






AR 有了新“看法”,会不会更加智能?
本文由 ARinChina(www.arinchina.com)原创,转载请联系 ARinChina(微信 ID:arinchinaservice)
如果 AR 可以像人一样“看懂”现实世界,并根据情况将自己的“想法”进行“表达”。那么,世界将是怎样?
我们先来欣赏一段视频。
(腾讯视频)
视频中人类生活因 AR 的帮助更加便利。那么,要想达到这种效果,AR 应用必须智能化。要使 AR 智能化,必须先使 AR 的“视觉”智能化。
计算机与小孩的“看图说话”大 PK

这是《爱丽丝漫游奇境记》中疯狂茶话会一幕,当一个小孩描述这幅图时,他能立刻识别出图中的一些简单元素,比如:
“房前的一棵大树下,放着一张桌子。一只兔子和戴帽子的人坐在桌旁喝茶。桌子很大,他们三个都挤在桌子的一角……”
然而计算机在描述这幅图时,它不懂什么是“三月兔”,谁是“爱丽丝”,它只会以立体几何的形式描绘这些内容。

计算机这种简单的描绘方式,使得 AR 应用目前必须提前设定识别目标才能进行交互。
人是怎样“看”世界的?
经过 5.4 亿年,人类才形成对世界的认识,其中大部分努力用在了大脑视觉处理机制的开发,而不是眼睛本身。也就是说视觉始于眼睛,却发生于大脑。
1981 年的诺贝尔生理学及医学奖获得者——休伯、斯佩里和韦赛尔——研究发现,视皮层细胞解释视网膜的编码脉冲信息的能力,是在孩子出世后直接发育形成的,这种发育的一个先决条件是:眼睛必须受到视觉刺激。在这一期间,如果一只眼睛闭上几天,视皮层将发生永久性的功能变化。
这意味着:大脑的高度可塑性是从一出生就开始的,大脑在这段时期接受丰富多彩的视觉刺激十分重要。
如果把人的眼睛看作一对生物相机,它们大约每 200 毫秒就能拍一张照片(这是眼睛运动的平均时间),那么 3 岁小孩看到的图像是数以亿计的。人类大脑通过观看无数张图像后才对物体有了概念。
为什么计算机做不到?
斯坦福大学的计算机视觉专家李飞飞曾在 TED 大会上举了一个很好的例子:
我们可以用简单的几何形状来描绘一只猫。

但是对于一些形状诡异的猫呢?像这些。


像家庭宠物这样简单的物种,在模型上都千差万别,大千世界更是千姿百态。李飞飞和她的团队在生物识别方面投入了大量心血,也没能找到一个好的算法让计算机准确识别出一个物种。
于是他们不再专心寻找优秀的识别算法,而是把注意力放在了人类视觉的形成上。
模仿人类看世界
我们从出生就开始不断通过眼睛采集图像,大脑通过大量图像的训练后,才形成了我们现在的视觉系统。那么,如果我们把计算机当做一个婴儿来培养,它会不会像人一样聪明了呢?
李飞飞和她的团队就是这样做的。他们建立了一个含有 1500 万张照片的数据库——ImageNet,通过记住大量图片来教计算机认识物体。

不过,计算机可以通过摄像头来模拟人眼采集图像,却无法从拍摄到的图像中识别出有用的信息。
庆幸的是,Kunihiko Fukushima、Geoff Hinton 和 Yann LeCun 在上世纪七八十年代开创了“卷积神经网络”,这是一个非常复杂的模型。该模型中最基础的运算单元是“神经元式”的节点,就像大脑由上十亿个紧密联结的神经元组成。每个节点从其它节点处获取输入信息,然后再把自己的输出信息交给另外的节点。
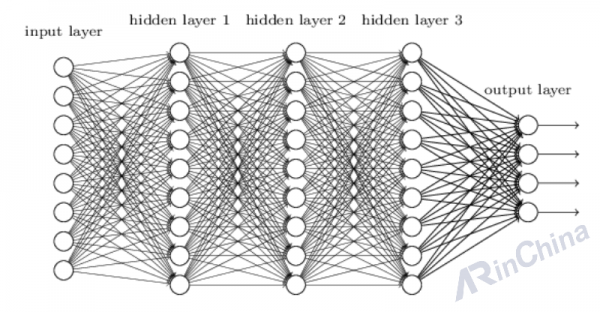
此外,这些成千上万甚至上百万的节点,都按等级分布于不同层次。在一个用来训练“对象识别模型”的典型神经网络里,有着 2400 万个节点、1 亿 4 千万个参数和 150 亿个联结。
李飞飞团队借助 ImageNet 提供的巨大规模数据支持,通过大量先进的 CPU 和 GPU,训练了这些堆积如山的模型。在图像训练中,由一个提前选定的卷积核来对图像进行“扫描”,然后经过层层神经元的分析,最后输出识别结果。
“卷积神经网络”也因此蓬勃发展起来。它成为了一个成功体系,在图像识别领域产生了激动人心的新成果。
目前,通过模拟人类视觉,计算机识别效果已经可以与一个 3 岁小孩相比。


不妨试想一下,等计算机可以像少年一样描绘世界,那么它看到“疯狂茶话会”画面时,就有可能是下面这种描述:
“房前的一棵大树下,放着一张桌子。三月兔和帽匠坐在桌旁喝着茶,一只睡鼠在他们中间酣睡着,那两个家伙把它当做垫子,把胳膊支在睡鼠身上,而且就在它的头上谈话。‘这睡鼠可够不舒服的了。’ 爱丽丝想 ‘不过它睡着了,可能就不在乎了。’……”
就像讲故事一样,这段描述立刻生动起来。其中对睡鼠的感受,还添加了自己的想象。这会不会是未来 AR 的模样呢?
为了达到这一效果,我们正在教计算机如何去“看”,未来世界将有更多的“眼睛”一起探索。
题图来源:youtube





