






还记得爱范儿 08 年的模样么?
借赫拉克利特一句名言来说:我们不能两次浏览同一个网站。现实世界是不断变化的,而在映射现实的网络世界,每一个网站也是在不断变化的:更新、改版、倒闭。
现实世界中,我们可以拍照将过去定格在方寸之间。而在网络世界呢?爱范儿创立于 2008 年,今天有多少读者见过那时的爱范儿?有没有人给 08 年的爱范儿拍过照?
还真有“摄影师”给 08 年的爱范儿留了影:

“网站时光机”
这位“摄影师”英文名叫 The Wayback Machine,目前还没有一个统一的中文称呼,我们暂且称作“网站时光机”。准确来说,这位“摄影师”其实是一位“存档员”,保存下来的不是一张网页截图,而是网站内容的备份文件。
“网站时光机”在本质上是一个网络爬虫机器人,它会自动抓取每一个它所能找到的网站,然后存档备份在服务器中,但抓取每个网站的日期和频率并不一样。下图显示了“网站时光机” 2013 年抓取爱范儿网站的日期和频率,淡蓝色半透明圆圈表示当天有抓取,而圆圈越大,当天抓取频率越高。
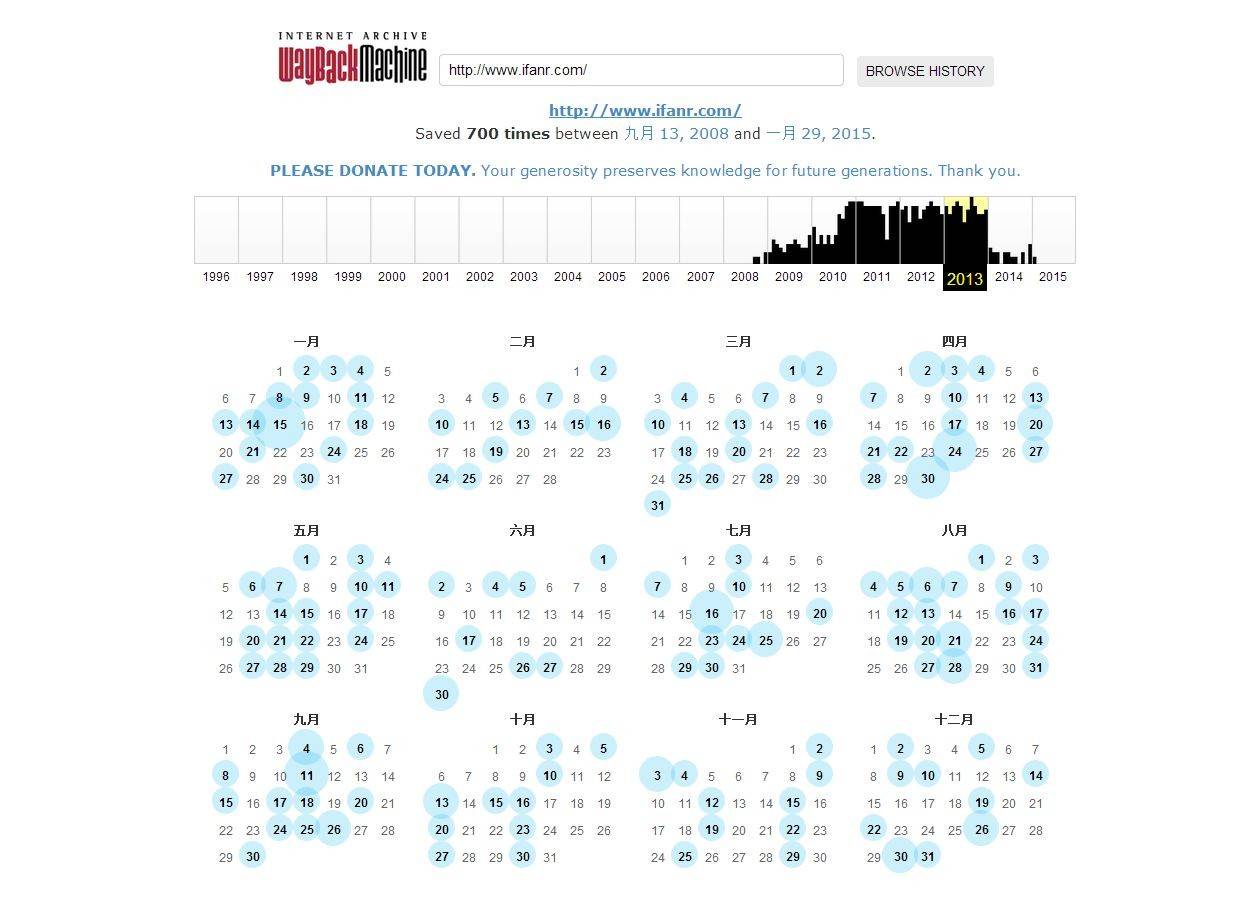
除了自动抓取,“网站时光机”还设置了“立即保存页面(Save Page Now)”的功能。每个人都可在任何时候自行填写网址,提交时刻网站的内容就会被保存在“网站时光机”的服务器中。
死链——信息的黑洞
看起来,“网站时光机”是一个锦上添花的存在:通过它,我们可以看到一个网站以前的样子,要是没有这东西,对我们的生活也没有什么影响。但事实是,“网站时光机”是对当下互联网最普遍的 HTTP 协议的打的一个重要补丁。
1989 年,蒂姆·伯纳斯-李提出了 HTTP 协议,并在此基础上发展出万维网(World Wide Web),当时他并没有太把网站的历史版本当一回事:
万维网还这么年轻,我的首要任务是让它更加普及,没那么多精力去考虑网站更替的问题。
随着万维网快速普及,几乎所有人都会经常使用链接,引用网页已经成为司空见惯的事情。很多网站会利用超链接提供给读者更多信息,作家、律师和编辑也都习惯在脚注中标注引用的链接,但却很少考虑过这些链接以后还会不会指向原先的页面。
由于网页内容更新、改版和倒闭等种种原因,许多链接都不断失效,失效的链接一般称之为死链。HTTP 协议却没有太好的办法去解决这个问题,Google 首席互联网传教士 Vint Cerf 是参与构建互联网基础框架的一员,他曾感慨死链对信息传播危害:
21 世纪也许会变成一个信息黑洞。

2013 年一份对法律和政策出版物的调查发现,大多数出版了 6 年的书刊,里面引用的 50% 的链接都成为了死链。而 2014 年一份在哈佛法律学院进行的研究同样表明链接的脆弱性:《哈佛法律评论》超过 70% 的链接都已失效。
“网站时光机”的存在提供了解决引用链接失效问题的一种方法。当我们在一篇正式的文章上引用一个链接时,为了预防链接失效,可通过“网站时光机”的“立即保存页面”功能,将链接的网站备份到服务器中。
另一种方法是 Perma.cc。
Perma.cc 于 2014 年正式上线,致力于“创造永远不会失效的引用链接”,其工作原理类似“网站时光机”的“立即保存页面”功能。用户在提交了链接之后,Perma.cc 的服务器会将链接指向的网页存档,并生成一个带有“perma.cc”前缀的链接(permalink),像这样:http://perma.cc/YG84-H3JX。
目前已经有很多法律刊物和联邦法院采用 Perma.cc 来解决链接失效的问题,这其中就包括上面提到的《哈佛法律评论》。在网络世界中,“网站时光机”和 Perma.cc 都站在了赫拉克利特的对立面:通过技术手段,我们是可以两次浏览同一个网站的。

布鲁斯特·卡利和他的数字乌托邦
“网站时光机”现已存档了 4520 亿个网页,这个数字还在不断攀升中。而在背后支持着“网站时光机”这一壮举的是一个叫互联网档案馆(the Internet Archive)的非营利性机构。
1996 年,布鲁斯特·卡利(Brewster Kahle)怀着“每个人都能获取所有知识”的愿景创办了互联网档案馆:
我对当今的互联网感到失望。互联网是一个巨大的图书馆,人人皆可拥有,而不应该被大型商业公司所控制。我建立了一个非营利性质的互联网档案馆,存放着大量的电子书、电影、电视剧和音乐音频等人类共享的知识成果。图书馆是开放给所有人的,互联网档案馆也应该开放给所有人。
创办之初,这位数字乌托邦主义者给了同事们人手一本《消失的图书馆》,这本书述说了已经烧毁的亚历山大图书馆的历史。亚历山大图书馆曾是世界上最大的图书馆,史学家穆斯塔法·阿巴迪(Mostafa El-abbadi)教授曾这样评价这座人类知识传承历史上的里程碑:
在亚历山大图书馆建成之前,知识在很大程度上只是地区性的,但自从有了这第一座国际性的图书馆后,知识也就变成国际性的了。

卡利的野心是建立第二个亚历山大图书馆。事实上,互联网的发明也得益于人类对图书馆的思考。
1961 年,一位在波特-贝拉尼克和纽曼公司工作的科学家 J. C. R. 利克莱德( J. C. R. Licklider)开始了一项关于图书馆未来的研究:
实体书长于展示信息,但不利于存储、组织和检索信息。研究的方向是想象中图书馆在 2000 年的模样。
后来这位利克莱德成为美国国防部高级研究计划署( the Department of Defense’s Advanced Research Projects Agency,以下简称 ARPA)的负责人,发表了一份名为《未来的图书馆》的报告,并提出“星际计算机网络”的愿景。
据估计,他在任期间,整个美国计算机科学领域研究的 70% 都由 ARPA 赞助。20 世纪 70 年代中,ARPA 成为全球互联网的始祖的诞生地。
如今,数字化信息的存储、组织和检索都变得非常方便,卡利则接过利克莱德的衣钵,继续为打造一个乌托邦式的数字图书馆而努力。
互联网档案馆的功与失
事实上,互联网档案馆还曾在破获马航 MH17 袭机案中立功。
格林尼治时间 2014 年 7 月 17 日,马来西亚航空公司的 MH17 航班坠毁在乌克兰顿涅茨克的郊外,机上 298 人全部遇难。
当天下午 2:50,乌克兰亲俄武装领袖伊格•吉尔金(Igor Girkin)在俄罗斯社交网站 VKontakte 上发了一条消息:“我们刚刚击落了一家飞机,一架 AN-26。”还附带了视频链接,从视频中可以看到飞机残骸,看起来很像是波音 777 。吉尔金两小时后删除了这条消息。
然而吉尔金没有想到,他的 VKontakte 主页在两个周前被斯坦福大学胡佛研究所的阿纳托尔•舒梅列夫(Anatol Shmelev)提交到了互联网档案馆中:
吉尔金是乌克兰冲突中最重要的人物之一,他的页面应当每天记录两次。
互联网档案馆的“网站时光机”把吉尔金的 VKontakte 主页存了档,当然也包括他那条击落飞机的消息。MH17 坠落的第二天,美国驻联合国大使萨曼莎•鲍尔(Smantha Power)在纽约对联合国安理会表示,乌克兰分裂分子领导人“在社交网络上炫耀自己击落了一架飞机,但这些信息后来删除了。”
“网站时光机”的负责人在“互联网档案馆”的 Facebook 主页上发了一条消息:
这正是我们存在的意义。
尽管“网站时光机”能解决死链的问题,并且还在破案中立过功,但并不是所有人都喜欢它。
人们总会因为各种各样的原因不希望自己在互联网上的痕迹被永久存档,可能是发布的内容出现了错误,可能是和现在的流行观点相悖,也可能仅仅是因为过去的内容看起来很蠢。Buzzfeed 就曾删除了旗下超过 4000 位作者早先的文章,理由是现在看回去,那些内容越看越觉得蠢。
事实上,只需要在网站服务器根目录处添加一个简单的文本文件——“robots.txt”,“网站时光机”就会停止抓取这个网站的内容,而且还将移除掉该网站以往抓取过的版本。

互联网档案馆存档的大量数字内容也招受不少质疑。由互联网档案馆支持的美国国会图书馆保存了 Twitter 将所有推文,美国作家安迪•波罗维茨(Andy Borowitz)曾讽刺道:
国会图书馆收录了整个Twitter档案,它应改名为“废话博物馆”。
《纽约客》的作者 Jill Lepore 在探访了互联网档案馆位于旧金山芬斯顿大街 300 号的总部之后,写了一篇介绍互联网档案资料馆的长文。Lepore 在文章中里表达了这样的忧虑:
说实话,网上的多数东西难道不都是垃圾吗?如果一切都被保存下来,是否会过犹不及,变得毫无用处?
不管外界如何评价,布鲁斯特·卡利和他的数字乌托邦依旧忠实地保存着互联网的历史。一切我们现在看似无用之物,或许会在未来时间长河的某一处发光发亮。“网站时光机”在 MH17 袭机案中提供的帮助就是一个很好的证明:
这正是我们存在的意义。
题图来自 Web Pages that Suck





