





一个纯净、纯粹自我学习的 AlphaGo 是最强的……对于 AlphaGo 的自我进步来讲……人类太多余了。
2017 年 5 月,在中国乌镇举行的「人机终极对决」,当今世界排名第一的人类围棋选手柯洁,输给了 Google 旗下的人工智能程序 AlphaGo。
尽管自那之后,人类还在不断追赶,但 AlphaGo 却已飞升到了更高的境界。
10 月 18 日,DeepMind 在《自然》杂志上发表了新论文,正式向世人介绍了 AlphaGo 的最新版本——AlphaGo Zero,官方称之为 AlphaGo 的「终极版」(Final Version)。

AlphaGo Zero 有多强?
当初以 4:1 完胜李世乭的 AlphaGo Lee,已经是人类围棋界的顶级水平,但与 AlphaGo Zero 对弈,比分是 100:0,完败。
几个月前,在乌镇以 3:0 击败柯洁,成为世界冠军的 AlphaGo(Master),也被 AlphaGo Zero 挑于马下——胜率高达 90%。
毫无疑问,AlphaGo Zero 就是当今世上棋力最强的围棋选手。更可怕的是,AlphaGo Zero 的成长,完全没有人类进行干预。

以往,AlphaGo 的成长,主要是先通过分析成百上千份人类高手的棋谱,再进行自我对弈的方式来提高水平——人类高手的棋谱会告诉 AI,到底该把子落在哪个位置才对。可是对 AI 来说,学习人类的下棋方式,成本实在太高了,可能会走很多弯路。要是一开始就完全抛弃人类的经验,那结果又会怎样?
怀着这样的思考,AlphaGo Zero 诞生了。从一开始,AlphaGo Zero 就是一张白纸,人类只教给了它最基础的围棋规则,以致于最开始,AlphaGo Zero 甚至会填真眼自杀。
但仅仅过了三天,AlphaGo Zero 就有了惊人的进步,曾经击败李世乭的 AlphaGo Lee,此时已经不是 AlphaGo Zero 的对手。整整 100 场对决,没有赢过 AlphaGo Zero 一次。
自我对弈到 21 天时,AlphaGo Zero 已经达到了 Master 的水平,2016 年底,Master 曾在网上与数十位人类顶级棋手交战,最终以 60:0 的大比分完胜。
最终,当 AlphaGo Zero 自我对弈到第 40 天时,已经击败了之前所有版本 AlphaGo 程序,成为新晋的「世界围棋冠军」。
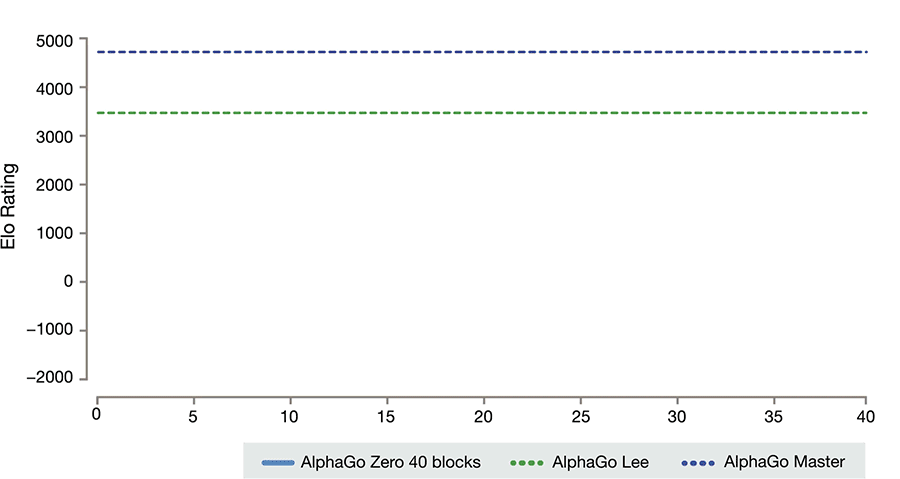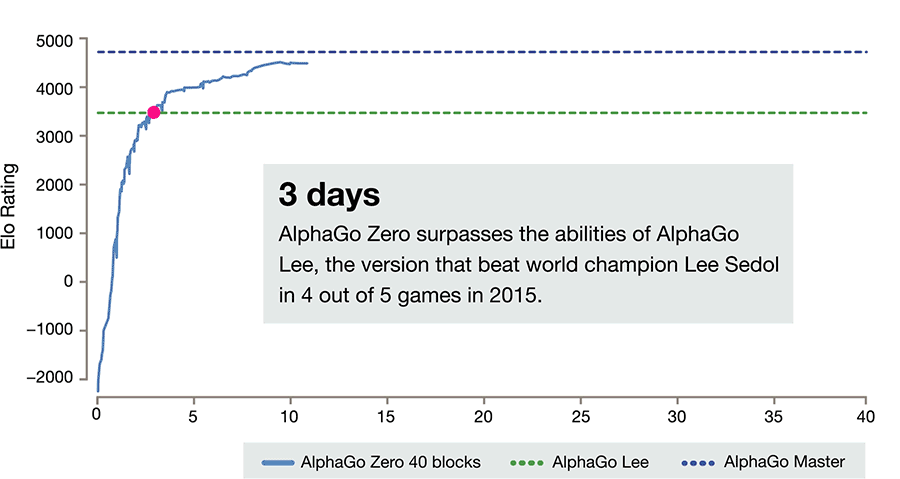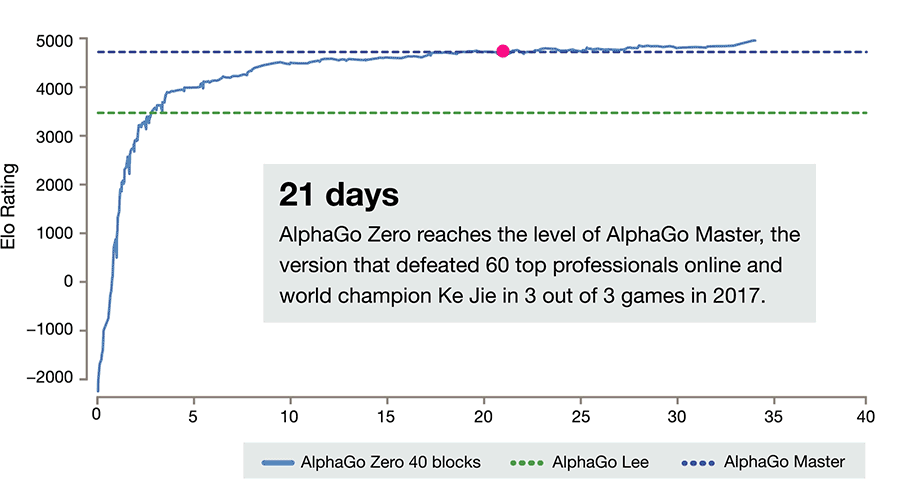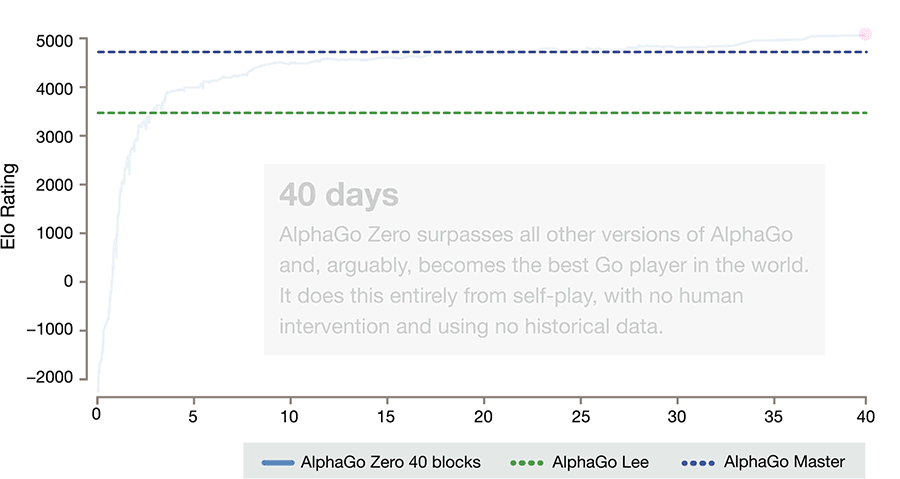
(AlphaGo Zero 成长曲线,图片来源:DeepMind)
有意思的是,AlphaGo Zero 自学而成的许多围棋知识,包括打劫、征子、棋形、布局先下角等,都与人类围棋观念一致,这也间接呼应了人类千百年来围棋研究的价值。
AlphaGo Zero 强大的秘密在哪里?
AlphaGo Zero 采用了新型的「强化学习」模型,让自己成为自己的老师。尽管一开始,对弈双方的水平都不怎么样,但经过将神经网络与强大的搜索算法相结合,不断地对棋路进行调整,最终得以预测对手的动作,并取得胜利。
AlphaGo Zero 进行自我对弈的好处在于,每一场对决,双方的棋力都处在同一水平线上,每场对弈过后,系统性能都会小幅上升,自我对弈的水准越来越高,AlphaGo Zero 也随之变得越来越强。

(AlphaGo Zero 不同阶段的棋局变化,图片来源:DeepMind)
这项技术让 AlphaGo Zero 得以完全摆脱人类的束缚,创造自己的知识体系。虽然调用的算力更少了,却能成为了更强大的棋手。
与之前版本相比,AlphaGo Zero 有几大差异:
- AlphaGo Zero 仅仅调用棋盘上的黑子与白子下棋,而过去版本的 AlphaGo,多少还有一点人工设计的功能
- AlphaGo Zero 只使用了一套神经网络。早期版本的 AlphaGo 里内置了两套神经网络模型,其中一套「策略网络」,用于判断下一步该怎么走;另一套「价值网络」,用于预测到底哪方才是胜利者;而 AlphaGo Zero 将二者合而为一,能够更高效地进行训练,并且提升对赛况的判断力
- AlphaGo Zero 不再使用「Rollouts」——大部分围棋程序会通过快速、随机地落子来判断棋局的走向,但 AlphaGo Zero 则是通过优质的神经网络来对下棋位置进行评估。
这些差异让 AlphaGo Zero 的系统性能更强、更具普适性。算法的改进让整套系统变得更加强大、运行更为高效。
硬件与算法的进步也让 AlphaGo Zero 所需要的算力大大降低,仅仅需要 4 个 TPU(由 Google 开发的人工智能专用芯片),而与李世乭对弈的 AlphaGo Lee 所需要的算力多达 48 个 TPU,是 AlphaGo Zero 的 12 倍。
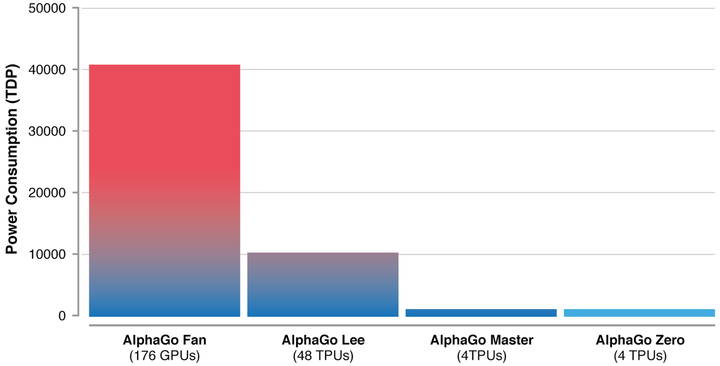
(历代 AlphaGo 所需的算力对比,图片来源:DeepMind)
长期以来,不少人有这样的误区:机器学习最重要的就是大数据和海量计算。但 AlphaGo Zero 的出现证明,合适的算法,可能比数据和算力更重要。DeepMind 的 CEO Demis Hassabis 表示:
我们正在努力尝试建立通用算法,这仅仅是一小步,但足以振奋人心。
未来,我们或许能在围棋之外的多个领域见到 AlphaGo 活跃的身影,也许是帮助医疗人员设计新药,也可能是帮助气象专家预测天气——如果通用算法诞生,那么许多科学问题也可以借助 AI 的力量来解决。
AI 是否真的能够超越人类,现阶段我们无从得知。但或许正如柯洁所言:
一个纯净、纯粹自我学习的 AlphaGo 是最强的……对于 AlphaGo 的自我进步来讲……人类太多余了。
题图来源:The Verge






{kind=link}