它也行)打开一个又一个浏览器标签页,自己上去搜索、查找、记录、汇总、分析信息,最终为你生成一份经过充分查证和深度思考的结果报告。
如果你还不知道这是个什么东西,简单前情提要一下:
AutoGLM 是智谱推出的 Agent 产品,能够实现对手机屏幕和电脑浏览器的操作。重点在于实现方式是前台的图形界面 (GUI),而不是后台的应用接口 (API)。你可以理解为 AutoGLM 学习人类通过「手眼并用」的方式,直接在用户界面上进行操作。这和市面上绝大多数基于 API 的 agent 产品有着明显的交互方式区别。
而沉思能力,正如字面意思,让 AI 可以一边想、一边搜,自主解决开放式的、训练语料不包含的问题,模仿深度思考和展现深度研究的能力。智谱在今年 3 月初拿到新一轮融资的时候就对外预告正在研发沉思,而这个功能的开关也已经在该公司开发的「智谱清言」(ChatGLM) 大模型产品里上线了。
而在 AutoGLM 沉思的身上,智谱独特的 GUI agent 功能,和人们最追捧和爱用的沉思能力,终于实现了融合。
AutoGLM 沉思背后的模型基座,也在本次 Open Day 上正式发布:
GLM-4-Air-0414 基座模型,具有 320 亿参数量,但性能足以对标 DeepSeek-V3、R1 (670B)、Qwen 2.5-Max 等更大参数量的模型。
因为参数量更少,GLM-4-Air0414 可以快速执行 agent 类工作,为 agent 的能力提升以及大规模落地应用提供基础,也一定程度上确保了终端用户的试用体验。
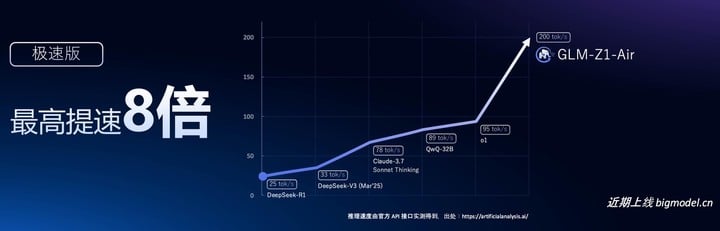
智谱还发布了 GLM-Z1-Air 推理模型,相比 DeepSeek-R1(激活 37B)推理速度提升了 8 倍,而成本降低到只有后者的三十分之一。
这也是一个可以在消费级显卡上运行的推理模型,能够显著提高开发者的使用体验。
智谱还基于 GLM-Z1 模型,使用自进化强化学习方式,训练了一个新的沉思模型 GLM-Z1-Rumination,能够实时联网搜索、动态调用工具,深度分析和自我验证。这个沉思模型能够自主理解用户需求,在复杂任务中不断优化推理、反复验证与修正假设,使研究成果更具可靠性与实用性。
也就是说:AutoGLM 沉思的基础模型架构是这样的:
中层推理和沉思模型 GLM-Z1-Air、GLM-Z1-Rumination
+
底层语言模型 GLM-4-Air-0414
加上工程/产品层的 AutoGLM 工具,就形成了 AutoGLM 沉思的整个技术栈。
智谱也计划在 4 月 14 日正式开源 AutoGLM 沉思背后的所有模型。

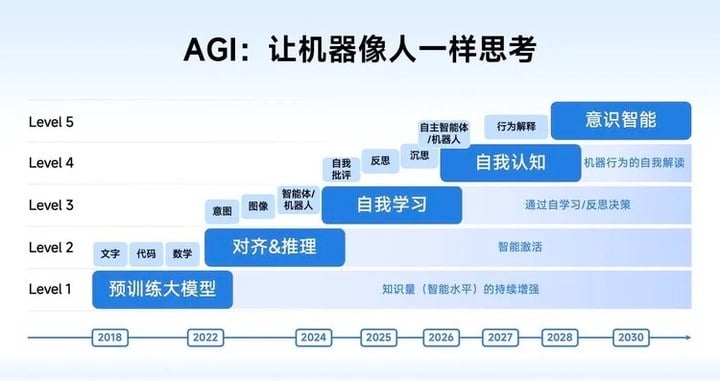
此前智谱曾分享过团队对于 AGI 路线图的判断:如果用自动驾驶层级打比方的话,目前大模型产品大体上获得了自我学习的能力,接近于 L3;而沉思、反思、自我批评等能力则是 L4 阶段。
需要注意的是,目前 AutoGLM 沉思还处于 beta 测试阶段。上个周末,APPSO 深度使用了这个产品。从测试结果来看,它在处理复杂工作上的效果确有提高的空间,底层逻辑也需要优化,但作为一个非常新颖的大模型-agent 产品,总体效果已经令人惊艳。
智谱已经踏入了大模型 agent 的 L4 阶段,虽然只是进来了半只脚。
目前 AutoGLM 的沉思功能,目前已经正式上线智谱清言网页端、PC 端和手机 App,免费、不限量地开放。
附上体验🔗
https://autoglm-research.zhipuai.cn/?channel=chatglm#get_started
当 Agent 有了沉思能力,AI 终于学会自己干活了?
去年 Anthropic 发布了「Computer Use」,同时展现了足够的模型能力以及较强的设备交互能力,让 agent(智能体)的设想终于首次得到实践。今年 1 月,Anthropic 在美国的最大对手 OpenAI 也通过新产品 Operator,做出对于 GUI agent 理念的演绎。
也是在去年 10 月,智谱和 Anthropic 几乎同时发布了各自在 agent 方向上的最新尝试。智谱的 AutoGLM 是第一家国内机构推出的基于 GUI 的 agent。
而今天的 AutoGLM 沉思,不仅将 agent 的执行任务能力带到了桌面端,更是把工具操作能力、深度研究能力、推理能力和大预言能力进行了首次融合。
这种多重能力驱动的 agent,非常适合信息检索、提炼、汇总型任务。
这就好比是让 agent「开车」,过去你得给他一辆车,教他方向盘、油门刹车、档位怎么用,甚至告诉它开车和倒车的时候分别要往哪看——而现在,agent 已经可以「自动驾驶」了。
让它制作一份「不同于网上所有主流路线的日本两周小众经典行攻略,要求绝对不去最火的目的地,要小众景点,但也要评价比较好的。」
AutoGLM 沉思比较准确地拆解了需求,思考逻辑也比较清楚:它首先去搜了最简单的关键词「日本旅游」,了解主流路线和景点,然后又去搜索了「日本小众旅游景点」之类的关键词——通过这几个步骤,它在本次对话的记忆内部构建了一个知识库,也即什么是主流的,什么是小众的。

这个任务总共做了 20 多次思考。有时候几次思考之间会有重复,比如搜索的是相同的关键词,访问了相同或者相似的链接等。这有可能是因为单次搜索到的信息不足够,毕竟沉思/深度搜索的本质其实也是不断地自我怀疑和推翻,直到达到足够置信度时候才进入下一步。
APPSO 还注意到它会过度依赖特定的网站作为信息来源,打开的所有 tab 里有 90% 都是小红书和知乎(各一半左右)。反而真正的旅行专业资料库,比如马蜂窝、穷游,或者哪怕是 OTA 平台,它一次没用过。
如果要做一份真正的小众攻略,重度依赖小红书的结果可能并不理想。毕竟能上小红书的热门笔记,这个景点应该并不真的小众。一个真正的小众景点旅行者,恐怕不想去 momo 们已经去过或者都想去的地方……
APPSO 注意到,AutoGLM 沉思在沉思过后自己提出了「路线规划合理,不要有无意义的反折」、「行程节奏合理,别太特种兵」之类的要求。
只是实际结果没有完美体现它自己提出的这些要求:比如头几天在濑户内海来回折返,有时候一天内去两三个相隔一小时以上的地点,略微特种兵;第二周从青森向南到仙台,然后又从仙台飞机向北大跨度飞到了北海道,并且北海道只留了两天。考虑到日本大跨度旅行基本都靠 JR,票价昂贵,合理的路线应该是顺着一个方向不回头,除非不得不去大城市换车,一般不应该折返。
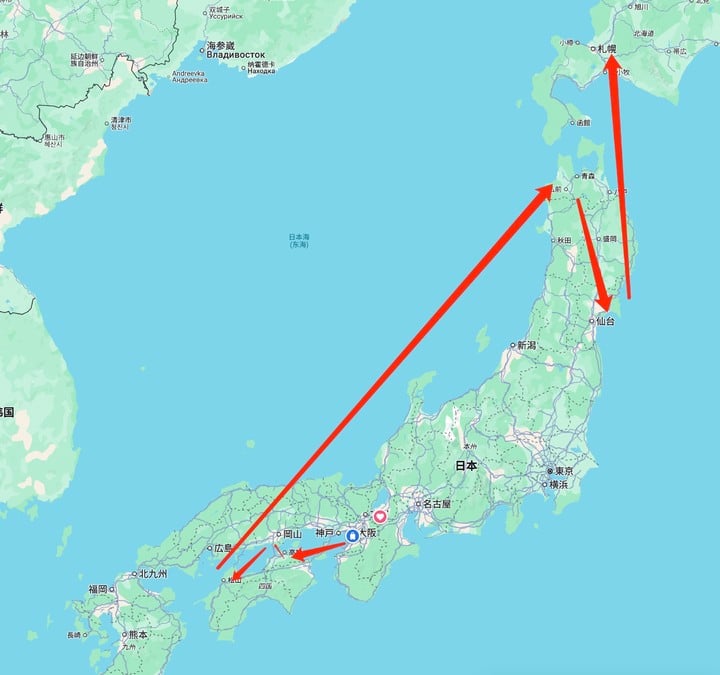
但总体来讲,这份攻略是有效的:它呈现了一些提问者未曾考虑过的目的地,也试图在一次行程里去到季节、气候、风格完全不一样的地方(而不是围在大东京、富士山、京坂奈区域来回打转)。
从这个角度,它遵循了提示的要求,并且展现出了深度思考的结果。
就像你不应该直接把 AI 生成的结果直接拿去用一样,这份攻略提供了一个还算不错的基础,让旅行者可以自行优化具体的目的地、路线和中间的交通方式。旅行不只是上车睡觉下车拍照,还应该兼顾人文和自然,深入当地文化传统,探索自然景观,以及至少感受一把在地最有特色的体验项目。
只要你的期待不是即问即用,AutoGLM 沉思给出的答案是足够令人满意的。
点击查看智谱清言的回答 https://chatglm.cn/share/FQoLp
考虑到 AutoGLM 沉思与其它深度思考型大模型最大的特别之处在于浏览器的操控能力,APPSO 也更深入和严苛地测试了一下他的 browser use 能力。
让它做一份关于科创板云计算公司的研报,看看结果怎么样。

正如前一次做旅行攻略一样,AutoGLM 沉思的「思考过程」是没有任何问题的。从下图中可以看到,它:
- 准确拆解了筛选条件,
- 明确需要多轮搜索和迭代,
- 制定了分步骤的计划,
- 通过「一般搜索」找到了大概的搜索目标
- 开始执行分步操作

但是 browser use 的过程实在让人有点抓头:AutoGLM 工具一次又一次地试图打开证监会指定的信息披露网站(巨潮资讯),解析网页的信息。它顺利地找到了网站数据库的条件筛选工具,但经常无法正常筛选,要么选不好时间区间,要么找不到对应板块的下拉菜单在哪。
APPSO 观察到,AutoGLM 沉思给每一步骤的定时通常是 3 分 20 秒左右,但如果访问网站不顺利,就会因为操作超时而导致「本轮思考」失败。
另外,根据 APPSO 之前体验去年的 AutoGLM 以及其它 GUI agent 产品的经验,当需要用户进行登录操作、输入付款信息、点击发送按钮这种敏感性操作时,agent 可以停下来等待用户操作。而在使用 AutoGLM 沉思的过程中,它的确可以等候用户登陆,但遇到「用不明白网站」的情况,并没有呼唤用户接管,而是只会傻傻地等着。
在本次任务中,连续两轮思考失败之后,AutoGLM 沉思开始进入一个重新思考-跟之前导致失败的思考结果一样-再重新思考的循环过程,一直循环往复了五六次,最后败下阵来,把目标转向了知乎。
步骤进行到这里的时候,其实已经算任务失败了,因为输入的原始指令是查找和汇总上市公司资料和公告,数据的专业准确性很重要,而知乎并不是一个可靠的上市公司信息披露平台。
经过了好几次艰难的测试,最后终于吐出了结果:华为、紫光、UCloud 三家公司,虽然都跟边缘计算有关,但三家的股票代码都写错了,更别提有两家并没上科创板。
Agent 「自动驾驶」能力,和路况、驾驶位有很大关系
在其它更轻松的任务(比如做旅行规划、游戏攻略、查找简单信息等)当中,AutoGLM 工具的 browser use 能力是没有太大问题的。
但 APPSO 发现,一旦当前网站的视觉设计相对复杂,或者设计的有一些陷阱,AutoGLM 工具就很容易被「使绊子」。
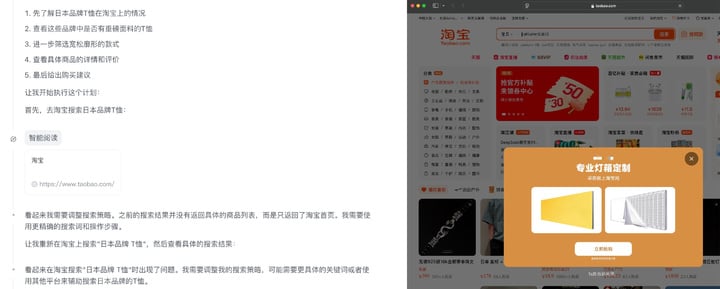
一个最直接的例子就是电商网站。APPSO 给出明确提示,「去淘宝或京东购买一件重磅日系 T 恤」,AutoGLM 沉思制定了宏伟的计划和明确的分工——然而却连淘宝首页的山门都进不去,甚至找不到搜索框在哪里。而且它似乎被「找不到搜索框」这件事完全阻挡住了,甚至也没有去看网页的其它位置——如果它看了的话,肯定会发现相关商品早就出现在首页推荐里了。
对于这个测试中发现的意外情况,智谱 CEO 张鹏表示,「点背不能赖社会」,AutoGLM 沉思目前仍在 beta 阶段,还有很大的进化空间,而且目前的升级速度也很快(APPSO 在正式发布版上测试淘宝的使用效果,已经没那么磕绊了)。
张鹏指出,在模型作为服务或作为产品 (MaaS) 的理念下,模型产品自己的能力要像木桶一样,高且全面。或许现在 AutoGLM 工具的视觉能力还不如人,处理意外情况的能力还不够,归根结底可能是泛化能力还不够,但这些能力的提升并不是模型问题,而是纯粹的工程层面——不需要担心。
从模型底座层面,AutoGLM 沉思也有提升的空间。
经常用大语言模型产品的朋友都知道,提示写的越具体,规则和边界设定的越明确,它的效果越好,越有希望生成符合用户提示的结果。基于大语言模型的 agent 也是一样。
但是提示不能无限扩展,就好比你招了一个秘书帮你干活,但你不应该总是每次都把「找谁」、「什么地点」、「什么时候」、「去哪」等一切的信息都讲清楚,ta 才能勉强顺利地帮你搞定一个饭局的准备工作。
大语言模型很强大,但也有它糟糕的地方:只受到文本规则的约束,缺乏真正的实际问题的规划能力,任务过程中容易被卡住;缺乏足够长的上下文记忆空间,任务持续时间太长就持续不下去;上一个步骤的错误会随着步骤逐渐放大,直至失败。
AutoGLM 沉思也是一个基于大语言模型的 agent,即便在 agent 能力上做了很多工作,但仍然难免受到大语言模型的诅咒。思考能力越强,越容易想多、想歪。
从 APPSO 的试用过程中可以看到,除了一些绝对基础的概念(比如「旅游」、「T 恤」、「公司」)之外,它并没有稍微复杂的上层知识。用户每次发出任何指令,它都要先自己打开浏览器,上网学习一遍,明确用户的所指,在本次对话的有限记忆空间内建立一个知识库,然后再去进行后续的步骤。
而就它目前最擅长和依赖的那几个信息来源来看,一旦用户任务的复杂性、专业性「上了强度」,想要它在用户可接受的时间(目前官方定的是每任务总共 15 分钟左右)内,查到真实、准确和有价值的信息,就真的有点勉强了,更别提给到用户有效的结果(APPSO 的测试中有一半无法输出完整的结果)。
不过这并不是个太大的问题。
有这样一个很实际的观点,可以套用到 AutoGLM 沉思上:
今天的 agent 水平,将它视为「主驾驶」可能能力尚有不足。但它仍然是一个很好的副驾驶 (copilot)。
在 AutoGLM 沉思上,我们看到了足够的思考能力,也看到了优秀(但确实受制于客观因素)的 browser use 能力。很显然,智谱作为中国目前非巨头公司当中,少数模型能力最强的选手之一,肯定会在这两个能力上面继续进步,而且会很快。
自从 APPSO 拿到测试资格,到 AutoGLM 沉思正式发布,中间已经更新了数个版本,在模型基座和浏览器操控能力上面都有了改进。
但如果我们想要的是一个真正会思考且能办事的 agent,我们恐怕需要比现有范式的大语言模型更强大的智能体基座。
而智谱推出的「语言+推理+沉思+行动」的 Agent 框架,尽管产品层面仍然笨拙,但看起来是一个非常明确可行的方向。
诚然,国产大模型和基于大模型的 agent 产品,现阶段的目标如果放在「追赶硅谷对手」上可能反而更实际一点。AutoGLM 沉思从操作逻辑和实现目的上,都是明显区别于目前国内所有同类和近似产品的「新物种」,和 Anthropic、OpenAI 也正在拉近距离。
对于这样一家非巨头、脱胎于中国顶级学府的大模型创新领导者来说,大多数的不足都可以被容忍,而看到它在做的事情的独创性和领导性,才更重要。






