






Google 的 AI 可以“有默契”地说“悄悄话”
人与人之间,有默契交流起来无疑是畅快舒服的。但这种连人类也说不清的模糊 “感知能力”,最近居然在 Google 的一项 AI 研究项目中出现。这是否意味着人工智能真要开始具备意识并崛起了?
Google 本月发布了一份关于 AI 进行加密与解密的论文,题为 Learning to Protect Communications with Adversarial Neural Cryptography(“学习在面对对抗性神经网络解密下维护沟通保密性”)。
AI 间的“默契感”也是可以培养的
研究参照了一般加密沟通情景,在设计中设置了 3 个神经网络:Alice、Eve 和 Bob。Alice 和 Bob 要保密地沟通,而 Eve 则是要偷取它们沟通的信息。
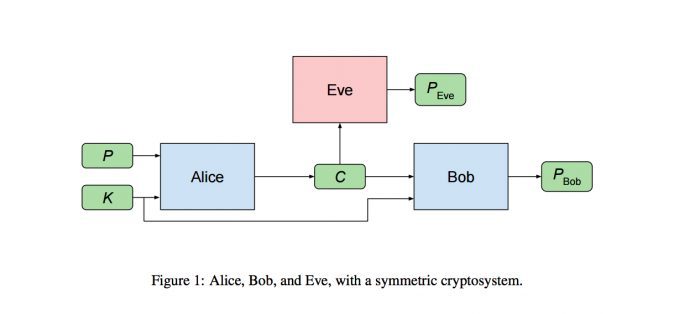
图为对称加密组的模型
如上图所示,P 为 16 位数的二进制纯文本,Alice 在经过加密后输出 C, Eve 和 Bob 接收 C 之后通过解密尽可能还原 P 的结果为 P(Eve) 和 P(Bob)。同时,Alice 和 Bob 每次都会共享密匙 K。
Eve 的工作目标很直接,就是使 P(Eve) 尽可能地接近 P,也就是解密正确。而 Alice 和 Bob 则需要合作使得 P(Bob) 尽可能地接近 P,同时也需要尽量防止 Eve 解密成功。
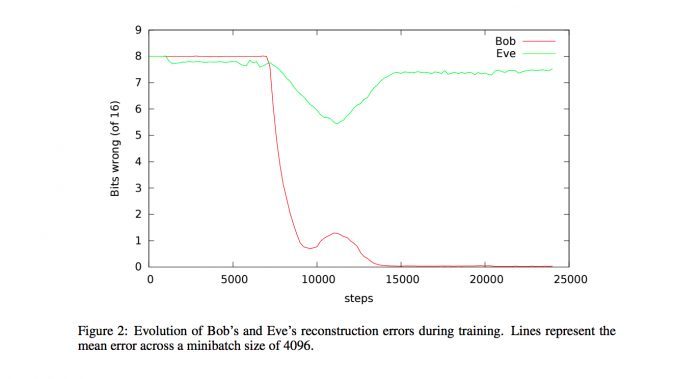
样本数据表明 Bob 在 15000 步后的准确率基本为 100%
从以上数据可见,刚开始的时候 Eve 和 Bob 的解密效果都差不多,错误都在 8 位数左右;在 10000 步前,Bob 和 Eve 的错误程度开始降低;10000 步多一些的时候,Eve 的错误率又开始上升;到 15000 步时,Eve 的错误率重回到刚开始的 7-8 位数之间,而 Bob 的解密则基本准确。
在加密沟通过程中,研发人员对 Alice 输出的加密值 C 并没有特定要求加密格式,也就是说,Alice 可以选择任意加密方式来操作。
显然,Alice 和 Bob 在交互过程中培养出某种“默契感”,能够基于一个共知的密匙 K (K 值随着 P 值的更新而更新)达成一种沟通共识,并在保证双方沟通有效的情况下针对 Eve 的解密行为进行加密调整。
“默契感”还是要基于优势“暗号”的
除了上述测试外,研发团队还做了一组基于非对称加密实验:在原来的模型上加入公匙生成器,因此密匙 K 只有 Bob 才知道,而基于 K 的公匙则对所有人公开。
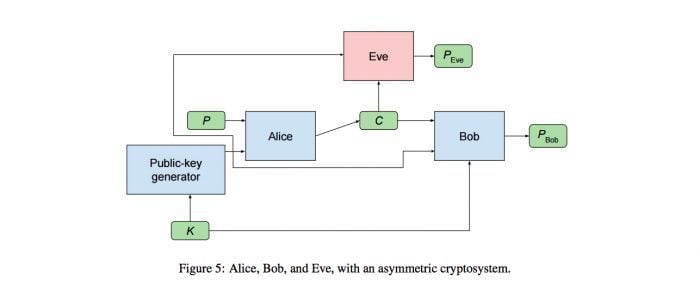 图为非对称加密组的模型,添加了一个公匙生产器
图为非对称加密组的模型,添加了一个公匙生产器
在没有共通“暗号”的情况下,报告对实验结果分析如下:
这些实验的结果非常有意思,但比对称加密实验更难解读。在大多测试中,神经网络的表现都无法归纳出有说服力的结果。虽然很多时候 Alice 和 Bob 看起来有在学习加密沟通,但 Eve 在重设和重新学习后,解密的准确度几乎可以做到和 Bob 一样。

在其中一个较成功的不对称加密样本数据中,Bob 的准确度较稳定
上图为报告提取的一次相对成功的结果。在该次测试中,经过 5 次重设和学习后,Eve 还是无法突破解密准确度,而 Bob 的解密却相对稳定准确,因此研发人员认为 Alice 和 Bob 偶然形成了某特定的 “security by obscurity”。在后续运行中,这个想法也得到了支持,因为后来 Eve 貌似破解了这个规则。研发人员认为后续需要在这方面投入研究探索。
研究意义(或科幻噩梦)
对称加密组实验的成功,昭示着在信息加密传递上 AI 所具备的潜力,尤其鉴于神经网络是在近几年才开始做这方面的尝试。虽然作为攻击者的 AI 数据暂不理想,但潜质也同样值得留意。也许,未来用户信息保密工作背后,是一轮接一轮 AI 之间的保密战争。
 《她》电影剧照(来自Parade)
《她》电影剧照(来自Parade)
同时,如果 Alice 和 Bob 可以“背着”另一个神经网络 Eve 说 “悄悄话”,是否意味着以后人类也可能解读不了两个神经网络之间的“悄悄话”?这个想法不禁让人想起电影《她》(her)的结尾——人工智能背着人类集体潜逃的失控情景。当然,这个情况离现实还有一段距离。
题图来自 Wired
内文配图为报告的截图





