






AlphaGo 表现究竟如何?专业人士剖析围棋世纪大战第一场
本文转载自微信公众号“喆理围棋”,作者为李喆六段,曾多次获得全国围棋赛事亚军,有“天才型”少年的美称。本文原标题为“【火线速递】——李世石的策略与AlphaGo的弱点”,同时转载时已经获得作者同意。
这必将是载入史册的一天。
人机围棋巅峰大战第一局,人类输了。
赛前的预测,棋界绝大多数认为李世石必胜,科技界则大约是两派各半。
认为李世石必胜的一方并非全都是出于傲慢无知,更多人不能相信的只是——这么快。科技界也有很多人了解算法之后认为 AlphaGo 还不足以战胜人类
从去年 10 月的五盘棋谱,到谷歌公开的论文,人们认为围棋 AI 仍然存在弱点,存在不能在这么短的时间内解决的问题,而这些问题将会导致 AI 在巅峰对决中失利。
然而,
李世石输了。
关于这盘棋,会有很多解读。不止在今天,甚至在数十年之后,这盘棋还可能会被拿出来研究,从棋谱上,更从人机不同的思维上。不论未来回看这盘棋的是人类还是真正有了自我意识的 AI,想必都会有与当下的我们不同的感受。而我们有义务把我们的感受和思考记录下来,让后人知道当时的人究竟是如何理解这盘棋,他们有哪些错误的认识、可笑的想法,又有哪些深刻的洞察。
我们来看看,今天这盘棋,究竟发生了什么。这盘棋可能将是有史以来职业棋手最难以统一意见的对局,以下观点是我个人见解,只是在围棋AI时代毫无预兆迅猛而来时,一名棋手尽可能理性的分析和思考。
一、李世石的针对性策略
从棋谱来看,我认为李世石在这盘棋前后主要使用了一个试探,和两个策略。
1)试探:从未出现过的布局
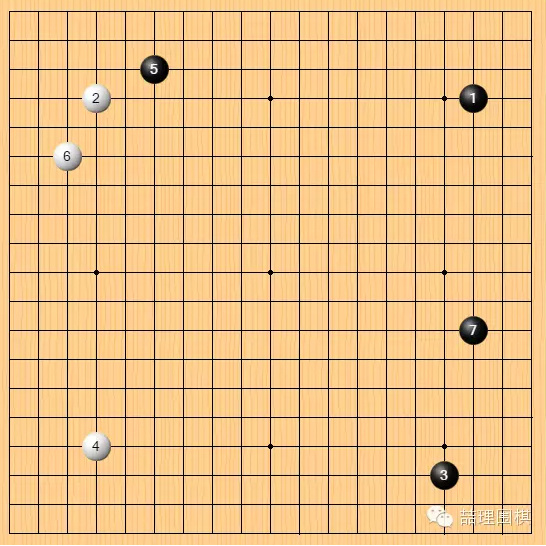
李世石第 7 手,没有按常规布局在上边连片,而选择走在右边。李世石自己在职业比赛中从未使用过这一开局,甚至整个职业围棋界,没有人见过这一开局。
李世石不按常规布局,显然是对电脑的一种试探。在去年 10 月 AlphaGo 对樊麾的五盘棋中,所有开局都是常规布局,虽然那五盘的开局在今天已经不是主流,但都是曾经流行一时的布局。
避开流行布局,甚至避开曾经流行过的已经被淘汰的布局,选择一个从未出现过的布局。李世石在考验 AlphaGo 在布局阶段的应变能力。我们知道 AlphaGo 的深度学习基于大量已有对局的数据,那么,面对一个棋谱库里从未见过的布局,AlphaGo 你将如何应对?
AlphaGo 给出了完美的回答。
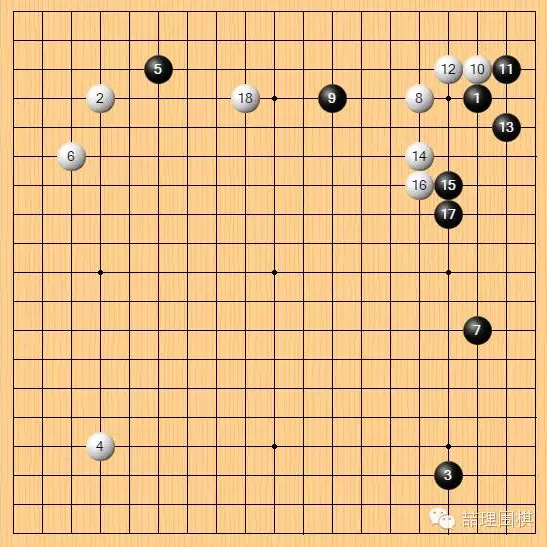
白 8 挂角正常,黑 9 二间高夹最为激烈。白 10,这一手……非常出色。
通常情况下,在右上白 8 遭遇二间高夹的时候,白 10 是“不存在”的一手,它不在任何定式之中。面对黑9,白棋有诸多定式选择,却没有白 10 这一手。
然而,我认为白 10 是好手。
白 10 的好处在于使黑7变成效率低下的一手,虽然在右上局部白棋稍稍亏损,但加上黑 7 的低效,白棋一点也不吃亏。
AI 竟然会通盘考虑!传统的围棋 AI,会根据已有棋谱来走定式,定式是经过长期检验的局部双方可以接受的定型。然而定式的弊端就在于,不同的周围环境,定式的适用性有所不同。从这盘棋来看,黑 9 夹击之后,白棋如果选择面对二间高夹最常用的“妖刀”定式,即走在 15 位,反而将使黑7的位置成为绝对的好点,黑 7 的效率将会大大提升。
实战白棋选择了一个定式里没有的、局部稍亏的、却使得黑7这个遥远棋子的效率变低的下法,非常清楚地证明了两点:
- 电脑不依靠背谱来下棋
- 电脑的考虑基于全局而非局部
当然,第一点其实在对樊麾的棋谱中已经可以看出来。在对樊麾的常规开局中,AI 出现了数次不同于“谱着”的下法。其中有一盘出现“大雪崩”定式,电脑选择的次序是定式和棋谱里没有的,而且是从逻辑上不如谱着的。注意,这里强调是逻辑上不如谱着,而不是在经验上。即,AI 当时的次序是“绝对弱于”谱着,只可能亏没可能便宜,虽然选点是正确的,但在我们看来是“次序错误”。这体现出,AlphaGo 不依赖于定式和谱着,但也暴露出 AI 在逻辑上的不足,反应在棋盘上就可能会出现次序错误。这一点,也是棋手普遍不看好 AI 能战胜李世石的一个原因。
但这一问题在这盘棋我们并没有看到。起码,没有非常明显地显现出来(后面会提到一个细微的类似问题)。
而第二点则是这盘棋 AI 开局给我们秀出的能力。他轻易摆脱了李世石设下的定式圈套,以全局的视野作出了定式中不存在的选择。
如果说第一点是我们在 AlphaGo 对樊麾时已经能够看到的情况,那么第二点则是这局棋在布局阶段对人类试探的完美答复。如果只依靠大量棋谱堆砌出来的局部图像识别,AI 做不出这样的选择。
2)策略一:开放式复杂局面
李世石第一次试探得到了 AI 的完美答复,然后李世石使用了他的一个重要策略。从局后来看,正是这一策略导致了李世石局面的被动,但在赛前,我们并未想到这一点。
我们不知道李世石在赛前有没有接受人工智能领域专家对 Alphago 算法的分析,但从李世石采取的策略来看,他显然有非常强的针对性。
我们知道,深度学习在围棋盘上的主要作用是大量剪枝,通过价值网络和策略网络,将搜索的空间大幅减小,形成“棋感”。在这个基础上,再辅以传统的蒙特卡洛算法做搜索计算,最终确定落子的选择。围棋中存在一些封闭的计算空间,比如局部的“死活题”,对于 AI 而言可以通过穷举来遍历每一个选点,从而完成计算,得出落子点。但围棋中更难的部分是开放式的复杂局面,每一处的不同选择都会波及到其它地方,所谓“牵一发而动全身”。而这种局面头绪繁多,可供思考的选点很多,不同选点之后变化的深度和广度都很大,并且往往一个细微的计算失误会导致整局棋的彻底失败。对于职业棋手而言,这种局面正是最难把握的局面之一。
赛前有人猜测,AlphaGo 的剪枝面对开放性复杂局面的效用将会降低,而搜索的深度广度和准确度要求又使得AI不能依靠蒙特卡洛算法达到精确,因此这很可能是基于深度学习和蒙特卡洛的围棋 AI 的一个弱点。
不论李世石是否了解到这些,总之他使用了一个策略:迅速导入开放式复杂局面。
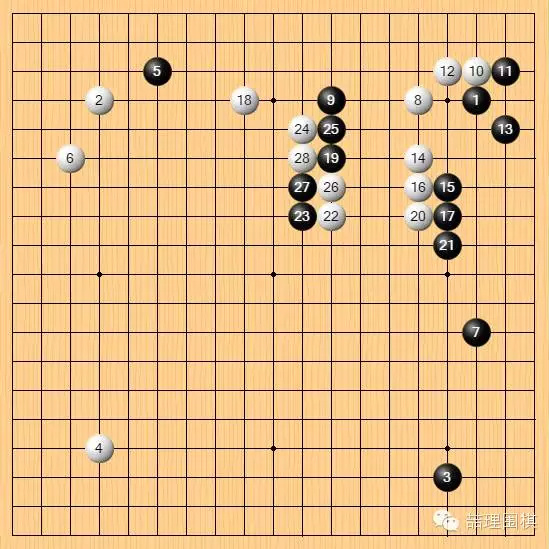
这里不做过于具体的技术分析。李世石第 23 手靠,和第 27 手挡,将局面导向了开放式复杂局面。原本李世石有更为柔和的选择,但他选择了最为强硬的下法。我们看到,AI 的白 24、26、28 是非常敏锐的战斗嗅觉,完全没有避战。
从我的经验来看,这个战斗是由黑方挑起的,而黑方挑起战斗的时机并不成熟。在势均力敌的对局中,我们往往会试图在认为有超过 50% 成功率的时机选择战斗,只是棋手有力战派和稳健派的分别,力战派对于战斗的判断会更为乐观一些。
李世石是偏力战的棋手。但在本局中,这一开战时机仍然是过早了,可以说是立足未稳时冲向了敌营。我相信在对手是人的情况下李世石通常不会如此选择,他会寻找一个更合适的时机展开战斗,而且他本身就是一个极为擅长寻找战机的大师。
但是他选择了不等布局结束,直接开战。
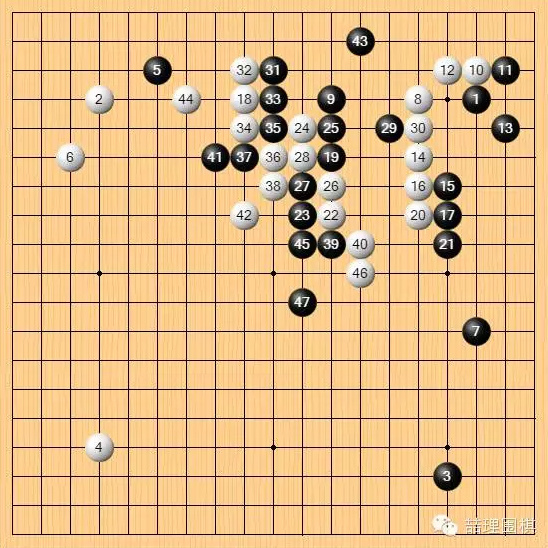
至此,形成了六七块棋互相纠缠的局面,头绪非常之多。这是典型的开放式复杂局面。
仔细观察可以看到,AI 是有机会避开这种局面的。
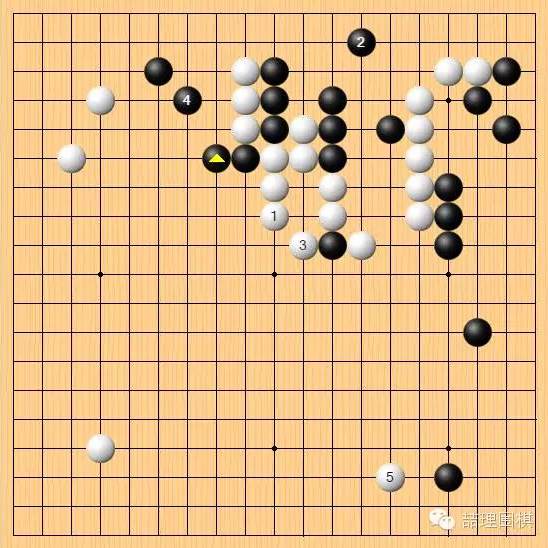
白 42 手可以选择在 1 位这里贴吃,选择吃掉中间两子,弃掉上边三子形成转换,如此便会避免复杂的战斗局面,形势也并不落后。
但实战白棋选择把上边三子跳出,形成混战局面。这是更强的下法。
那么,在进入开放性复杂局面之后,AlphaGo 的表现如何呢?
答案是,非常好。
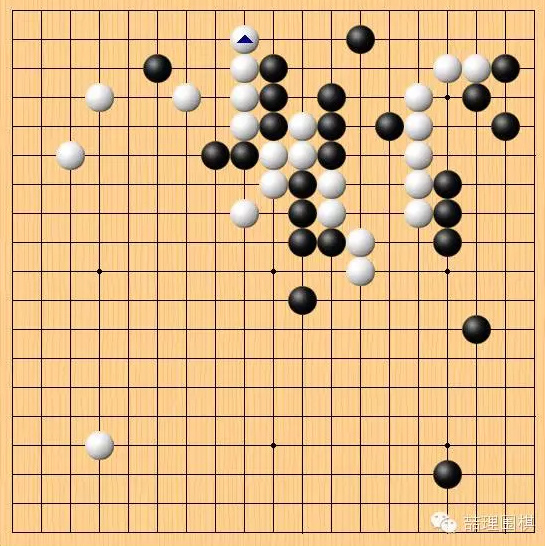
下午我在新浪和俞斌老师一起做现场直播时,同步进行至此,俞老表示担心白棋上边二路立一个先行搜刮,趁黑立足未稳先赚取利益。话音未落我们就看到 AlphaGo 下出了这一步。
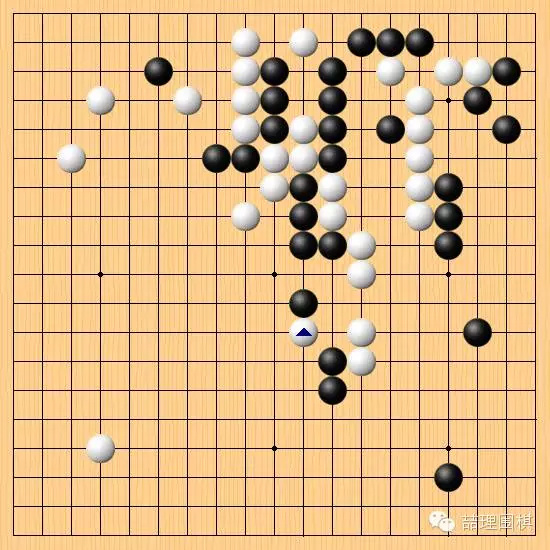
这步靠,本身似乎是“不成立”的,因为黑棋可以轻易地征吃白棋。这一步是业余棋手绝难想到的下法,因为白棋右上自身正处于防守状态,顺着往下贴是本能下法。然而 AI 下出这一步,在防守时反手一击,包含了弃子整形、试问应手等诸多人类理解的含义。
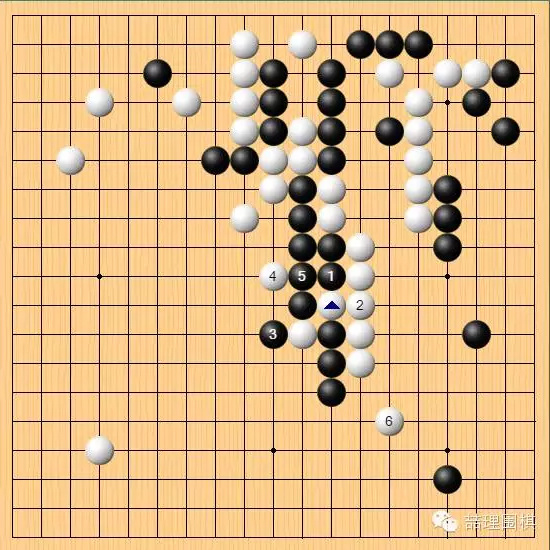
诚然,黑棋可以很轻易地吃掉白棋靠出来的这个棋子,但代价是黑 1 的俗手打吃和白 4 的先手便宜。职业棋手能够很容易地看出白棋送一个子整形是有所便宜的,但 AI 也能轻松地做出这一判断,并且在防守时有此“意识”,真的很神奇。
当然,对于跨断送吃这步棋究竟是否“好”,棋界并不能给出十分确定的统一答案。但是 AI 下出这步棋,仍然是对其能力的展现,起码认为 AI 不会主动弃子、不会防守反击的论断可以休矣。
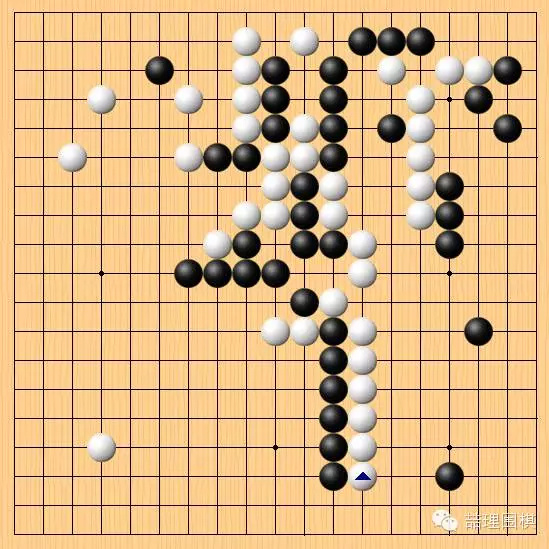
棋局至此,其间的进程在这里不做技术细节上的评论。简而言之,面对开放式复杂局面,白棋处理得井然有序,该弃的弃,该取的取。李世石的第一策略宣告失败。
这证明了,基于深度学习和蒙特卡洛的围棋 AI 面对“开放性复杂局面”时的能力并未如设想般下降,反而应对得法,在李世石挑起不利战斗的情况下取得了局面的领先。
李世石或许意识到了这一策略并未奏效,于是迅速调整,进入了第二策略。
3)策略二:胶着的细棋局面
事实证明 AlphaGo 并不惧怕复杂的战斗格局,于是李世石选择及时收手,试图将局面导向细棋。
细棋局面下,要求双方在每一处细小的地域争夺上都尽量做到极致,一两处的失误虽然不会造成大片伤亡,但常常足以致负。
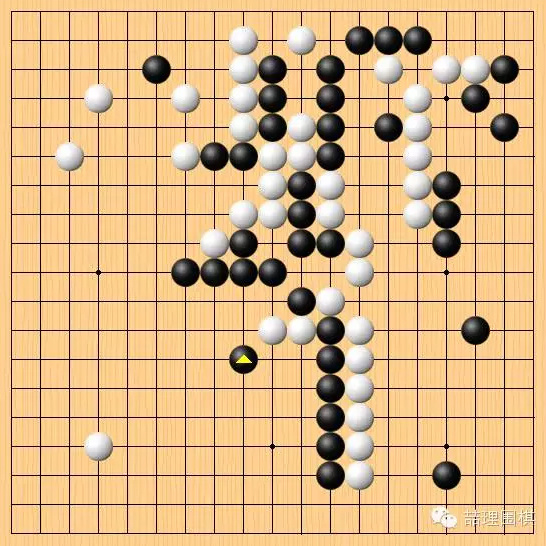
第77手,这是李世石第二策略的开始。这手棋宣告停战,进入胶着的细棋状态,比拼后半盘的功力。如果不选择停战,李世石可以考虑直接在左下挂角,引诱白中腹两子逃出,进而继续战斗。
但李世石认为第一策略的试探已经完毕,没有奏效,因此选择了第二策略。
接下来的棋局,我们转换一下视角,从 AlphaGo 的角度来探究。
二、AlphaGo 的争议着法
关于 AlphaGo 在此局的表现,棋界比较一致的观点是从布局到中盘的激战白棋下得很好,分歧点主要在对 AlphaGo 在后半盘的表现。
1) 缓手?
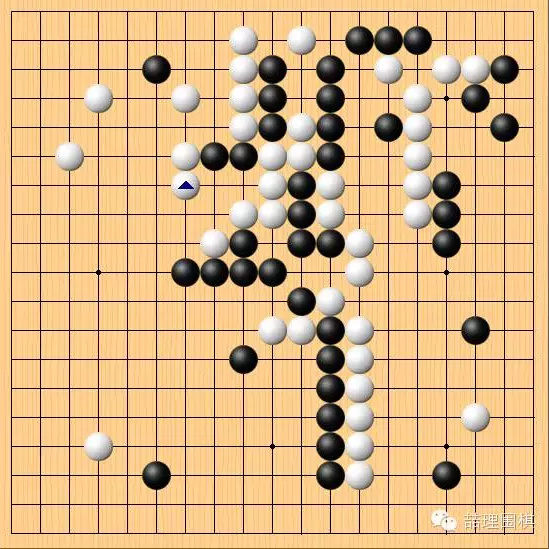
第一个焦点是第 80 手。上一手黑棋刚在下边挂角,白棋正常的下法是在左边跟着守一步。但实战白棋选择脱先,在左上补了一手。
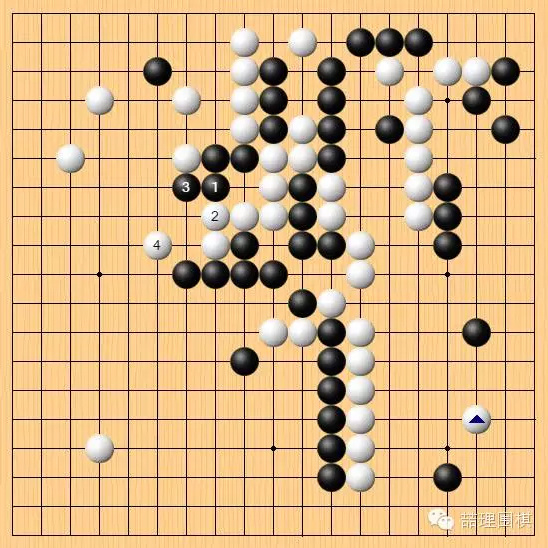
黑棋上一步没有选择在左上马上行动,是认为这样直接作战并没有把握。实战先在下边挂角,稳住实地,再作图谋。
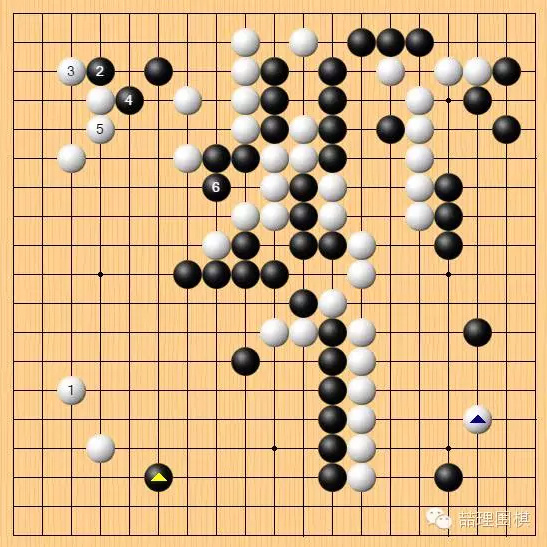
面对左下挂角,局部跟着应一个是最常见的下法。但黑棋在确保了下边的地域之后,左上可能会选择现在 2 位迂回,如果白棋毫不退让,那么 6 位再战出相当严厉。如果白棋退让,黑棋可以得到左上的角地。这里具体的定型变化并不容易得出结论,存在不少分支。
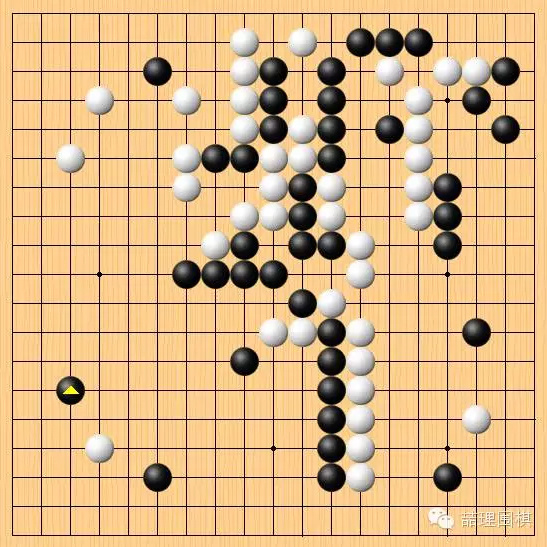
实战白棋选择了脱先补左上,左下黑棋得到“双飞燕”作为补偿。至此,对棋局的判断出现分歧。做直播的棋手中,有一些认为此时已经是黑棋优势,白棋上一步补棋是大缓手。也有人认为白上一步虽然缓,但形势还是白棋不错。
上一步究竟是不是缓手?我们这里先不做结论,往下看。
2) 恶手?
下一个焦点在第 86 手。
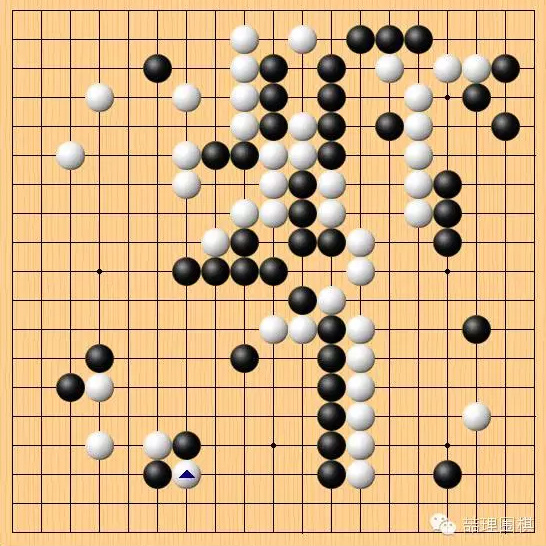
白86断,又是棋谱里没有的下法。不过对局至此,我们对此已经并不惊讶。这步断的意图对人而言很好理解,由于黑棋右边很厚,白棋想通过弃子整形,使黑棋的厚势变得重复、效率低下。从人的角度来看,这是白棋最明显的意图。
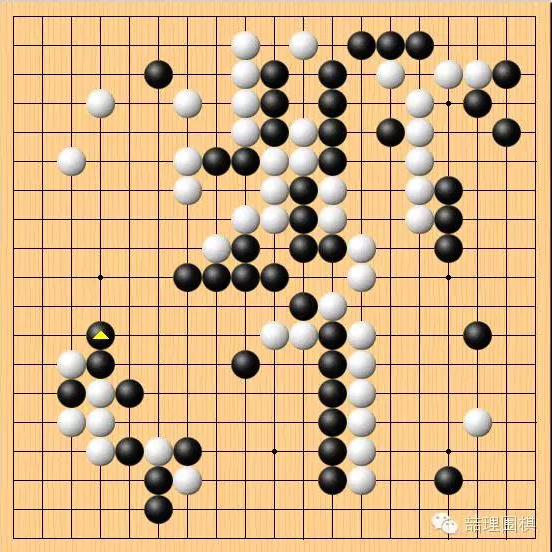
实战结果,棋手普遍认为左下白棋亏损,并且是严重亏损。这是因为,黑棋围住了一大块空,白棋实地受损。
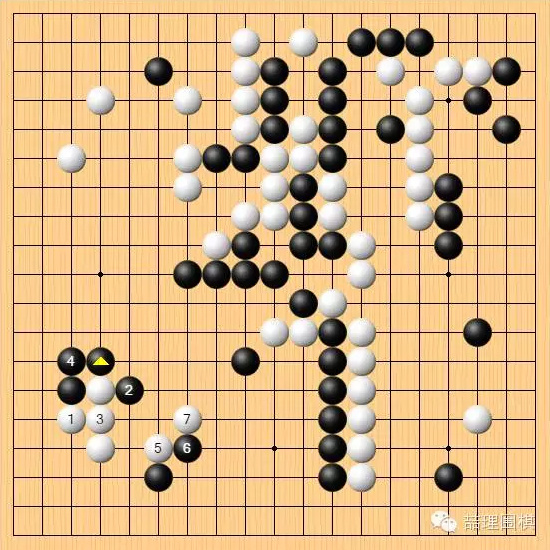
普遍推荐的变化是这样,白棋在确保自身安全的同时尽可能缩小黑棋的地域。有人认为,这样的进行白棋比实战“便宜一个贴目”,也就是六七目。如果是这样,实战白棋的选择亏损严重。
但是,这个图存在一定的风险,关于这个风险我们留到后面来说。
三、载入史册的一手!
左下定型结束,人类棋手普遍产生乐观情绪:李世石优势,AI 也不过如此嘛。
然而,接下来的 AlphaGo 的一步棋成为了此局最为闪耀的明星。
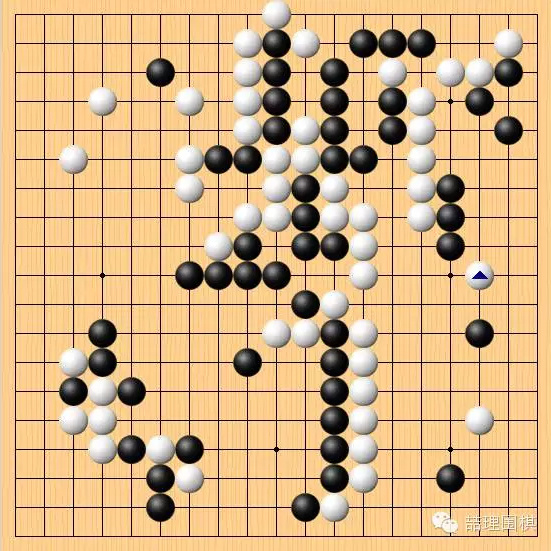
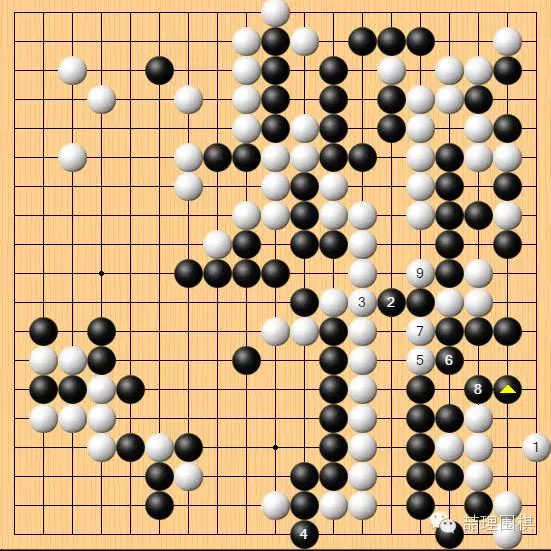
白 102,右边三路点!
这一手必将载入围棋的史册,与古今诸多妙手共同谱写灿烂的篇章!
在未来的 AI 棋谱中,必将留下非常多震撼人心的妙手:它们或许比这一手更加精妙,或许比这一手更加深奥,但它们都无法取代这一手在围棋历史中的位置!
此手完全出乎了李世石的预料,他面对这一手,进行了全局唯一一次长考,仍然遭受重创。
在直播时,也有职业高手在白棋下出这一步之前已经预测到这一手。但是,对于人而言这里有一件非常有趣又苦恼的事情:对局者对于对方这种着法的预计往往不如观战者。
这是因为,观战者可以很轻松地站在双方的立场来思考棋局,为双方寻找最强的着法;而对局者更多时候是在思考自己的着法,相较而言会容易忽略对方隐蔽的强手。李世石如果预料到这一手,或许会在之前找机会刺一下作为防备。但作为对局者很难有如此周密的行为,尤其在面对AI的时候,更难想到电脑会有如此强的手段。
更有趣的是,这一手包含了相当大的计算量,有不少需要计算的分支,如果是人来下,即使能想到这一步,离真正算清楚并下出来还有不小的距离。也就是说,即使人类看到这一步,也要通过大量时间的计算来验证这一步是否成立。然而,电脑下出这一步,并不比其他的着法用时更长,相反比后面一些人类看来简单甚至必然的着法用时更短。
我们不禁要问:AI 真的都算清楚了吗?
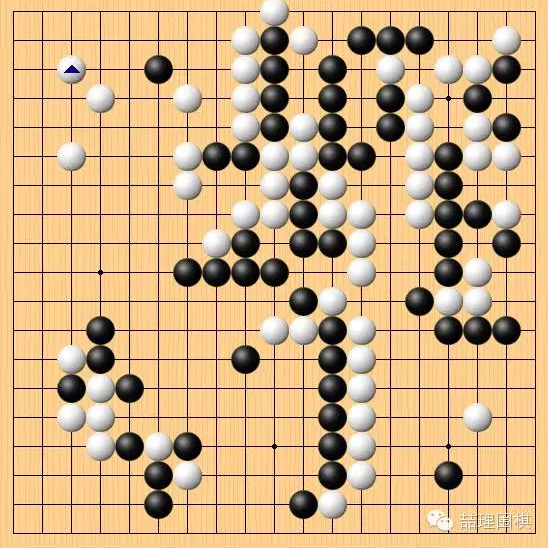
实战的结果是这样,白棋右边先手割下黑棋三子,回到左上守角。顺便提一句,这里守角的手法值得注意,大量棋谱以及多数棋手的第一感都会走在旁边一路,但只要仔细看一下就会发现,此局面下实战 AlphaGo 的选点更好。
棋局至此,我认为已经是白棋稍优的局面,但也有人认为仍是细棋。
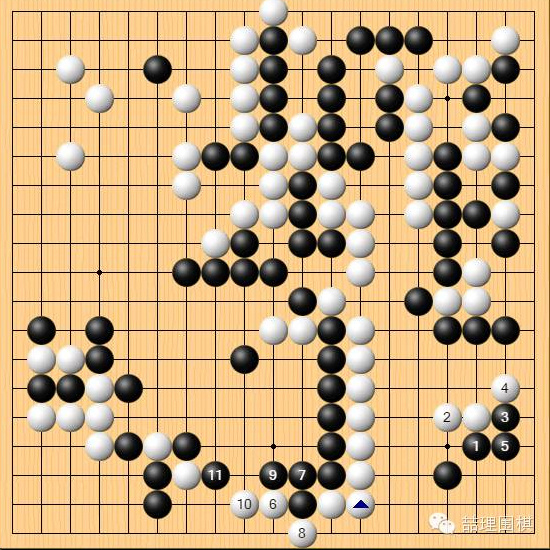
实战黑棋 123 手以下明显亏损,如图尖顶活角优于实战。但此图究竟谁胜,还需要深入的仔细研究。我个人的意见是,白棋稍优,并且我猜测 AlphaGo 也认为能赢。
黑 123 以下在目数上亏损了接近一个贴目,使得棋局直接失去了悬念。最终双方盘面接近,李世石无法贴目,投子认负。
我们惊异于 AlphaGo 的表现,惊叹于李世石的败北。对于接下来的比赛,很关键的一个问题是,AlphaGo 究竟有没有失误?
四、AlphaGo 的“失误”
这盘棋 AlphaGo 有没有失误?
令人欣慰,从人的眼光来看,我们可以找到 AlphaGo 的明显失误。这种失误不是指那种基于人类经验而认为的失误(经验有可能会骗人),而是可以通过逻辑分析来确认的失误。
1)“失误”一:
白 136 手吃。对于职业棋手而言很容易判断,应该吃在一路,比实战便宜大约 1 目。
2)“失误”二:
白 142 手挡,对于职业棋手而言,这也是一个很容易确认的明显亏损。
白棋正确的下法是1位跳,这样将来留下了 5、7、9 吃两子救回三子的下法,从目数上分析明显优于实战(大约 1-2 目)。即使白棋不在 5 位扳,走 8 位先手粘掉也优于实战一点点。
这两处“失误”都是在局部,没有任何与外界的关联性,属于封闭式的失误,其亏损可以用逻辑推理的方式证明。相较于AI展示出来的水平,似乎这两个失误是“不应该”的。
基于此,又有棋手表示:“这都看不到,AI 不过如此啊”。
前面“恶手”里讲到的左下角白棋的问题,也有人看做是第三个失误。但那个失误的性质与这两个不同,我们对那个失误的认定在很大程度上还是基于经验的,虽然也包含了逻辑推理,但并不完全。在我看来,按照笛卡尔的理论,对这那失误的认定是可怀疑的。
但这两个失误却不可怀疑。既然如此,我为什么要在标题里给“失误”打引号呢?
这引出了一个非常有趣的话题:在棋盘上,失误的定义是什么?
3)不同的“失误”定义
对于我们棋手而言,什么是棋盘上的失误?假如我们把基于经验认定的失误都排除在外,只留下基于逻辑推理认定的失误,那么失误意味着:A在逻辑上优于 B,而我选择了 B。
在这个意义上,只要我们找到了“可确认的更优下法”,就认为我们出现了失误。
但是,对于 AI 而言,失误是否意味着相同的事情?我们怎么理解AI出现了在我们看来低于其水准的失误?
这就涉及到 AI 的算法问题。假如AI有一天穷尽了围棋,那么只要它有一步不踏在最优解集合里,就是失误。但是,现在的 AI 还远无法穷尽围棋。
AlphaGo 的算法运用了神经网络加蒙特卡洛,蒙特卡洛算法的一个特点是:不求最优。
蒙特卡洛算法给出搜索之后的胜率评估,然后 AI 会根据这个胜率来选择落子点。也就是说,AlphaGo 本来就不追求最强最优的下法,它只是追求在它看来胜率最高的下法。
那么,回到前面那两个“失误”,之所以打上引号,是因为在 AlphaGo 看来,或许这根本不是失误!
虽然在我们人类看来,逻辑上明显 A 优于 B,但 AI 在那时认为两者的胜率相似,从获胜的角度来说,两者没有区别!甚至 A 之后的犯错概率高于 B,从而导致它认为 B 的胜率高于 A!
如果两条路同样能通往胜利,在AI的意义上,你还能说它是失误吗?
或许能!
但是前提条件是人类利用这种“失误”击败了它!否则,在AI的意义上我们无法指责那是它的失误。
再回过头看前面,白棋左上的补棋和左下损目抢得先手,真的是可以确认的坏棋吗?
左上的补棋,证明 AI 认为补棋的胜率优于走左下,这一判断很可能是建立在 AI 对右边那手点的认识之上。甚至大家公认的左下白棋亏损,也可能是基于对右边那手点的认识,希望在左下抢一个先手,并且在胜率上认为这是没有问题的。
而李世石对形势的判断显然是基于没注意右边那手点。
五、AlphaGo的“弱点”
这么说,难道 AlphaGo 真的就不可战胜了?不一定。从这盘棋中,我们可以看出 AlphaGo 的弱点。问题在于,这几个弱点是否足以影响人机对决的胜负?
1) 逻辑缺失
虽然上一章我认为对AI失误的认定需要谨慎,但在另一个层面上,这还是说明了 AlphaGO 的弱点。
深度学习加蒙特卡洛,AlphaGo 在剪枝和搜索这两方面的能力在这盘棋中已经得到证明,人类下棋同样依靠剪枝和搜索,并不能在这两点占得上风。
但是,AlphaGo 的算法缺乏逻辑能力。这一点实际上在 10 月对阵樊麾时已经有所体现,在这一局的两处“失误”则体现更为明显。
蒙特卡洛算法使它并不是根据“逻辑上 A 优于 B ”来做选择,而是根据AB各自的胜率来做决策。
在准确性上,概率不如逻辑。
AI基于逻辑缺失而导致的“失误”,是否可能成为人类棋手的突破口?
2) 逃避劫争?
AI 面对复杂劫争时的糟糕表现,是蒙特卡洛时期固有的顽疾。去年在北京夺冠的围棋 AI,在对阵连笑时甚至不能理解循环劫,不停地找劫来回提,使局面一塌糊涂。这是因为,基于概率,循环劫也总有打赢的可能。这也是第一个弱点的延伸,如果基于逻辑,会明白这是不可能的事情。
使用的深度学习的AI能否避免这个问题?目前我还没有看到。不过,似乎 AI 有刻意逃避劫争的倾向。
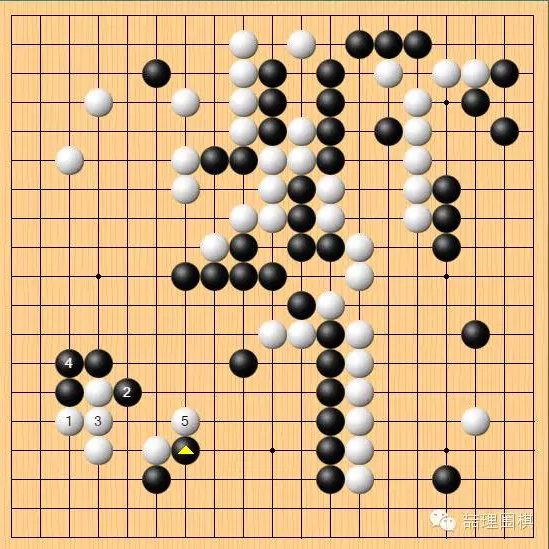
回到有争议的左下角,棋手普遍认为白棋如图是最强的下法,
但是 AlphaGo 可能担心劫争:
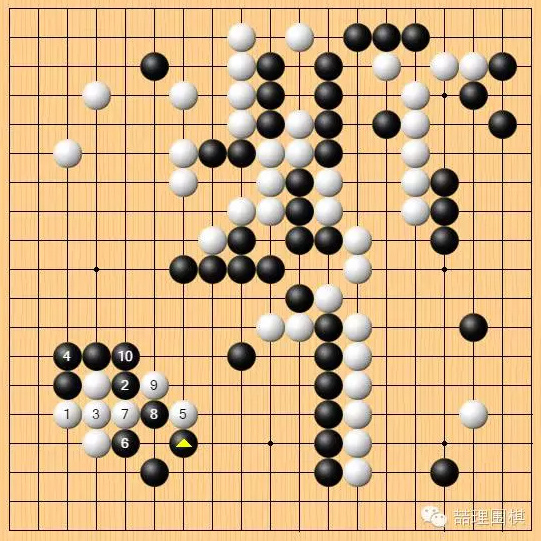
黑6开劫是最强的下法,在右边点一手找劫,接下来可能形成转换,白棋是否肯定便宜?粗粗一看,不能确定。
另一处有趣的是最后的官子:
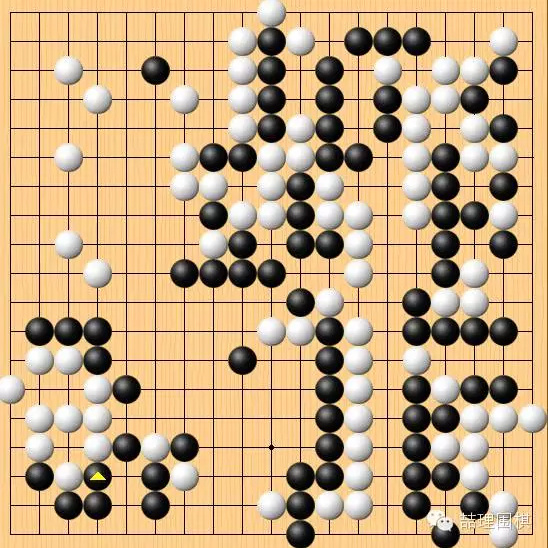
此时白棋胜势已定,在做最后的定型。黑棋左下先手搜刮,白棋需要做活。
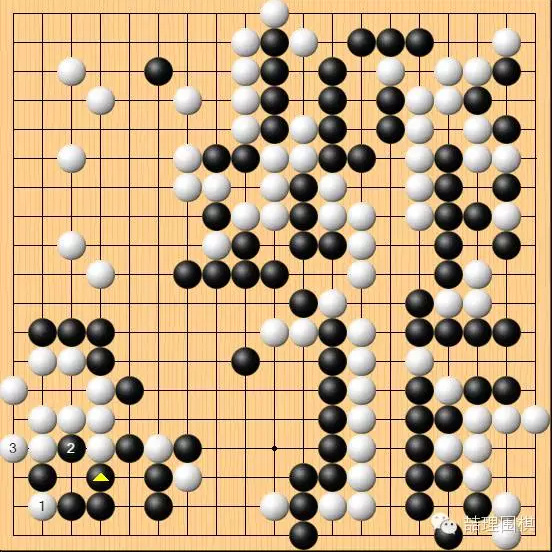
实战白棋选择的是 1、3 做活,并非最强手。
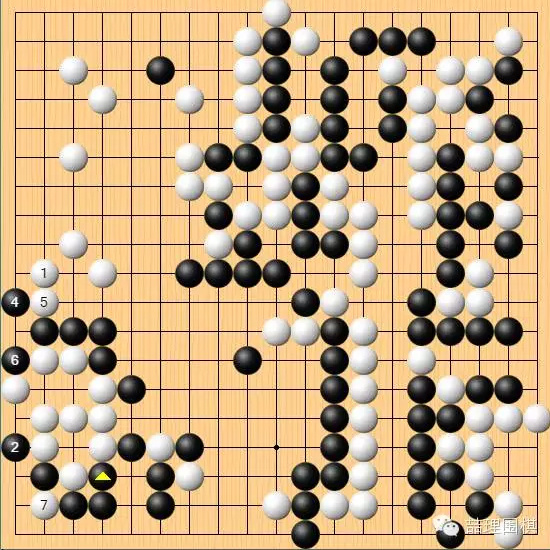
最强手是白 1,成连环劫活,目数优于实战。
但是,无论是出于不考虑最强手,还是出于对劫争的逃避,实战白棋没有这样选择。
这么看来,起码 AlphaGo 还没有显示出它有应对复杂劫争的能力。
那么,劫争是否会是 AlphaGo 的一个命门呢?
在我目前看来,AlphaGo 最可能的弱点只有这两个。
六、人类可能的策略
基于对AlphaGo弱点的分析,我认为李世石接下来可选择的策略并不是很多。
1,我最期待的策略是,李世石按照人类研究很深的套路开局,因为AI并不会背套路。即使不能凭此占优势,也要尽可能保持局面的均势。在这个条件下,AI 或许会在一些简单的局部因逻辑缺失而有所亏损,人类牢牢把握住这些微小的利益,最终取得小胜。不过,这似乎并不是李世石常用的风格。
2,另一个策略是在局面选择中尽可能制造劫争,即制造对方不开劫就不利的局面。当然,AlphaGo 目前没展现出复杂劫争的能力并不能证明它没有这种能力,因此这种策略是存在风险的,太过刻意是不行的,还要考虑局面的自然和均衡。
七、结语
如果我们只用人类思考围棋的方式来理解 AlphaGo,或许我们将永远都不知道是怎么输的。
人类历史上的最后一次“深蓝”大战?!3 月 9 日- 15 日,Google 出品的人工智能 AlphaGo 将迎战目前世界最顶尖围棋选手之一的李世石(韩国)。究竟人类能否在 5 场比赛中守住最后的尊严?爱范儿为你邀请了多位围棋界顶尖棋手、人工智能领域专家进行全程跟踪和报道,敬请持续关注!
题图来自 Wikipedia





