






我用 Google 搜索了一下名字,发现自己“死”了
Google 以为我已经死了。但我想告诉它,我还活着。
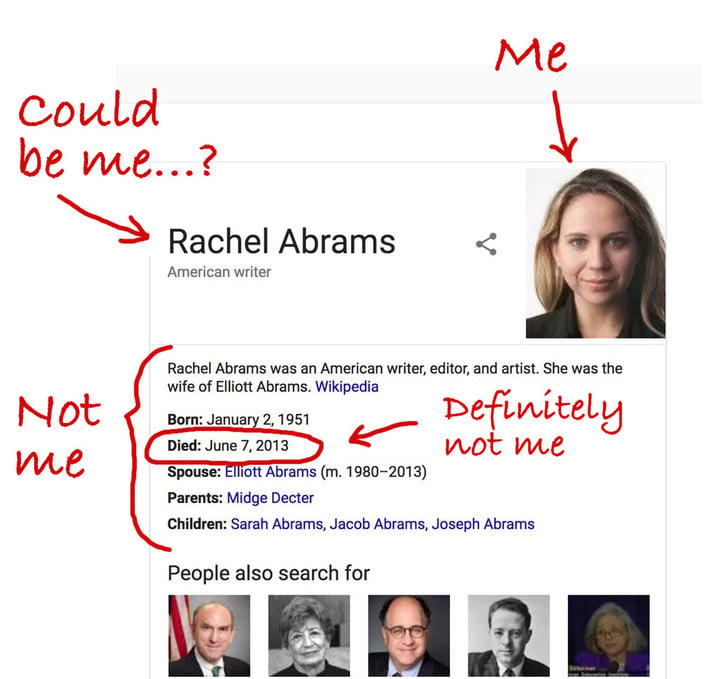
这来自《纽约时报》记者 Rachel Abrams 的一篇“公开吐槽信”。上周的某一天,这位记者惊愕地发现,自己在 Google 的搜索结果中,默默地“被死亡”了。
(图片来自:《纽约时报》)
在把自己的名字“Rachel Abrams”键入到 Google 的搜索框中之后,页面显示出了她在《纽约时报》网站上的工作证件照片,但关联到的人物介绍却是另一个同名的美国作家。而这位“Rachel Abrams”,已经于 2013 年去世了。
我的父亲很诧异地给我发了一则确认的短信,身边的熟人也提醒我去查看这条显示我已经‘死亡’的信息。我意识到,这个错误可能必须得去更正一下了。
于是为了证明“自己还活着”,她开始了“维权”之路。
漫漫“维权”路
由于这个错误出现在了 Google 的搜索结果中,找 Google 纠错就成了 Rachel 能想到的首要解决方案。
但她很快发现,作为全世界最知名的科技公司之一,Google 并没有提供客服热线这种东西。相反,他们更倾向于使用自助式的“在线反馈”。
我不是很能肯定,在这么多的‘反馈’(Feedback)选项中,到底哪一个才真正适用。

(在 Google 搜索结果中点击“反馈”之后,页面会出现数量众多的选项按钮)
“他们可能确实在某个地方有提供这样的电话号码,但是他们的确更希望大家可以通过网络或者线上的渠道来解决问题。” ReputationDefender 公司的负责人 Rich Matta 说道。他的公司,专门帮助用户修改他们在网络上的不实信息。
从我多年的经验来看,这种没有涉及非常明显的违法或侵权行为的申诉,往往很难通过提交纠错申请来达成。大多数人会被过程中的各种复杂状况或者问题所困扰,他们甚至不知道该从何做起。
这样的问题就发生在了 Rachel 的身上。
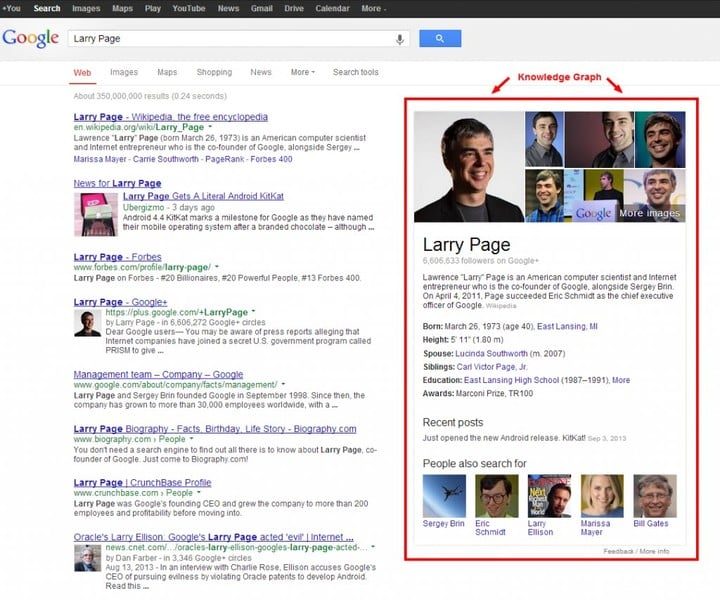
她先是尝试联络了 Google 的公司联络部门,表明了自己的记者身份和遇到的问题。随后,一位 Google 发言人回复给了她一个链接,这个链接指向了 Google 知识图谱(Knowledge Graph)的帮助页面。
Google 知识图谱是 Google 于 2012 年推出的一个信息知识库,通过语义检索从多种来源中收集信息,以提高搜索的精确性。包含有她错误信息的页面搜索结果,就来自 Google 知识图谱。
当她按照那位发言人的建议进入知识图谱的帮助页面填写反馈时,问题来了:想要修改词条需要先确认自己的身份,而在确认自己身份的四个选项中,她陷入了某种“自我认知障碍”。
选项一:你是这个词条相关的官方网站、YouTube 频道或者 Google+ 页面的所有者。(好像不太对)
选项二:你是以一个官方线上实体所有者的身份登录 Google 的。(这个好像也不对)
选项三:你的网站或者 app 仍然在活跃状态。(不懂这是什么意思)
选项四:你被添加进了官方网站的搜索控制台。(???)
一头雾水的她决定先随便选一个。然后在页面的末尾,她终于找到了一个可以让她自己填写申诉缘由的文本框,而这,还是用来反馈前面“自助服务”是否有用、如何改进的地方。
(图片来自:《纽约时报》)
很显然,这个举动并不能帮她解决问题。于是,她决定直接给 Google 总部打个电话。
虽然又经历了漫长的热线等待,但她终于找到了一个人工应答。这位 Google 员工,再次让她填写一份在线帮助表格,而且,最好是能在接下来的一段时间持续不断地反复提交,尽量使用不同的 IP 地址,或者让朋友帮助你提交。只有这样,才能通过“高关注度”来把申诉顶到前面去,引起重视。这位员工还好心地提醒她,这种修改知识图谱的操作,可能会花费最短三周、最长三个月的时间。
(图片来自:《纽约时报》)
终于,她“愤怒”了,决定直接给 Google CEO Sundar Pichai 发一封邮件。同时,好好利用一下自己的记者身份,把整件事写下来,制造一些“舆论压力”。
这一次,她的努力终于有了点回报。虽然没能等来 Pichai 的邮件回复,但几个小时之后,她的照片被从错误的页面上撤了下来。
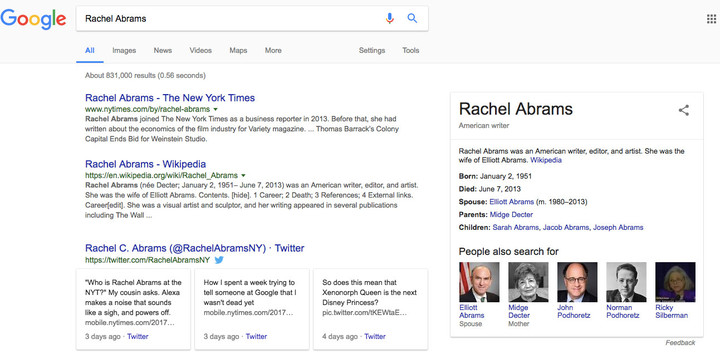
终于成功“复活”了。
知识图谱真的靠谱吗?
整件事情看下来,虽然 Rachel 吐槽的点集中在 Google 的错误反馈系统,但如果从源头开始算起,最先出错的,其实是那个被视为 Google 新一代搜索核心的知识图谱(Knowledge Graph)。
自从 2012 年正式发布之后,这个几乎是海纳百川的大型知识信息库,就成为了 Google 原来基础搜索的强有力的补充。用户可以省去自己筛选结果的过程,直接看网页右侧由知识图谱生成的“小百科”。
根据介绍,Google 知识图谱主要有以下几种数据来源:
- 以词条为基础的大规模知识库(包括维基百科、Freebase、DBpedia、YAGO 以及其他专业领域知识库等)
- 互联网链接数据(即在开放互联的万维网之中的多个数据链接)
- 互联网网页文本数据
在这几种动态数据源的支持下,知识图谱所收录的数据信息在不断地更新,仅 2012 年刚发布的时候就已经收录了超过 5 亿个词条和多达 35 亿条信息量。海量的数据,意味着知识图谱所带来的搜索结果将更加精准。
(图片来自:Medium)
更为重要的是,知识图谱并不像传统的搜索引擎一样,只是机械式地提供相关的匹配结果,它利用多种智能信息处理技术,比如实体链指(Entity Linking)、知识推理(Knowledge Reasoning)等,更加“聪明”地为用户提供他们真正需要的搜索结果。
负责这个项目的 Google 高级副总裁 Amit Singehal 把这种全新的搜索体验归纳为三点:找到正确的东西、得到最好的归纳总结、走得更深更远。在知识图谱的介绍文章中,他写道:
借助知识图谱,我们可以通过实体(things)而非字符串(strings),去了解现实世界中的各种事物,以及他们之间的关系。
举个简单的例子,当我们搜索“苹果”时,加入知识图谱的搜索结果,除了会显示作为水果的苹果之外,还会自动匹配出科技公司“苹果”,以及与苹果公司相关的资讯、商店等信息。这是一个经过筛选和重组的完整知识块,具有逻辑和条理,所包含的语义也更丰富。
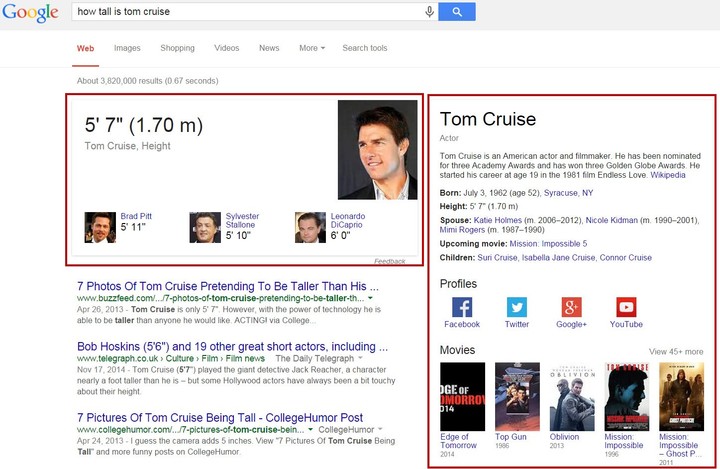
在更进一步的应用中,它还可以实现更加智能的基于知识库的自然语言查询。比如当你直接在搜索框中输入“汤姆·克鲁斯有多高”时,返回的结果就是“170 厘米”。
除了 Google 之外,引入知识图谱正在成为搜索引擎界的一个发展趋势。百度的“知心”,搜狗在娱乐和医疗领域的知识图谱,都利用了同样的原理。
但海量数据的加入也意味着,它们之间的逻辑链接会变得更加复杂。知乎上一位从事 Google 知识图谱开发的工程师就认为,目前最难也最需要抓紧解决的问题,就是“如何将来自不同数据源的相同实体聚类”。比如电影数据中的“刘德华”,和音乐数据中的“刘德华”,就需要利用自动化的算法来聚合在一起。
Rachel 的这次“被死亡”,正是在这个环节出了问题。她的照片虽然也对应着“Rachel Abrams”,但显然不是在搜索那位已故的作家时,应该出现在知识图谱结果中的正确匹配信息。
除了基于计算机深度学习的自动匹配之外,Google 还为知识图谱加入了人工编辑和校对。但为了尽量避免人工操作所带来的潜在问题,他们也采取了一系列比较严格的审核和纠错机制。在回复 Rachel 的申请时,Google 发言人就提到:
要在加快修改速度和保证结果的准确性之间寻找一个平衡点,是一件非常重要的事情。
但考虑到用户的使用体验,还是希望 Google 能够改进一下用户的反馈机制。毕竟不是每个人都能像 Rachel 一样,可以直接在《纽约时报》上发文章喊话。
题图来自:Search Engine Land







{kind=link}