如何用 24 小时,开发一款阴阳师小程序?
文 | rapospectre
玩阴阳师的肝帝们都知道,每天早上 5 点和下午 6 点会刷新两次封印任务,每次做任务时最蛋疼的就是找各种怪物对应的副本以及神秘线索。
阴阳师提供了「网易精灵」应用,可以进行一些数据查询。但它的体验实在太感人,所以大多数人会直接上网搜索怪物分布及神秘线索。
但每次都使用搜索引擎查找这些数据,就很不方便。所以我决定写一个查询阴阳师妖怪分布的小程序,力求做到使用快捷体验更快捷,把更多的时间留给狗粮和御魂。
恰好上周末有两天时间,所以立马开写。
1.构思与设计
1.1 构思
- 主要功能就是查询,所以主页应该像搜索引擎一样简洁,搜索框是肯定需要的。
- 主页包含热门搜索,缓存最热式神的搜索。
- 搜索支持完整匹配或者单字匹配。
- 点击搜索结果直接跳转到式神详情页。
- 式神详情页应该包含式神的图鉴、名称、稀有度、出没地点,并且出没地点按妖怪数量从多到少排序。
- 加入数据报错及提建议的功能。
- 支持用户个人的搜索历史。
- 小程序的名字,综合考虑小程序的功能最后决定叫做式神猎手(其实这是最后开发完成后才想好的)。
1.2 设计
构思好后,我就开始利用半吊子的 PS 水平,设计了下草图。大概是这个样子:
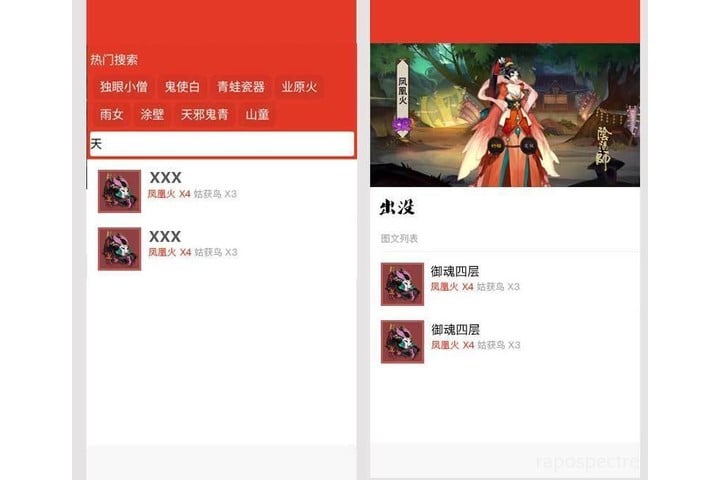
嗯,最主要的首页和详情页设计好就行,然后就可以开始具体考虑怎么做了!
1.3 技术架构
- 前端毫无疑问就是微信小程序咯。
- 后端使用 Django 提供 Restful API 服务。
- 用 Redis 做缓存服务器,用于缓存热门搜索。
- 至于个人搜索记录,就使用微信小程序提供的
localstorage接口。 - 式神分布信息使用爬虫爬取清洗,格式化为 JSON, 入库前再做人工检查。
- 式神图片及图标直接爬取官方资料。
- 自己制作爬不到的式神图片及图标。
- 小程序要求 HTTPS 连接,所以你还需要进行配置。
到此,准备工作就算完成,我们就可以开始正式开发了。
2. 后端 API 开发
我之前经常做 Django 的 API 服务开发,所以有比较完整的解决方案。
但我还是在这上面花了 5 个小时,其中,近 4 个小时在解决 django-simple-serializer 对 Django ManyToManyField 中 through 特性的支持。
简而言之,through 特性可以使多对多关系的中间表增添一些额外的字段或属性,例如:需要存储每个副本里,有多少只不同的怪物,它们的数量又分别是多少。
搞定 through 支持后 API 的构建就很快啦,主要有五个 API :
- 搜索接口
- 式神详情接口
- 式神副本接口
- 热门搜索接口
- 反馈接口
写好接口后,添加一些 mock data 以供测试。
3. 前端开发
前端花了我最长的时间。一方面我是个后端工程师,前端属于半路出家,另一方面,小程序上也有一些坑。当然,最主要的是一直在调整界面效果,这里花了大量时间。
我觉得,写小程序就和写 Vue.js 一模一样,只不过一些 HTML 标签没办法使用,而是需要按小程序官方提供的组件进行书写。
在这里,我有一点感受:
- 小程序本身组件化的设计思路,应该是借鉴了 React。
- 小程序的语法风格,应该是借鉴了 Vue.js。
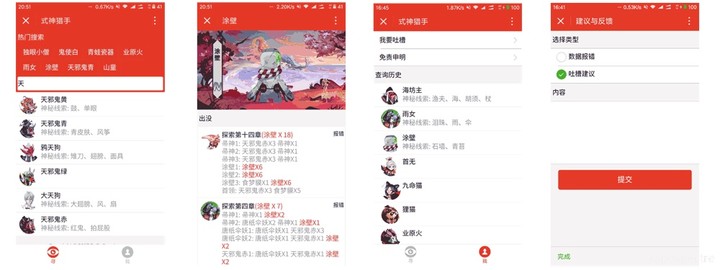
前端开发完毕后,主要分为这几个页面:
- 主页 ( 搜索页 )
- 式神详情页
- 我的资料页(存放查询历史)
- 反馈界面
- 免责声明页面
这里再放一张最后开发出来的界面图:
对于微信小程序的入门及基础,笔者就不在这里多讲了。相信对微信小程序有关注的开发者,自己写个简单的 Demo 肯定是没问题的。
在此,我就主要讲一讲我在开发中遇到的坑:
3.1 background-image 属性
在写式神详情页的时候两个地方需要用到 background-image 属性设置背景图。开发者工具中,一切显示正常,但一到真机调试就没有办法显示。
最后发现:小程序的 background-image 在真机不支持引用本地资源。解决方案有两种:
- 使用网络图片。
- 使用 Base64 编码图片。
一般,CSS 中的 background-image 就支持 Base64,这种方案相当于把图片直接用 Base64 编码进行储存。使用时,这样引用即可:
background-image: url(data:image/image-format;base64,XXXX);image-format 为图片本身的格式,而 xxxx 就是图片经过 Base64 后,得到的编码。
它是变相引用本地资源的方式。它的好处在于可以减少请求图片的次数;而缺点是会令 CSS 文件膨胀,代码也会显得不那么整洁了。
我最后选择了第二种方式,因为我觉得 WXSS 体积所增大的部分,是在可接受范围内的。
3.2 template
小程序支持模版,但要注意模板拥有自己的作用域,只能使用 data 传入的数据。
另外,在传入数据时需要将相关数据按特定格式传入,在模版内部是直接以 {{ xxxx }} 的形式进行访问,而不是像在循环中 {{ item.xxx }} 这种访问形式。
<template is="xxx" data="{{...object}}"/>一般 template 都会放在 单独的 template 文件中让其他文件进行调用,而不会直接写在正常的 WXML 中。 比如,我的小程序目录大概是这样的:
├── app.js
├── app.json
├── app.wxss
├── pages
│ ├── feedback
│ ├── index
│ ├── my
│ ├── onmyoji
│ ├── statement
│ └── template
│ ├── template.js
│ ├── template.json
│ ├── template.wxml
│ └── template.wxss
├── static
└── utils想要在其他文件调用 template,直接使用 import 标签调用即可。
<import src="../template/template.wxml" />然后,你就可以在其他地方直接调用 template。
<template is="xxx" data="{{...object}}"/>
<!--is 后填写模版名称-->这里遇到另一个问题,template 对应的样式写在 template 对应的 WXSS 中并没有作用,需要写在调用 template 的文件的 wxss 中。
比如,index 需要使用 template,则需要将对应的 CSS 写在 index/index.wxss 中。
4. 爬取图片资源
式神的图标及形象图基本上阴阳师官网都有,自己做也不现实,所以果断写爬虫爬下来然后存到自己的 CDN 上。
所有图片都可以在官方网站上找到。 一开始考虑的是爬取网页、然后 beautiful soup 提取数据,后来,我发现式神数据是异步加载的,那情况就更简单了。
分析网页,我得到直接返回式神信息的 JSON 字段的地址。根据这些,很容易就能写个爬虫来抓取数据。
# coding: utf-8
import json
import requests
import urllib
from xpinyin import Pinyin
url = "https://g37simulator.webapp.163.com/get_heroid_list?callback=jQuery11130959811888616583_1487429691764&rarity=0&page=1&per_page=200&_=1487429691765"
result = requests.get(url).content.replace('jQuery11130959811888616583_1487429691764(', '').replace(')', '')
json_data = json.loads(result)
hellspawn_list = json_data['data']
p = Pinyin()
for k, v in hellspawn_list.iteritems():
file_name = p.get_pinyin(v.get('name'), '')
print 'id: {0} name: {1}'.format(k, v.get('name'))
big_url = "https://yys.res.netease.com/pc/zt/20161108171335/data/shishen_big/{0}.png".format(k)
urllib.urlretrieve(big_url, filename='big/{0}@big.png'.format(file_name))
avatar_url = "https://yys.res.netease.com/pc/gw/20160929201016/data/shishen/{0}.png".format(k)
urllib.urlretrieve(avatar_url, filename='icon/{0}@icon.png'.format(file_name))然而,爬完数据后发现一个问题:网易官方的图片都是无码高清大图。将原图直接放在 CDN 上会使托管费用上升,我不出两天就得破产。
所以,需要批量将图片压缩到既不太大、又能看的过去的程度。嗯,这里就可以用到 PS 的批处理能力了。
- 打开 PS,然后选择爬到的一张图片;
- 选择菜单栏上的「窗口」,然后选择「动作」;
- 在「动作」选项下,新建一个动作;
- 点击圆形录制按钮开始录制动作;
- 按正常处理图片等顺序将一张图片存为 web 格式;
- 点击方形停止按钮停止录制动作;
- 选择菜单栏上的「文件」-「自动」-「批处理」,然后选择之前录制的动作,并配置好输入文件夹和输出文件夹;
- 点击确定就可以啦。
等批处理结束(期间可以刷个御魂啥的,刷完应该就好了),将得到的所有图片上传到静态资源服务器。图片到这里就处理完啦。
5. 式神数据爬取
式神分布数据网上比较杂并且数据很多有偏差,所以斟酌再三,决定采用半人工半自动的方式。
我爬到的数据输出为 JSON:
{
"scene_name": "探索第一章",
"team_list": [{
"name": "天邪鬼绿1",
"index": 1,
"monsters": [{
"name": "天邪鬼绿",
"count": 1
},{
"name": "提灯小僧",
"count": 2
}]
},{
"name": "天邪鬼绿2",
"index": 2,
"monsters": [{
"name": "天邪鬼绿",
"count": 1
},{
"name": "提灯小僧",
"count": 2
}]
},{
"name": "提灯小僧1",
"index": 3,
"monsters": [{
"name": "天邪鬼绿",
"count": 2
},{
"name": "提灯小僧",
"count": 1
}]
},{
"name": "提灯小僧2",
"index": 4,
"monsters": [{
"name": "灯笼鬼",
"count": 2
},{
"name": "提灯小僧",
"count": 1
}]
},{
"name": "首领",
"index": 5,
"monsters": [{
"name": "九命猫",
"count": 3
}]
}]
}然后再人工检查一遍——当然,肯定还是会有遗漏,所以数据报错的功能就很重要啦。
这一部分实际写代码的时间可能只有半个多小时,剩下时间一直在检查数据;
一切检查结束后,直接将 JSON 导入到数据库中。检查无误后,用 Fabric 发布到线上服务器进行测试;
6. 测试
最后一步基本上就是在手机上体验查错,修改一些效果,关闭调试模式准备提交审核;
此时已经是周日——哦,不对——应该是周一早上一点钟了:
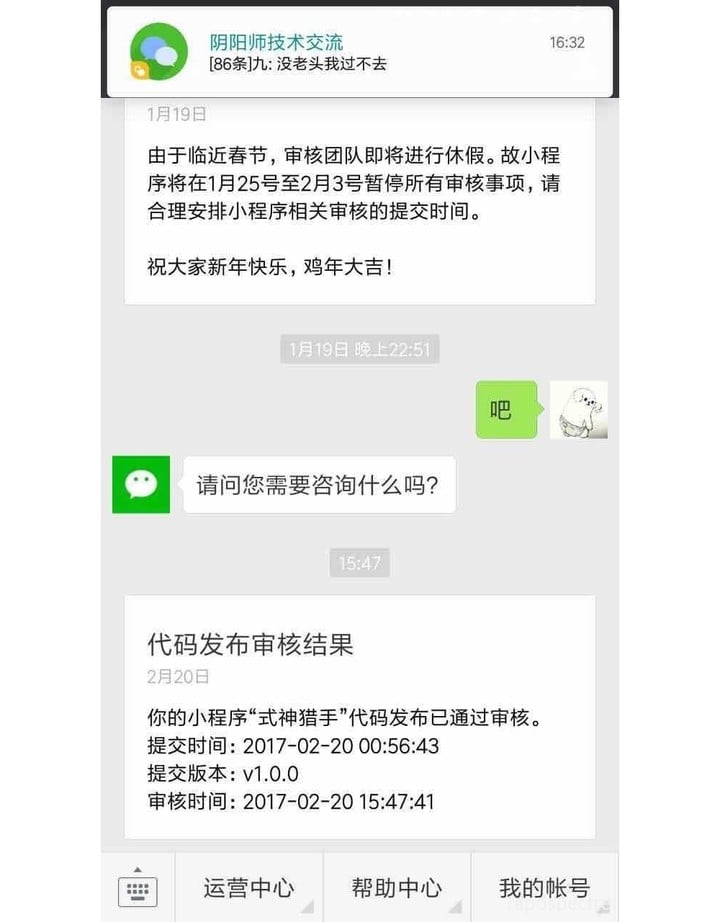
不得不说,小程序团队审核速度很快啊,周一下午就审核通过了,然后果断上线。
以上所有内容均已开源,欢迎大家到我的 GitHub 参考!
原文地址:http://www.jianshu.com/p/89f6eb4aa3e6
作者 GitHub 地址:https://github.com/bluedazzle
往期精选文章
本文由知晓程序授权转载,关注微信号 zxcx0101,可获得以下内容和服务:
- 在微信后台回复「1228」,获取全网第一本《微信小程序入门指南》。
- 在微信后台回复「加群」,加入「一起发现小程序」微信交流群。
- 在微信后台回复任意关键词,还能获得相关小程序推荐,赶紧试试吧!