






大热的 IaaS 与前途未卜的甲骨文
作者:Ben Thompson 译者:ONES Piece 塔娜、任宁
译者按:IaaS(Infrastructure as a Service),即 “基础设施即服务”, 已经成为一个令人瞩目的方向,甚至出现了云计算就是 “互联网税” 这样的说法。无论是国内还是国外,这似乎都是一个大佬之间火拼的战场。谁将赢得未来?作为用户,我们是该选择 “单点” 还是“套餐”?
每个人都知道 IBM 把大好河山让给微软(和英特尔)的故事:那时,低耗电个人电脑的消费者需求已经把 IBM 围得水泄不通,为了对这些没什么赚头的需求有所响应,这家垂直聚焦于大型主机领域的公司在佛罗里达州 Boca Raton 市设立了一个研发队伍,离他们在纽约 Armonk 的总部所在地很远。

图片来源:ExtremeTech
由于把着重点放在速度与成本上,这支队伍决定基本把所有东西都外包出去,包括操作系统和处理器。
对于 IBM 的目标,这个方法是行之有效的:当大型主机通常需要十年来研究并发布时,Boca Raton 团队在 12 个月之内就完成了从概念到发货的流程。
但是着重于外包标准件的做法则意味着个人电脑领域最肥的肉(比大型主机生意赚钱多了)落入了两个独家供应商手中:微软和英特尔。
很少有人知道,个人电脑不只是 IBM 的 “内部政策驱动” 之下放走的唯一一块肥肉。大型主机上最重要的软件应用曾经是 IBM 的信息管理系统(Information Management System,IMS),一个层次型数据库。
让我在这里暂停一下:对于不懂数据库的读者,我会试着尽量将接下来的阐述简化。对于那些懂的人,很抱歉让这篇文章变得有点浅。
数据库的类型
一个层次型数据库,好吧,就是一层层的数据:
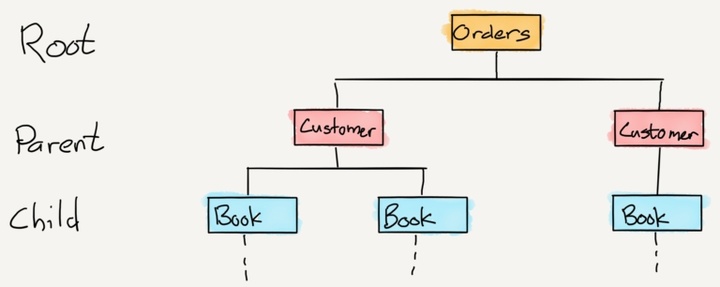
译者注:图中三层,自上而下分别是根数据项、父数据项和子数据项。
在层次型数据库中,任何一项数据都可以通过两种方式被找到:要么已知父数据项去找子数据项,要么已知子数据项去找父数据项。
这是理解起来最容易的一种数据库,而且至少对于早期的计算机来说,实现起来最简单的:定义结构,录入数据,然后通过遍历层级来搜索子数据项或者父数据项来达到搜索数据的目的。
或者,更实际地来说,运用你对层级的了解,直接去到某个特定的点。
但是,层级型数据库有两个重大的限制:
- 首先,这里面的数据关系是被事先定义的,哪些是父项、哪些是子项是在任何数据被实际输入前就决定好了的。这使得数据库一旦被使用,再要做改动就非常困难。
- 第二,要做不同父项的子项查询是不切实际的:在忽视数据库的大部分,取得你想要分析的数据组之前,你需要遍历层级来获取所有潜在项的相关信息。
在 1969 年,一位名为 Edgar F. Codd 的 IBM 计算机科学家写了一篇名为《大型共享数据库的关系数据模型(A Relational Model of Data for Large Shared Data Banks)》的论文,提出了一种新方法。哪怕外行人来读,这篇论文的引言也非常浅显易懂:
未来,大型数据库的用户必然不用再为研究数据在计算机内部是如何被组织(即 “内部表象”)而烦恼。但及时供应这等信息的服务并非是一个令人满意的解决方案。
当数据的内部表象甚至外部表象的某些方面发生变化时,终端用户的活动以及大多数应用程序应该要都不受影响。计算机存储的各种类型数据在查询、更新、报告流量和自然增长上的变化都会导致数据表象的变化。
这篇论文是后来为人所知的 “关系数据库” 的基石:与其以层级方式(即前文所述由数据定义自身在数据库中的位置)储存数据,关系数据库使用表格来做这件事。
每项数据是由它的表名、列名和键值来定义的,而不是由数据自身(数据被存储在别处)。这意味着你可以通过一项数据与其他所有数据库中数据的联系来理解它。表名也可以作列名,就像键值也可以作表名。
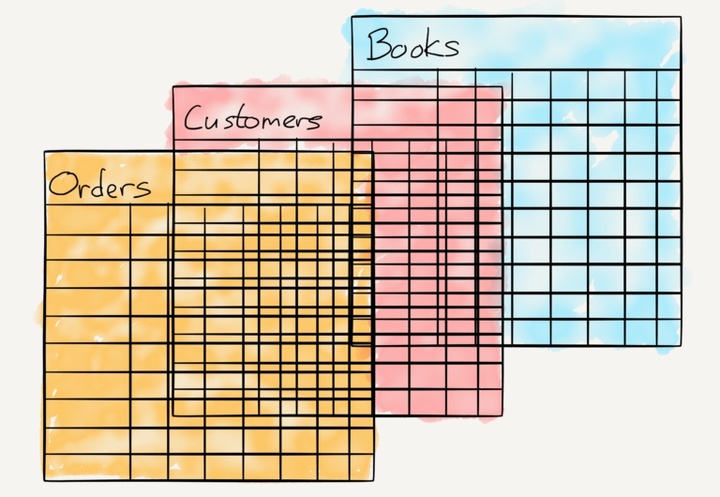
这个方法有几个巨大的好处:
- 第一,你可以新增数据库里的数据种类而不会影响到之前录入的数据,也不用重新把层级都写一遍,只要加新的表就行。
- 第二,数据库可以为任意数量和类型的数据进行扩容,因为数据并没有真的在数据库里——为了支持整数和文本字符串,你看到的是数据的逻辑抽象。
- 第三,使用 “结构化查询语言(SQL)”,你可以轻松地调出数据关系之间的报告(比如 “40 岁以上的消费者买的最多的 10 本书”),而且由于查询只是在检测整数和字符串直接的关系,你几乎可以无所不问。毕竟现在只要搞清楚数据库里两个数据位置之间的数学关系而不用扫描整个树状结构了——要是你不知道你要找什么,原来的办法天生就慢,而且大多数情况下比较盲目。
长出一口气……上面这几段话你们读起来应该跟我写起来一样痛苦。
但我们还是有收获的,总结一下:由于受到预先定义的拘束,层级型数据库在性能和容量上都受限。而通过抽象数据产生计算机可以很容易处理的键值关系数据库要有用得多,并且扩容空间大得多。
甲骨文的崛起
Codd 博士石破天惊的想法几乎被 IBM 完全忽视了好几年,一部分是由于之前提到的 IMS。
Codd 基本上就是在说,对于很多潜在的数据库应用程序而言,IBM 最大的赚钱机器已经过时了——这是一条 IBM 管理层不太愿意听到的消息。
事实上,哪怕在 1977 年 IBM 最终打造出世界上第一个关系数据库(那时候它被叫做 System R,包括一种叫做 SQL 的新查询语言),他们并没有做商业发行。要到 1982 年,IBM 的第一个关系数据库软件 SQL/DS 才上市。
自然,它只在 IBM 的主机上运行——IMS 是大家伙的专属。

图片来源:Business Insider
与此同时,一位叫拉里 · 艾利森的年轻程序员组建了一家名为 “软件开发实验室(Software Development Laboratories)” 的公司,起初做些外包的活儿,但是后来迅速发现卖通用软件要赚钱得多:写一次程序,然后卖它个很多次,是个发财致富的绝佳路子。
他们只需要一个产品,而 IBM 基本上就是白送了他们一个。由于 System R 团队被当作一个研究项目而非商业计划对待,团队很开心地写了不少论文来解释 System R 的工作原理,也公开了 SQL 的技术参数。
软件开发实验室实现了这个软件,管它叫“甲骨文”,在 1979 年把它卖给了 CIA(对方的条件是软件要能在 IBM 主机上运行)。
换句话说,IBM 不但为通用软件界有史以来最大的公司(微软)萌发创造了条件,还白白把致富说明书送给了第二大公司(甲骨文)。
通用软件的生意
通用软件产业是一个介于过去的传统行业与互联网时代纯数字行业的混合体(毕竟那会儿还没有互联网)。
一方面,艾利森很快意识到,软件的边际成本为零:只要你写了一个特定的程序,就可以制作出无数的副本;另一方面,渠道分发成了最大的挑战。
在甲骨文的关系数据库这个例子里,Relational Software Inc.(就是之前的 Software Development Laboratories,这家公司在 1982 年改名为甲骨文系统公司,1995 年才改为今日的甲骨文集团)不得不建立起一支销售队伍去卖产品,然后再用磁带把软件寄出去。
最经济实惠的做法,是做一个大多数客户都想要的产品半成品,然后和不同的客户一起把产品最终完善起来。

图片来源:MarketWatch
这里面一部分的工作在前端——甲骨文可以快速用 C 语言重写新程序,而 C 语言在大部分平台都有编译器,支持甲骨文移植代码——但更多的工作是在售后:客户需要安装甲骨文,让它工作起来,录入他们的数据,只有这样,在原始协议的几个月甚至几年以后,他们才开始看到回报。
最终这成了甲骨文的商业模式:甲骨文的客户不仅仅是购买软件,他们和公司绑定了多年期的完整服务,包括软件许可、售后支持、以及审核计划,来确保甲骨文履行了他们的义务。
而且哪怕有些怨言,客户也不太会去另找别家:那些关系数据库和存放在上面的数据都是公司的重要资产,他们早已把这些数据投入使用并开始构建和运行,谁还愿意把那套流程跟其他公司重来一遍?
的确,当已经运行了甲骨文的数据并有了这层关系后,向甲骨文购买在那些数据库上运行的应用程序会是更方便的选择。
因此,接下来超过三十年间,客户 IT 开销不断增长,而甲骨文把这个先发优势利用到了极致。这也算 “肥水不流外人田” 吧!
亚马逊带来的选择
亚马逊网络服务系统(以下简称 AWS)背后的主张却不尽相同。公司不需要预付款,也不需要绑定多年的整合项目服务,而是登录帐号,使用完毕退出即可。
公平地讲,对于亚马逊那些有议价能力、签订长期合同的大客户来说,这显得过于简单化了。但这只是最近发生的事。AWS 的核心用户从开始一直都是初创企业。
他们利用这些耗费几百万美金的服务器基础设施来建立最小可行性产品。
而且 AWS 的花费是可变的:你用 AWS 越多(因为你的用户数在增加),费用越高;要是几乎不怎么用(因为你还没有找到合适的市场),你就只需要花费比什么都不做多一点的机会成本。
![]()
图片来源:GeekWire
可选的价值观使得 AWS 如此有价值:想要更大容量吗?只需一键。需要一个新功能?AWS 包含有一套预构建服务供你整合进产品。
是的,它可能很贵——一个普遍的说法是 AWS 赢在了价格上,而实际上 AWS 却是众多昂贵选择之一——但是,在你最需要的时候能提供你最需要的产品,这样的服务到底值多少钱呢?
与此同时,艾利森在本周的 “开放的世界” 大会上登台演讲,宣布在 IaaS 领域“亚马逊的领先地位将会被终结”,只因为甲骨文最高端的服务器比亚马逊更快更便宜。虽然如此,但层次数据库也比关系链数据库更快;速度不代表一切,价格也不。
可选择性和可扩展性一直都很重要,在这方面,甲骨文的基础服务远远不如亚马逊有竞争力。
当你关注一下云服务领域的关键数据,资本性支出,你甚至会发现艾利森的表述更加荒谬。在过去的 12 个月里,甲骨文的资本性支出全部加起来是 10.4 亿;亚马逊在上个季度花费了 33.6 亿,过去 12 个月是 109 亿。
IaaS 并非接单定制的服务;事实是,那些基础设施以及所有构建在基础设施之上的附加服务早已让 AWS 变得十分诱人。甲骨文不仅没有追赶上,甚至还被落得很远。
聚焦 SaaS
在他的主题演讲中,艾利森反驳了甲骨文的云服务基础设施的花费是不必要的这种观点。他指出,事实上公司花了十年时间将它最具价值的应用移到云端。
确实,公司上个季度花费了总收入的 17% 用于研发,艾利森吹嘘甲骨文现在已经拥有 30 多个 SaaS 应用,而且这个数字很重要:
甲骨文的战略是什么?我们认为客户想要什么?我们在 SaaS 领域该做什么?
其实这是同一件事:如果我们能找出客户想要的并交付出去,那客户就会使用并购买我们的产品。我们认为他们需要的是完成并整合在一起的产品,并非一次性产品。
客户并不想从 50 个不同的供应商那里整合 50 个不同的产品。那太困难了。不仅困难,还存在相关的安全风险、劳动力成本和可靠性问题等等。
所以我们最大的焦点不是卖出去 1 个、2 个、3 个、4 个应用,而是为 ERP,为人力资本管理,为客户关系管理(有时也叫用户体验,简称 CX)交付完整的软件套装。这是我们对 SaaS 的策略:完整的整合套件。
图片来源:RoisinByrne
艾利森争论的问题在部署型软件方面是正确的;我曾在 2015 年就这个动态写了一篇关于微软的文章。想像一下云计算时代之前公司里的首席信息官(CIO):
因为各种原因她不得不购买微软的各种解决方案(像 Exchange)。因此,为了支持 Exchange 的服务,CIO 还需要购买 Windows Server(微软的一款服务器系统),Windows Server 又包括了活动目录(Active Directory),于是还需要身份认证服务。
但是,现在 CIO 已经有了一部分微软的解决方案,她会更倾向于购买其他微软的服务,不论是关系型数据库管理系统(SQL Server)、客户关系管理系统(Dynamics CRM)还是门户网站和企业内网(SharePoint)等。
确实,微软的产品可能不总是最好的,但 CIO 都要考虑到现实情况:后续维护和服务费是一个巨大的隐忧,而且较少的供应商往往能带来更多好处。
事实上,微软近 15 年来的壮大可以追溯到巴尔莫聪明地利用新产品、新定价和许可协议,迫使用户购买更多的公司产品。
如上文所提到的,这和甲骨文的策略如出一辙。然而,企业的 IT 决策也在发生着重大变化:
- 首先,在不需要巨大的前期投资后,转向另一家供应商的风险变得低多了,尤其是当只有团队或部门层级试用过相关产品的时候。
- 其次,没有了持续的客服和后续的维护成本,也就减少了和供应商关于可变成本的争论。
当然,艾利森警告的——将 50 个不同的供应商合并在一起使用的潜在麻烦——也许会出现,但这也同时意味着软件的实际质量和用户体验在购买决策中扮演着更主要的角色,且团队决策这一点使之变得更为重要,因为服务的购买者就是实际使用者。

图片来源:RCR Wireless News
过渡阶段的甲骨文
简而言之,艾利森在兜售的新甲骨文看起来跟旧甲骨文很像:一大堆的产品,大部分客户想要什么几乎就做什么,至少理论上是这样,但是既没有 AWS 的灵活性和可扩展性,以及聚焦和承诺用户体验的专用 SaaS 服务。
在数据库方面,像一个层次数据库,甲骨文都是根据顾客的要求提前定制开发的,不需要任何灵活性。
与此同时,AWS 和专门的 SaaS 服务提供商都是关系数据库,为企业提供可选择性和可扩展的服务,帮助企业在必要的时候搭建适合自己业务的服务;当然,现在可能还看不到效果,但长期来看这样的趋势再明显不过了。
值得注意的是,大部分这些分析主要都是针对首次搭建 IT 系统的新公司;甲骨文依然牢牢锁定着它的现有客户,包括世界上绝大多数的大公司和政府。
从这点来看,它基本上把本地业务复制到云端(甚至直接移到它的自有云硬件上)的总战略是合理的。这也同样是微软寄予厚望的混合策略。
给那些和他们一样老派的客户一些减少资本性支出方面的好处(增加他们的资本回报率)并且希望为自己争取时间,好适应这个用户被真正重视的——聚焦且灵活的云服务是服务用户的最佳方式——新世界。
本文原载于 stratechery.com,作者 Ben Thompson ,由 ONES Piece 翻译计划 塔娜、任宁 翻译。
题图来源:boonsoftware





