






无服务器应用运营 5 年经验总结
编者按:作者总结了过去 5 年管理 AWS 无服务器应用的心得和经验,大部分原则也同样适用在「知晓云」无服务器平台运营小程序。
自 2010 年以来,我一直是 AWS 的客户,在早期,我和 AWS 上的几乎所有其他人都将大量时间用于管理基础设施。修补 AMI、配置负载均衡器、更新自动扩展配置等。这是一种吃力不讨好的工作,直到出现问题为止,没人关心!沃纳·沃格尔(Werner Vogel)经常将其定义为「无差别的繁重工作」。
很长一段时间,我希望有更好的方法。当 AWS 在 re:Invent 2014 上推出 Lambda 服务并随后在 2015 年与 API Gateway 集成时,这对我来说是一个巨大的转折点。自 2016 年以来,我几乎只使用无服务器技术。这些天来,我发现自己比以往任何时候都更有效率,而且我构建的系统更可靠、更具可扩展性和更安全。
但是,这不是免费的午餐,在此过程中我不得不犯很多错误并吸取很多教训。毕竟,使用无服务器,您正在构建能够最大限度利用云的云原生应用程序。为此,我们需要有效地使用 AWS 并开发有助于我们充分利用 AWS 提供的工作方式。
在这篇文章中,让我与您分享过去五年在生产环境中运行无服务器工作负载所学到的五个最重要的经验教训。
从第一天开始就构建系统监控
如果你不能有效地调试,你就不能构建一个可靠的应用程序。就这么简单。
什么是系统监控(可观测性)?
在过去的几年里,构建系统监控(或「可观测性」)已经成为一个流行词,对我来说,它是衡量一个系统的内部状态可以如何从其外部输出中推断出来的指标。您知道,您能在多大程度上及时了解您的云托管应用程序在做什么?
您在无服务器应用程序中的可观察性取决于您从中收集的外部输出的数量和质量,包括:指标、日志、分布式跟踪等输出项。它决定着您如何分析和理解这些数据,以识别行为模式、异常值、并解决实时问题的能力如何。
日志被高估了
不,日志和指标还不够。
事实上,我得出的结论是:日志被高估了。它们有其用途,但它们并不是解决问题的最有效方法。尤其是当您面临快速识别和解决问题的时间压力时,就像大多数生产中断的情况一样。
在最好的情况下,搜索堆积如山的日志消息感觉就像是在大海捞针。您必须处理一长串挑战和决策点:
- 如何确保每个人都编写结构化日志?
- 如何确保每个人都一致地记录数据,例如:
- 字段命名
- 要捕获什么数据——Lambda 调用负载、IO 调用的请求和响应正文、IO 调用的持续时间、异常消息和堆栈跟踪等。
- 如何捕获和转发相关 ID,以便您可以轻松找到相关的日志消息?例如,用户事务涉及通过事件链接在一起的多个 Lambda 函数。
- 使用什么日志聚合平台?如何转发来自 CloudWatch 的日志?
- 您如何在生产环境中对调试日志进行采样以控制 CloudWatch 成本? AWS 客户在 CloudWatch 上的花费比在 Lambda 上的花费多 10 倍是很常见的。
要构建一个既具有成本效益又能有效帮助开发人员、了解其应用正在发生什么事的日志方案需要大量工作。通常需要有一个专门的「平台」团队来构建和拥有这些定制解决方案。这些内部解决方案通常会导致与解决问题一样多的问题,并在组织协同中造成摩擦。因为开发这些解决方案的人通常不是每天都需要使用它们,并且不会是亲历修复系统故障痛苦的人。
我自身经历过,这种情况发生了很多次……
我的系统监控策略
如今,我使用以下组合:
- Lumigo 用于我的大部分调试和警报。
- 数量少但高价值的结构化日志可以覆盖 Lumigo 没有覆盖的盲点。
- CloudWatch 针对 AWS 服务的指标和预警,例如 API Gateway 集成延迟或 DynamoDB 用户错误。如果您想知道应该为无服务器应用程序设置哪些警报,请参考这篇博文。

此策略易于设置并且非常有效。这就是为什么。
Lumigo 具有内置告警并与 Slack 或 PagerDuty 等工具集成。结合我已有的 CloudWatch 警报,一旦出现任何问题,我都会收到警报。
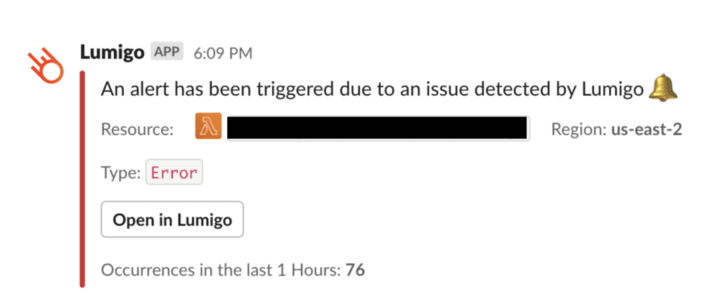
在微观层面上,如果我需要调查问题,那么问题很可能已经在 Lumigo 的问题页面中捕获。所有最近的问题都按功能和错误类型组织。
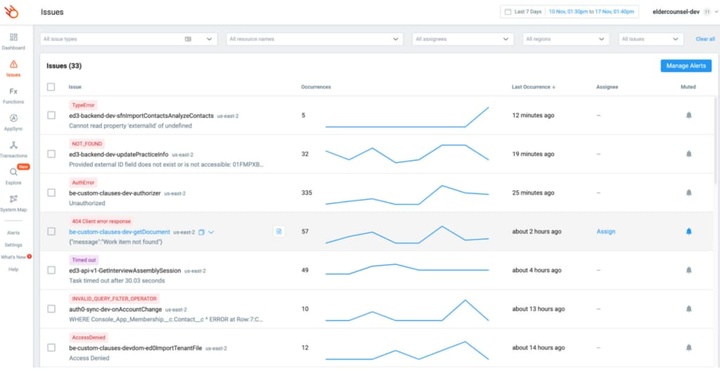
开箱即用,Lumigo 捕获了我需要能够推断我的应用程序的内部状态的大部分信息:
- Lambda 调用事件。
- Lambda 调用中存在的环境变量。
- 每个外发调用请求(例如,到其它 AWS 服务)的延迟以及请求和响应报文主体。
- 调用失败的错误消息和堆栈跟踪。
这些让我对我的应用程序内部发生的事情有了很多见解,因此我不需要自己记录太多。因此,我倾向于编写日志的唯一时间是涵盖我在 Lumigo 中看不到的内容——当我的代码正在执行复杂的数据转换或业务逻辑时。
幸运的是,Lumigo 将我的日志与其他所有内容并排显示,即使用户事务涉及多个 Lambda 函数。
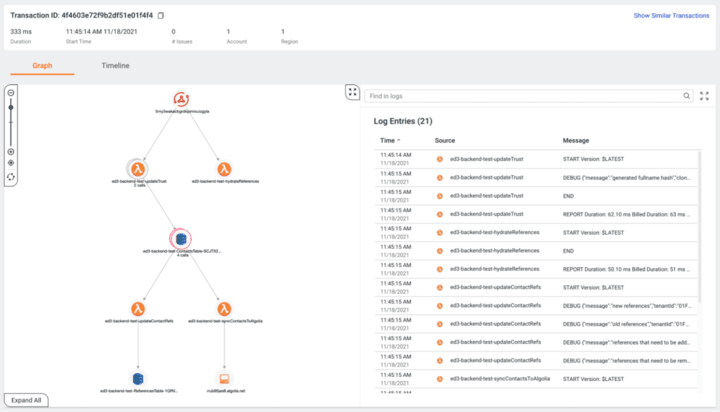
将所有这些信息集中在一个地方并且易于访问,可以更轻松地解决复杂的无服务器应用程序中的问题。最好的一点是设置 Lumigo 只需几分钟,尤其是在您使用无服务器框架和无服务器 lumigo 插件的情况下。
不需要手动配置,您可以立即获大量功能。在过去几年中我学到和采用的所有东西中,这种可系统监控策略给我的系统运维最充足的支持,并帮我成为了一个更好的开发者。
使用多个 AWS 账户
我可以传授给您的第二个最重要的教训是:使用多个 AWS 账户。理想情况下,每个环境的每个团队至少应使用一个帐户。
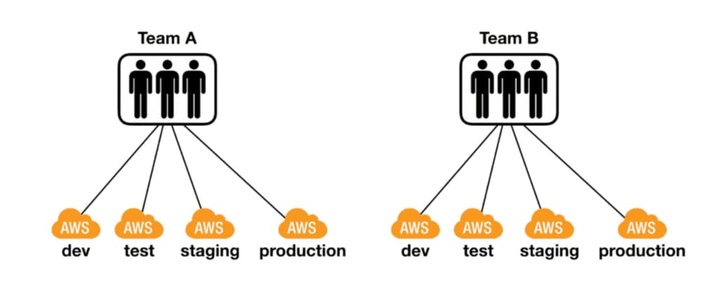
缓解 AWS 限制
AWS 服务都有很多限制,有些是可调整的(又名「软限制」),有些则不是(「硬限制」)。但即使是软限制通常也有一个上限,例如您可以在一个区域中拥有的 IAM 角色数量。
某些限制会限制您在帐户中可以拥有的资源数量。例如,DynamoDB 表或 S3 存储桶的数量。
其它限制要求您的应用在一个区域中可处理请求量。例如,API Gateway 的默认限制是每个区域 10,000 个请求/秒,而 Lambda 的默认限制是每个区域 3000 个并发执行。
这些请求量限制可能会对应用程序的可扩展性产生很大影响,并且它们在区域之间可能会有很大差异。因此,您需要了解您所在地区的限制,并将其纳入您的架构设计中。如果您知道您的生产工作负载需要一定水平的访问请求量,那么您应该主动要求 AWS 提高您账户的限制。
为不同的团队和环境拥有多个 AWS 账户将大大降低遇到这些限制的风险。
为安全漏洞分区
拥有多个帐户也可以作为防火墙,有助于安全事件发生时进行安全隔离。例如,如果攻击者能够访问您的一个开发帐户,那么至少他们将无法访问您在生产中的用户数据。
将团队和工作负载相互隔离
每个环境每个团队都有一个帐户可以让您将每个团队和环境与其他团队和环境隔离开来。因此,您不会遇到一个团队的服务使用过多的吞吐量并导致其他团队的服务出现问题的情况。
如果一个团队拥有多个服务,您可能还希望将更关键的业务或高吞吐量服务隔离到他们自己的帐户中。
使用 org-formation 管理多个 AWS 计费账户
您可以使用 AWS Organizations 和 AWS Control Tower 来帮助您管理最终使用的所有这些 AWS 账户。
但在 Control Tower 里,我发现在控制台中点击的东西太多了。虽然它具有帐户配置功能,可让您使用 CloudFormation 模板创建登录区域,但感觉也很有限。无法在不同帐户中创建资源,并在同一模板中引用它们。毕竟,CloudFormation 是一种账户级别的服务。
这就是为什么我更喜欢使用 org-formation 的原因。一种开源工具,可让您使用基础设施即代码来配置和管理整个 AWS 组织及其登录区域。它使我能够在几个小时内自行设置复杂的 AWS 环境,而使用自定义脚本可能需要一个团队数周的时间才能完成。
如果您对 org-formation 的工作原理感兴趣,请查看我们与其创建者 Olaf Conijn 共同举办的网络研讨会。
在运行时安全地加载密钥
当谈到无服务器应用程序的安全性时,有两个非常重要的话题要讨论。首先是您如何在运行时安全地存储和加载密钥。
此时,大多数 AWS 用户都知道他们可以将密钥放在 SSM Parameter Store 或 Secrets Manager 中,并使用 AWS KMS 对其进行静态加密。如果您想知道这两种服务有何不同,那么我还在此 YouTube 视频中对它们进行了比较。
许多人弄错的地方是如何在运行时保持这些密钥可以被 Lambda 函数调用。
例如,如果您使用无服务器框架中的 ${ssm:…} 语法来引用来自 SSM Parameter Store 或 Secrets Manager 的加密密钥并将其分配给 Lambda 函数的环境变量。在这种情况下,密钥将在部署期间被解密,解密后的值将作为环境变量分配给 Lambda 函数。
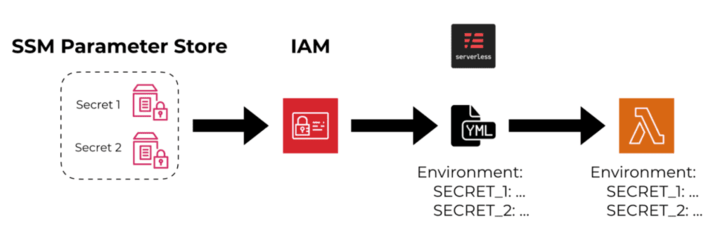
这使您的代码在运行时可以轻松访问该密钥。但它也使攻击者在发现系统漏洞时很容易访问它,因为环境变量对他们来说是唾手可得的果实。历史上,许多人将敏感数据放在环境变量中,包括数据库连接字符串和 API 密钥。这不仅限于无服务器甚至在云中运行的应用程序。这个问题在软件工程的各个领域都很普遍,许多攻击者会瞄准并从环境变量中窃取信息。
我的经验法则是:永远不要将密钥以纯文本形式放在环境变量中。
相反,您应该从 SSM Parameter Store 或 Secrets Manager 获取密钥,并在冷启动期间在运行时对其进行解密。
为了避免在每次调用时重复调用这些服务,您还应该缓存解密的值(但不要放到环境变量中!)。您还应该经常使缓存无效,这样您就可以轮换密钥,而无需重新部署您的函数。
对于 Node.js 功能,您可以使用 middy 中间件引擎通过内置的 ssm 和 secrets-manager 中间件来实现此目标。而且只需要几行代码!
module.exports.handler = middy(async (event, context) => {
… // do stuff with secrets in the context object
}).use(ssm({
setToContext: true, // save the decrypted parameters in the “context” object
cacheExpiry: 60000, // expire after 1 minute
fetchData: {
accessToken: ‘/dev/service_name/access_token’
}
}))
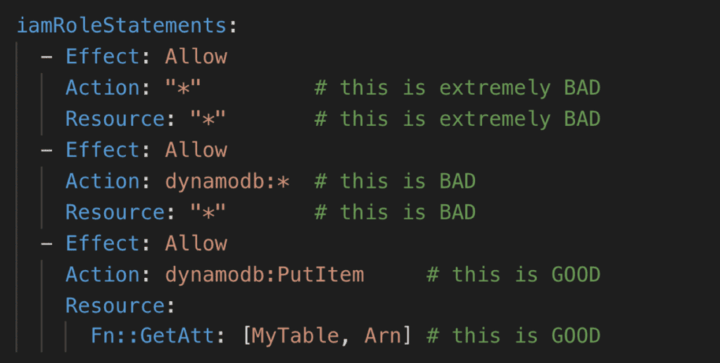
遵循「最小特权」原则
另一个重要的安全考虑是:您应该遵循最小权限原则,并为您的 Lambda 函数提供必要的最低权限。
例如,如果您的函数需要将数据保存到 DynamoDB 表中,则只需授予它执行该操作的权限即可。这可以说是您需要做的最重要的事情,以减少安全危害事件的爆炸半径。
零信任网络
传统的网络安全方法侧重于围绕网络边界进行加固。它监控进出网络的流量,并阻止恶意行为者进入我们的网络。
但是在网络内部,我们有一个完全信任的环境,一个节点都可以访问其它一切节点。这里的风险是,一个受感染的节点会让攻击者访问我们的整个系统。这使我们的安全性与网络中最不安全的组件一样脆弱。
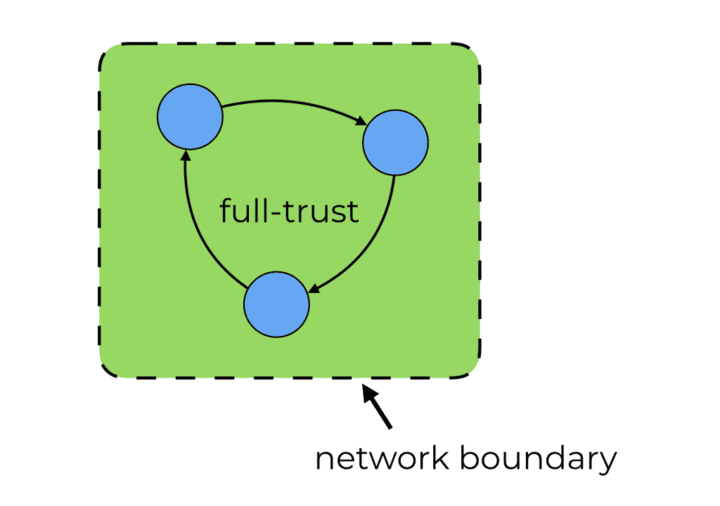
通过「零信任网络」,我们摒弃了网络中的任何人本质上都是值得信赖的假设、并应有权访问我们所有数据的权限的老观念。
相反,对每个系统的每个请求都必须经过身份验证和授权。
这意味着即使对于我们 AWS 环境中其它服务使用内部 API,我们仍然需要对这些请求进行身份验证。幸运的是,我们可以通过 API Gateway 和 AWS_IAM 授权轻松做到这一点。这可以保护内部 API 并确保调用者具有访问这些 API 所需的 IAM 权限。
您仍应使用 VPC(在有意义的情况下)并应用传统的网络安全实践作为额外的安全层。但它们不应该是您抵御恶意流量的唯一防御措施。
优化冷启动
当谈到 Lambda 函数的性能时,首先想到的是冷启动。
好消息是,使用预置并发,有一个本机解决方案可以在大多数情况下缓解冷启动。我在这篇博文中广泛介绍了预置并发的用例,这是一个让我感到非常兴奋的功能,并且现在仍然很高兴能够将其作为一个选项。
坏消息是,这不是免费的午餐,而且有其自身的缺点:
- 在低访问量场景中,使用预置并发会显著增加您的 Lambda 成本,因为您要为正常运行时间和调用付费。
- 从可用的区域并发中减去预置并发(正如我们上面提到的,在大多数区域中从 3000 开始)。这需要仔细的并发管理,以确保您有足够的并发性以供其它功能按需扩展。
- 预置并发不适用于 $LATEST 别名,因此您可能必须使用自定义别名。
由于这些原因,Provisioned Concurrency (预置并发)最好被视为解决特定问题的方案,而不是默认情况下应使用的方案。
在我看来,您应该首先尝试优化 Lambda 函数的冷启动性能,使其在可接受的参数范围内。只有当这被证明不可行时,您才应该考虑将预置并发作为解决方案。
在这篇博文中,我探讨了提高 Lambda 性能的三种方法,包括一些关于如何改进 Lambda 冷启动的技巧:
- 删除不需要的依赖项。较小的部署对象使冷启动时间更快。
- 如果许多功能(在同一个项目中)需要不同的依赖项,则考虑将它们单独打包,以便每个功能都有一个较小的部署对象。
- 对于 Node.js 函数,使用诸如 webpack 之类的捆绑器可以减少模块初始化时间(因为它会在您需要模块时删除许多 sys IO 调用)。
- 将您的依赖项放在 Lambda 层中。但是这样做是为了优化部署,不要使用 Lambda 层作为包管理器(这就是原因)。
这些技巧并不是我独创的,您之前可能已经听说过其中的许多要点。它们可能很无聊,但它们很有效。如果做所有这些还不够,那么考虑使用预配置并发!
总结
以下是我从在生产环境中运行无服务器中学到的五个最重要的经验教训:
- 从一开始就考虑系统监控(可观察性)。
- 使用多个 AWS 账户。
- 不要将密钥以纯文本形式放在环境变量中。
- 遵循「最小特权」原则。
- 监控和优化 Lambda 冷启动性能。
其中许多经验适用于在 AWS 中运行的任何应用程序,而不仅仅是无服务器。我希望这些经验能帮助您更好地利用 AWS 和无服务器技术,并希望避免我在此过程中犯的一些错误!
(作者:Yan Cui;封面摄影:Pixabay)





