






Google AI 「看」了几万部电影,为的是有一天能看穿人类的行为
上周, AlphaGo 「终极版」 AlphaGo Zero 再次让世人惊讶,自学 3 天完胜李世乭,40 天登顶「世界围棋冠军」。
但这并不意味着人工智能有能力取代人类,套用机器人界的一句话:
五岁以上的人类能够做的事情,机器人都能轻松胜任,但学会走路,办不到。
简单来说,要 AI 识别人类的行为动作至今仍是一个难题,而四个月大的婴儿就能识别各种面部表情了。
Google 正在让自家的 AI 克服这个难题,最近 Google 发布了新的人类动作数据库集体 AVA(atomic visual actions),可以精准标注视频中的多人动作,而其学习的对象则是来自 Youtube 的海量视频。
(图自:Youtube)
据 Google Research Blog 介绍,AVA 的分析样本主要是 Youtube 中的影视类视频。Google 先从这些视频中收集大量不同的长序列内容,并从每个视频中截取 15 分钟,并将这些 15 分钟片段再平均分成 300 个不重叠的 3 秒片段,同时在采样时让动作顺序和时间顺序保持一致。

(3 秒片段边界框标注示例,示例中只显示一个边界框)
接下来则需要手动标记每个 3 秒片段中间帧边界框中的每个人,从 80 个原子动作(atomic action)中选择合适的标签(包括行走、握手、拥抱等)给这些人物行为进行标注。

(sit)

(watch)

(kiss)
Google 把这些行为分成了三组,分别是姿势/移动动作、人物交互和人与人互动。目前 AVA 已经分析了 570000 个视频片段,标记了 96000 个人类动作,并生成了 21000 个动作标签。
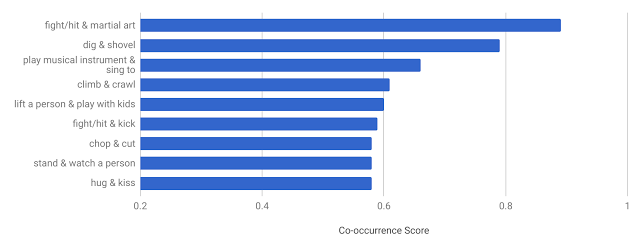
在 AVA 的数据分析中,会对每个视频片段的每个人物动作进行识别,也发现了人类的的行为往往不是单一的。
统计至少带有两个动作标签的人物数据,就可以分析人类不同动作一起出现的频率,在 AVA 的文档中称之为共现模式(co-occurrence pattern) 。
从 AVA 的数据可以看到,打架和武术、亲吻和拥抱、唱歌和弹奏乐器,这些都是比较常见的共现模式。
同时为了尽可能覆盖更大范围的人类行为, AVA 的所分析的电影或剧集,采用了不同国家和类型的影片,这也可能是为了避免出现性别歧视和种族歧视。早在 2015 年,Google Photos 就曾因为误把两名黑人标注为「大猩猩」(Gorilla)而备受诟病。

(图自: Twitter)
Google 还将对外开放这一数据库,最终目的是提高 AI 系统的「社交视觉智能」,从而了解人类正在做什么,甚至预测人类下一步要做什么。
当然目前距离这个目标还很遥远,正如 Google 软件工程师 Chunhui Gu 和 David Ross 在介绍 AVA 的文章中写道:
教会机器去识别视频中的人类行为是发展计算机视觉的一大基本难题,但这对于个人视频搜索和发现、体育分析和手势界面等应用至关重要。
尽管过去几年在图像分类和查找物体方面取得了令人激动的突破,但识别人类行为仍然是一个巨大的挑战。
虽然柯洁称「对于 AlphaGo 的自我进步来说人类太多余了」,可人脑有 800 亿个神经元细胞、100 万亿个连接,AI 神经网络要想达到大脑的认知水平也绝非易事。
目前计算机视觉技术的发展也主要集中在静态图像领域。
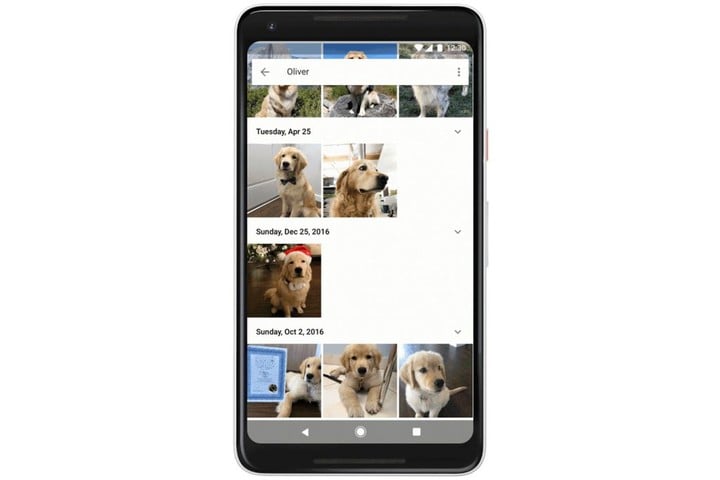
Google 从 2006 年开始用深度学习算法代替人工识别,Google Photos 现在已经可以识别出猫狗的照片并自动分类。

(从 a 到 b 分别是 Google Creatism 系统从街景图到最终作品的全过程)
Google 的人工智能实验室 DeepMind 正在利用人工智能将 Google 街景图制作成专业的摄影作品,其水准甚至已经可以媲美专业摄影师。
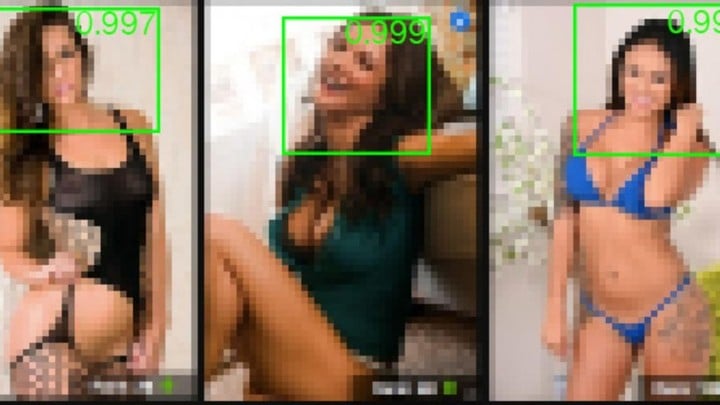
(图自:Motherboard)
而 iPhone X 上的 Face ID 技术,也许会让面部识别技术在智能手机上变得更为普及。就连全球最大的色情网站 Pornhub ,也宣布将引入人工智能技术对网站上成人影片的内容和表演者进行自主检测,让 AI 算法为成人影片的内容和演员进行标签分类。

(图自:The New Yorker)
相比而言,计算机对于人类动态行为的识别则要困难得多。最近在《纽约客》新一期的封面在美国的社交媒体火了起来,封面文章《黑暗工厂:欢迎来到未来机器人帝国》(Dark Factory)描述了越来越多人类的工作逐渐被机器人取代。
虽然机器人能做的事越来越多,但在该文中也可以看到机器人对很多看起来简单的工作依然无能为力,比如打开一个盒子和解开一个结,美国布朗大学人机实验室的 Winnie 机器人前不久才刚刚学会了摘花瓣。
 (图自:The New Yorker)
(图自:The New Yorker)
而 Google 这次的人类动作数据库集体 AVA,目前最直接的作用可能就是帮助旗下的 Youtube 处理和审核每天上传的大量视频,同时也能更好地服务广告主。
过去 Google 就曾因为无法对视频内容精准识别而吃过大亏,《连线》杂志的一篇文章曾披露, Google 在视频中植入广告的自动系统,将一些广告放置在了宣传仇恨和恐怖主义的视频旁边,已经让沃尔玛和百事可乐等大客户放弃了 Google 的广告平台。

对于 90 % 收入来自广告业务的 Google 来说,这个问题当然不能怠慢,此前 Google 主要通过聘请一大群临时工去监测和标记各种视频内容,并以此作为 AI 的训练数据。
这样的做法除了需要高昂的人力成本,也有观点认为这些临时工不稳定的工作状态和与 Google 的缺乏沟通,将会影响到 AI 识别的精确度。
由此可见,如果 Google 这个 AI 的学习能力足够强,那不久的将来,这些临时工也将统统失业,而将来这项技术的应用当然也不局限于此。
随着 AI 对人类认知越来越深,对于人工智能伦理的讨论也许会变得更加激烈。
Google AI 你也能用上。搜索微信公众号爱范儿(微信号:ifanr),回复关键词「AI」,看看 Google AI 拍摄的风光大片,并获取用 Google 算法自动去水印的方法。
题图和部分配图来自:Google Research Blog






