





手机是我们随身携带的拥有最强处理能力的终端之一,我们可以将手机与智能眼镜相结,通过眼镜来获取信息,然后把信息放到手机上来处理,再将处理结果传回到眼镜端,这是一个面向终端侧 AI 的非常理想的解决方案。
关于手机终端侧 AI,有两个重要的时间节点,一是去年高通骁龙峰会,出现了一大批手机终端侧生成式 AI 的演示,文生图,文生文,情景感知智能提示都不在话下,这些运算全都基于本地,主要依靠 7B 左右的端侧大模型,或者手机上运行的 Stable Diffusion 实现,无需任何云端的算力。
比如今年年初,高通发布了新的 AI Hub,这个 AI Hub 包含预优化 AI 模型库,支持在搭载骁龙和高通平台的终端上进行无缝部署。该模型库为开发者提供超过 75 个主流的 AI 和生成式 AI 模型,比如 Whisper、ControlNet、Stable Diffusion 和 Baichuan-7B,可在不同执行环境 (runtime) 中打包,能够在不同形态终端中实现终端侧 AI 性能、降低内存占用并提升能效。

我们现在使用的 ChatGPT 或者 Kimi 这样的 AI 应用,结果的生成都是在云端,背后可能是数千亿乃至万亿级别的参数模型。
第二个节点是今年苹果 WWDC 上,苹果发布了 Apple Intelligence,这是 iOS 上的混合智能,即有两个端侧模型,分别负责图形和文字,也有云端服务来连接大模型。
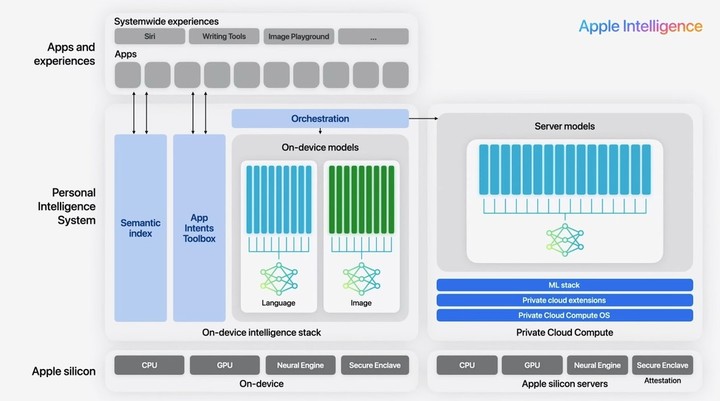
当然,站在现在的时间点,我们在智能手机上还不太能体验得到端侧大模型提供的 AI 体验,技术演示和技术落地之间,还有一段路要走。
在 ChinaJoy 期间,我们采访了高通技术公司手机、计算和 XR 事业群总经理 Alex Katouzian,聊了一下关于 AI 设备的话题。
第一个问题就是,去年骁龙峰会的时候,我们看到非常多终端侧生成式 AI 的演示,大概过去了三个季度的时间,到现在,手机上的生成式 AI 其实主要还是在云端完成的,为什么终端侧 AI 会比我们预想的进展要慢?
Alex Katouzian 说:
我认为随着生成式 AI 市场不断发展,企业也越来越意识到真正重要的用例是什么、什么是能够在智能手机当中部署的实用特性。在过去,大家习惯于在云端处理 AI 功能,然而,如今云端计算的成本正在大幅增加。因此,包括大型操作系统公司、互联网公司在内的所有企业都在力推终端侧 AI,以尽可能将需求分流到终端侧。
高通公司的优势正是在于我们可以与这些企业合作实现这一目标。我们已经看到诸多公司都在推动终端侧 AI,他们只希望在必要时利用云端处理。
例如,你可以拿起手机识别你将用于烹饪的食材,成功识别后,你可以让手机帮你生成对应的菜谱,你还可以让手机给你一些低卡路里菜单组合;烹饪完成后,你可以通过摄像头,向手机询问这份食物所包含的卡路里。凭借智能手机如今对多模态 AI 能力的支持,这个用例可以完全在终端侧实现。
与此同时再来看智能眼镜,戴上智能眼镜,它就像你的眼睛和耳朵一样,可以看到和听到你周围的环境。但是为保证电池续航,智能眼镜的处理能力就相对有限,它只能支持大概 10 亿参数体量的小模型运行,得到的信息也较少。
但手机是我们随身携带的拥有最强处理能力的终端之一,我们可以将手机与智能眼镜相结,通过眼镜来获取信息,然后把信息放到手机上来处理,再将处理结果传回到眼镜端,这是一个面向终端侧 AI 的非常理想的解决方案。
言下之意,端侧 AI 自然有巨大意义,不管是降低成本还是提升用户体验上,都值得推广,但就是要等等。

那么,我们为什么要再等等呢?Alex Katouzian 提到了一个硬件上的掣肘:
目前一个 7B 参数的大模型需要占用 4GB 左右的内存,所以说如果你的手机总的内存只有 12GB 的话,再除去操作系统需要占用的内存,那么这对大模型的运行就是一个挑战了。同样都是占用 4GB 的内存,如果有 16GB 总内存的话肯定效果会比 12GB 总内存的更好。
另外一点就是,过往我们认为 10B 参数的大模型比 4B 参数的大模型要好,但这可能并不一定是百分之百成立的。因为现在的很多小语言模型已经做的越来越出色,它们基于云端的大模型进行训练,并可以针对非常具体的某一个或某几个用例来进行压缩,从而提升准确度同时减小规模。我觉得这就是未来的趋势,小模型通过不断训练变得更加准确。我们与众多模型厂商合作,挑选最准确、最轻量化的小语言模型来实现在手机终端侧的部署。
随着这些模型变得越来越准确,我们得以将一个 10B 参数的模型部署到手机端,所以我们的另一个挑战是,如何确保在端侧能够处理尽可能多的请求,只在必要时才返回云端进行处理。所以我们的目标是找到准确度最高的、占用内存最小的且能处理最多用例的模型。
正如我前面提到的,目前 4B 参数的模型已经做的相当出色了。以微软举例,他们在 PC 后台跑的小语言模型 Phi 大概的参数量在 3.8B 到 7B 之间。
这段话有 2 个核心信息,一是一个 7B 的模型就需要占用大量的内存,这对于非旗舰机来说挑战巨大,意味着 8GB 内存手机运行大模型之后将会变得不可用,12GB 内存手机也干不了太多事情,16GB 内存才是理想的内存大小,但是目前市面上内存容量达到 16GB 的手机占比很小,这意味着现阶段端侧大模型大规模落地还不具备成熟条件。
另一个核心信息和当下的 AI 大模型的发展趋势有关,不少大模型研发商发现,大模型的水平和参数量不一定成正比关系,一方面有边际效益递减的现象存在,100B 的模型很可能只比 10B 的模型好上 20% 而已;另外就是随着训练水平的提高,更小参数的模型也可能比更大参数的模型表现更好,以及针对特定领域的垂直模型虽然参数量不一定很大,但是有所专长,在特定领域表现比通用大模型要好。
这两个信息放在一起,意味着其实也不必执着于当下端侧大模型能不能落地,这其实是循序渐进的软硬件共同进步的过程,未来 16GB 内存手机普及,而端侧大模型不一定要上到 7B 乃至 10B 和 13B 的参数量,只需要 4B 左右就能提供不错体验的时候,就是硬件和软件的双向奔赴,也是端侧 AI 成熟落地的时候。毕竟只能在旗舰手机运行的 AI 不是大家希望的 AI,Alex Katouzian 就描述了这种「双向奔赴」的愿景:
随着 AI 能力逐渐从旗舰层级向中低端迁移,厂商也需要谨慎控制因此带来的成本增加。
我们希望在这些模型不断提升准确度的同时,占用的内存空间会逐步减少,我们与模型提供商合作就是为了达到这一目标,我们的模型量化工具也在不断进步,从而实现成本和性能之间的平衡。





